The Trending Recommender job analyzes signals to measure customer engagement over time. Use this job to identify spikes in popularity for specific items or queries, then display those items to your users or analyze the trends for business purposes. You can configure any time window, such as daily, weekly, or monthly.Documentation Index
Fetch the complete documentation index at: https://doc.lucidworks.com/llms.txt
Use this file to discover all available pages before exploring further.
| Input | signals (the COLLECTION_NAME_signals collection by default) |
| Output | Trending items or queries |
| query | count_i | type | timestamp_tdt | user_id | doc_id | session_id | fusion_query_id | |
|---|---|---|---|---|---|---|---|---|
| Required signals fields: | See note below. | ✅ | ✅ | ✅ | ✅ |
Identify Trending Items or Queries
Identify Trending Items or Queries
The Trending Recommender job analyzes signals to measure customer engagement over time. Use this job to identify spikes in popularity for specific items or queries, then display those items to your users or analyze the trends for business purposes. You can configure any time window, such as daily, weekly, or monthly.For complete details about the job’s configuration options, see Trending Recommender Jobs.How to identify trending items or queries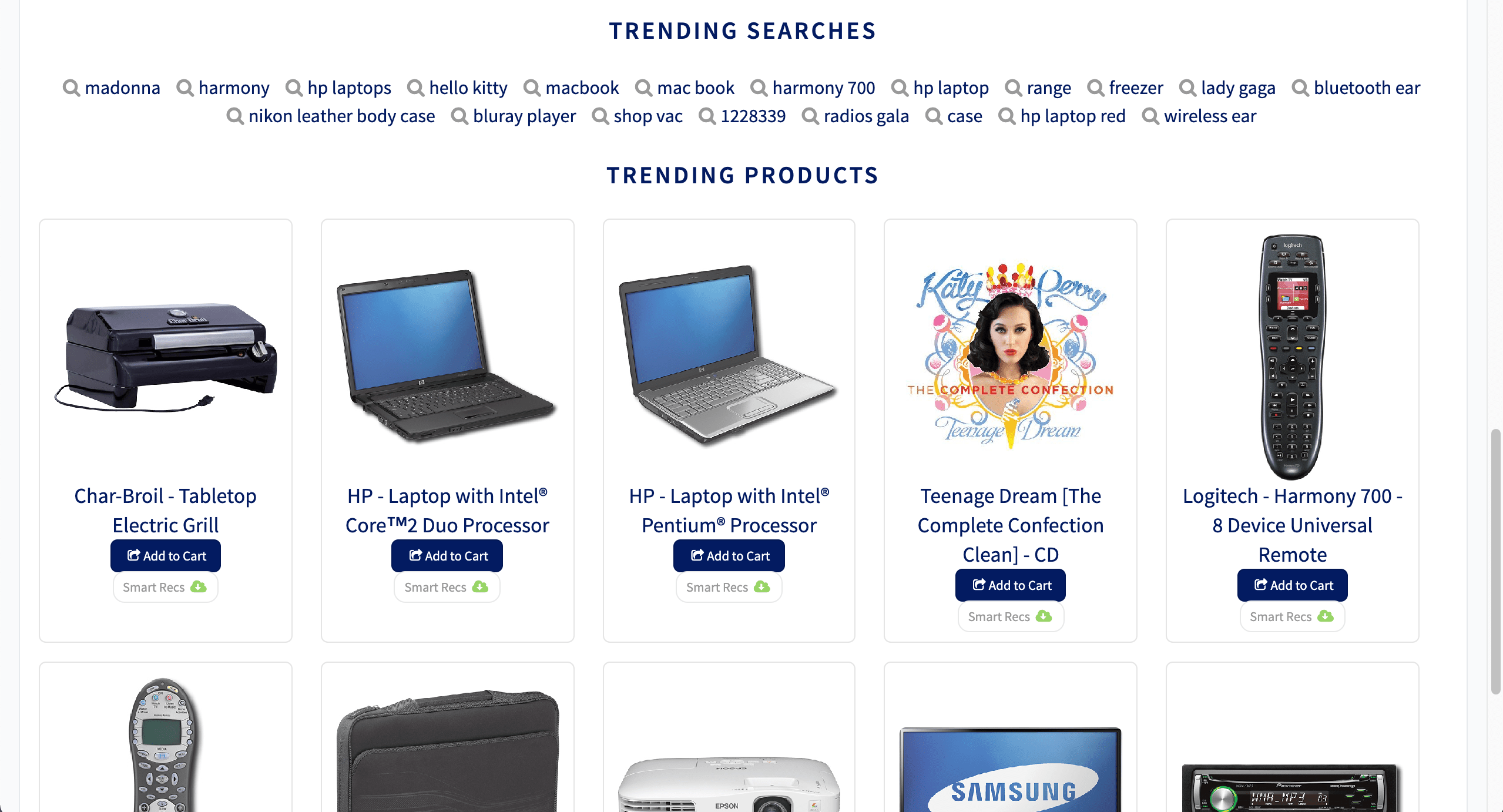
- Navigate to Collections > Jobs > Add + > Trending Recommender.
