Use Advanced Linguistics with Babel Street
The Fusion Advanced Linguistics Package embeds Babel Street’s (formerly Basistech) Rosette natural language processing tools for multilingual text analysis. To improve search recall, Rosette Base Linguistics (RBL) handles the unique linguistic phenomena of more than 30 Asian and European languages. Rosette Entity Extractor (REX) identifies named entities such as people, locations, and organizations, allowing you to quickly refine your search, remove noise, and increase search relevance.
Using Named Entities (REX)
REX extracts named entities in multiple languages, including English, Chinese (traditional and simplified), and German. In English, it extracts multiple entity types and subtypes. This includes the following entity types (along with their associated subtypes):
-
PERSON -
LOCATION -
ORGANIZATION -
PRODUCT -
TITLE -
NATIONALITY -
RELIGION
In this tutorial, we will extract named entities from English news articles.
Create Application
To begin, create a new application called "entities".
Configuration
Edit Solr Configuration
We will begin by adding the Basis library elements to the solrconfig.xml file. We will also add a new update processor to perform the entity extraction.
-
Navigate to System > Solr Config to edit the
solrconfig.xmlfile. -
Fusion 5.8 and earlier: In the
<lib/>directive section, add the lines below. Fusion 5.9 and later already contain these lines.<lib dir="/opt/basistech/rex-je/lib" regex=".*\.jar" /> <lib dir="/opt/basistech/solr/lib/" regex=".*\.jar" />For Fusion 4.x users, the dirpaths are the local REX installation path. -
In the
<updateRequestProcessorChain/>section, add the following lines after the existing processor chains:<updateRequestProcessorChain name="rex"> <processor class="com.basistech.rosette.solr.EntityExtractorUpdateProcessorFactory"> <str name="rootDirectory">/opt/basistech/rex-je</str> <str name="fields">text_eng</str> </processor> <processor class="solr.LogUpdateProcessorFactory"/> <processor class="solr.RunUpdateProcessorFactory"/> </updateRequestProcessorChain>Note the reference to a field called
text_eng. We will create this field through the Fusion UI in the next step. -
Save your changes to
solrconfig.xml.
Define Fields
The data file we will use, eng_docs.csv, contains two fields:
-
title. An article headline -
article_text. The text content of the article
We will index these two static fields and also define a set of dynamic fields to hold the extracted entities. To create new fields, navigate to Collections > Fields and click Add a Field. Create the following fields:
| Field name | Field type | Other options |
|---|---|---|
|
|
Use default options. |
|
|
Use default options. |
|
|
Create this field as a dynamic field by clicking the Dynamic checkbox. Click the Multivalued checkbox. Leave other options as defaults. |
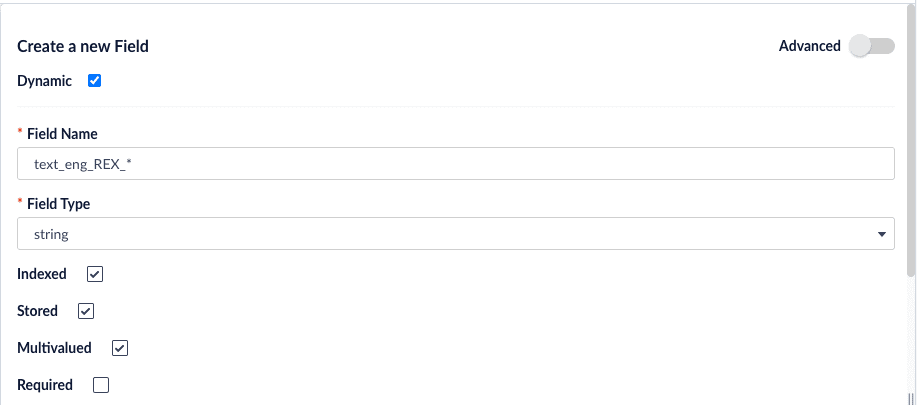
| Be sure to save each field after creating it. |
Indexing Data
Create Indexing Pipeline
-
Navigate to Indexing > Indexing Pipelines.
-
Click Add and create a new pipeline called
test-entities. -
Select the Field Mapping stage.
-
In the Field Translations section, add a new row with source
article_textand targettext_eng. Set the Operation tomove.
The CSV file we will upload contains a field title, but since this matches the title field that we created earlier, there is no need to map it. Leave the Unmapped Fields section with its default option, keep.
-
Select the Solr Indexer stage.
-
In the Additional Update Request Parameters section, add a new row with parameter name
update.chainand valuerex.
-
Save the new pipeline.
