Evaluate a Smart Answers Query Pipeline
The Smart Answers Evaluate Pipeline job evaluates the rankings of results from any Smart Answers pipeline and finds the best set of weights in the ensemble score. This topic explains how to set up the job.
Before beginning this procedure, prepare a machine learning model using either the Supervised method or the Cold start method, or by selecting one of the pre-trained cold start models, then Configure your pipelines.
The input for this job is a set of test queries and the text or ID of the correct responses. At least 100 entries are needed to obtain useful results. The job compares the test data with Managed Fusion’s actual results and computes variety of the ranking metrics to provide insights of how well the pipeline works. It is also useful to use to compare with other setups or pipelines.
1. Prepare test data
-
Format your test data as query/response pairs, that is, a query and its corresponding answer in each row.
You can do this in any format that Managed Fusion supports, but parquet file would be preferable to reduce the amount of possible encoding issues. The response value can be either the document ID of the correct answer in your Managed Fusion index (preferable), or the text of the correct answer.
If you use answer text instead of an ID, make sure that the answer text in the evaluation file is formatted identically to the answer text in Managed Fusion. If there are multiple possible answers for a unique question, then repeat the questions and put the pair into different rows to make sure each row has exactly one query and one response.
-
If you wish to index test data into Managed Fusion, create a collection for your test data, such as
sa_test_inputand index the test data into that collection.
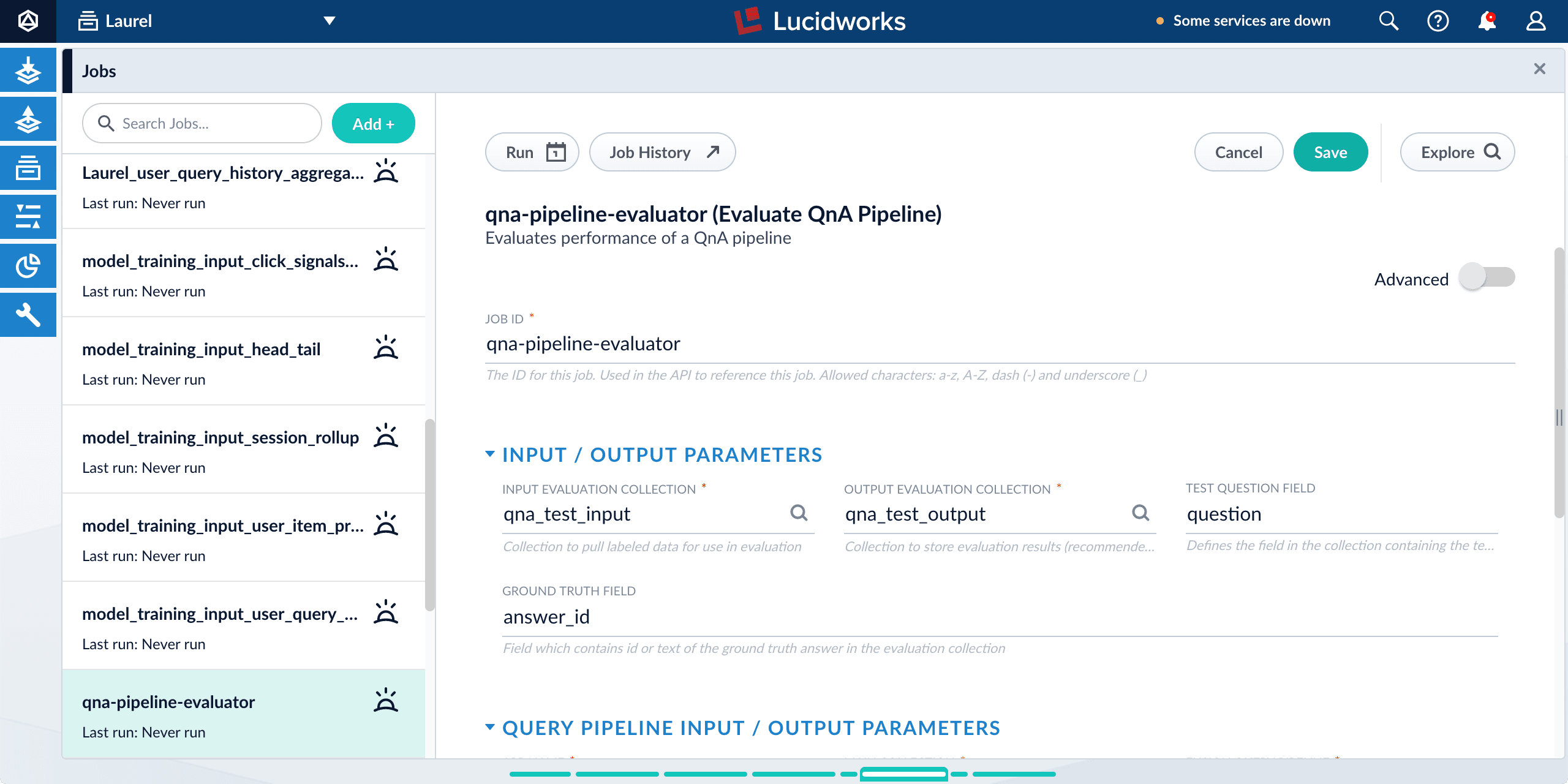
2. Configure the evaluation job
-
If you wish to save the job output in Managed Fusion, create a collection for your evaluation data such as
sa_test_output. -
Navigate to Collections > Jobs.
-
Select New > Smart Answers Evaluate Pipeline.
-
Enter a Job ID, such as
sa-pipeline-evaluator. -
Enter the name of your test data collection (such as
sa_test_input) in the Input Evaluation Collection field. -
Enter the name of your output collection (such as
sa_test_output) in the Output Evaluation Collection field. -
Enter the name of the Test Question Field in the input collection.
-
Enter the name of the answer field as the Ground Truth Field.
-
Enter the App Name of the Managed Fusion app where the main Smart Answers content is indexed.
-
In the Main Collection field, enter the name of the Managed Fusion collection that contains your Smart Answers content.
-
In the Fusion Query Pipeline field, enter the name of the Smart Answers query pipeline you want to evaluate.
-
In the Answer Or ID Field In Fusion field, enter the name of the field that Managed Fusion will return containing the answer text or answer ID.
-
Optionally, you can configure the Return Fields to pass from Smart Answers collection into the evaluation output.
Check the Query Workbench to see which fields are available to be returned. -
Configure the Metrics parameters:
-
Solr Scale Function
Specify the function used in the Compute Mathematical Expression stage of the query pipeline, one of the following: *
max*log10*pow0.5 -
List of Ranking Scores For Ensemble
To find the best weights for different ranking scores, list the names of the ranking score fields, separated by commas. Different ranking scores might include Solr score, query-to-question distance, or query-to-answer distance from the Compute Mathematical Expression pipeline stage.
-
Target Metric To Use For Weight Selection
The target ranking metric to optimize during weights selection. The default is
mrr@3.
-
-
Optionally, read about the advanced parameters and consider whether to configure them as well.
For example, Sampling proportion and Sampling seed provide a way to run the job only on a sample of the test data.
-
Click Save.
-
Click Run > Start.
3. Examine the output
The job provides a variety of metrics (controlled by the Metrics list advanced parameter) at different positions (controlled by the Metrics@k list advanced parameter) for the chosen final ranking score (specified in Ranking score parameter).

In addition to metrics, a results evaluation file is indexed to the specified output evaluation collection. It provides the correct answer position for each test question as well as the top returned results for each field specified in Return fields parameter.