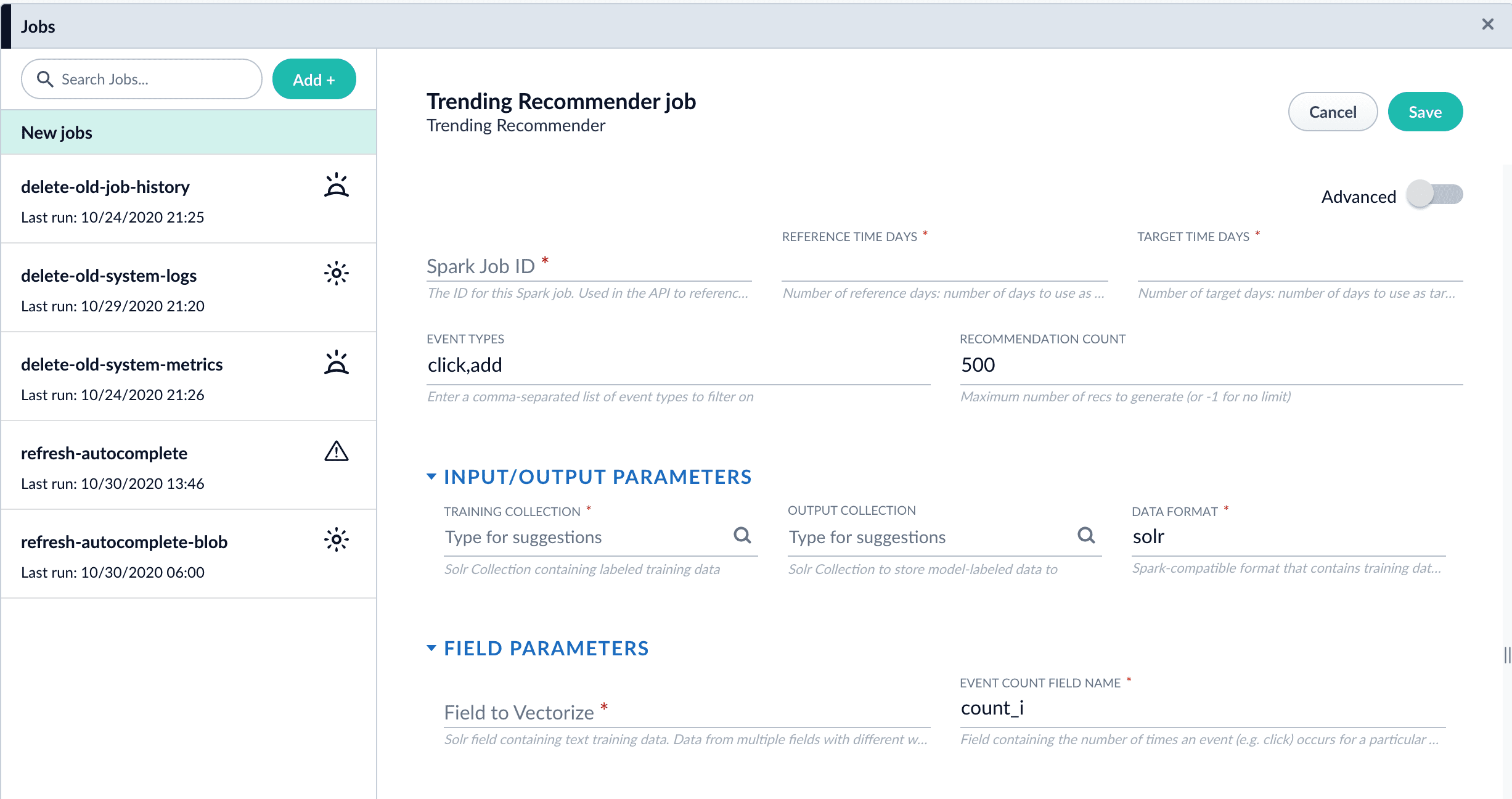
- Configure the job:
- Enter an ID for this job.
- In the Reference Time Days field, enter the number of days to use as a baseline for identifying trends, starting from today.
For example, enter 21 days to analyze three weeks of signals data to use as a baseline. - In the Target Time Days field, enter the number of days to use as a target for identifying trends, starting from today.
For example, enter 7 days to get documents or products whose popularity has spiked in the past week. - If you want to identify trending queries instead of trending items, change the value of the Document ID Field from
doc_id_stoquery_s.This field must be present in your signals. See the required signals fields in the Trending Recommender Jobs reference topic. - In the Training Collection field, enter the Solr collection or cloud path where signals are stored (the
COLLECTION_NAME_signalscollection by default). - In the Output Collection field, enter the Solr collection or cloud path where trend analysis data will be stored.
- If you are using a format other than
solr, enter it in the Data Format field. - In the Solr Fields to Read field, enter one or more field names containing text training data.
- In the Event Count Field Name field, enter the name of the event count field in your training data, usually
count_i.
- Click Save.
- Click Run > Start to run the job. The job outputs documents similar to this example:
- Configure a query pipeline to retrieve trending items from the job’s output collection for display or further analysis. For information about pipelines created when recommendations are enabled, see enable recommendations.