Create Datasource
In this step, we will upload and index our documents from the data file.
-
Navigate to Indexing > Datasources.
-
Click Add and select File Upload V2 from the dropdown menu.
-
Enter
eng_docsfor the Datasource ID. Alternatively, use a name you prefer. -
Select
test-entitiesfor the Pipeline ID. -
In the File Upload field, choose the sample file
eng_docs.csvand click Upload File.The File ID field will be automatically populated. Leave all other values as their defaults.
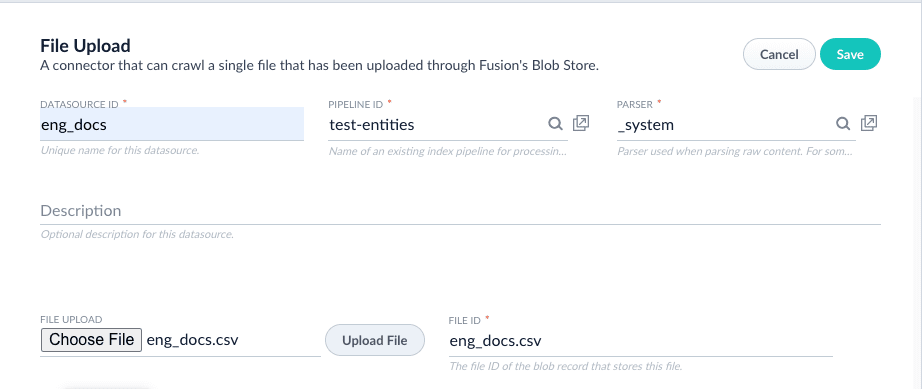
-
Save the new datasource. The form will refresh, adding a set of buttons at the top.
-
Click Run and then Start. When the job is finished, you will see "Success" in the popup form.
Querying Data
-
Navigate to Querying > Query Workbench. The default query is
*:*, which should bring up three documents. -
For the document with title "SpaceX Successfully Launches its First Crewed Spaceflight", select Show fields. You will see a number of entities listed under the
text_eng_REX_*fieldnames.
-
Search on these multivalued fields. For example, set your query to
text_eng_REX_LOCATION:"New York"to return the article that contains a mention of New York.
Customization (Advanced)
When setting up the Solr configuration, you specified the rootDirectory and fields options in your processor chain. REX provides a number of other configuration options you can set to control how entities are extracted. For example, if you are finding false positives, you can set parameters instructing REX to return only entities above a confidence threshold. The confidence threshold is a value between 0 and 1 and applies to entities extracted by the statistical model. We recommend starting with a low value, around 0.2. In your solrconfig.xml file, add the options calculateConfidence and confidenceThreshold to your processor chain definition:
<updateRequestProcessorChain name="rex">
<processor class="com.basistech.rosette.solr.EntityExtractorUpdateProcessorFactory">
<str name="rootDirectory">/opt/basistech/rex-je</str>
<str name="fields">text_eng</str>
<str name="calculateConfidence">True</str>
<str name="confidenceThreshold">0.2</str>
</processor>
<processor class="solr.LogUpdateProcessorFactory"/>
<processor class="solr.RunUpdateProcessorFactory"/>
</updateRequestProcessorChain>Save the changes, re-index your data, and perform the same query on *:*. Note that for the SpaceX article, "Falcon", is now correctly omitted from the list of LOCATIONs.

If there is a particular entity you want to make sure is extracted or rejected, or if you wish to create a custom entity type, REX also supports gazetteers and regular expressions.
Gazetteers
A gazetteer is a UTF-8 text file in which the first line is the entity type. It is followed by the names of entities you wish to extract, separated by newlines, in the language of your documents. Comments can be prefixed by the # symbol. Create a file spacecraft_gaz.txt with the following lines:
SPACECRAFT
ISS
International Space Station
Vostok
Soyuz
Dragon
Crew Dragon
Cargo Dragon
Voyager
ApolloRegular expressions
REX uses the Tcl regex format. Create a file, zulu_time_regex.xml, file with the following lines:
<regexps>
<regexp lang="eng" type="ZULU_TIME">(?i)\m(?:[01]?\d|2[0-4])(?:[0-5]\d) (?:UTC|GMT)</regexp>
</regexps>This regular expression will extract as entity type ZULU_TIME all spans that consist of a 4-digit military time unit followed by the time zone designator UTC or GMT.
Example
To instruct REX to use the gazetteer and regex file, edit your solrconfig.xml file. The addGazetteers option takes four parameters:
-
language
-
file
-
accept (
True) or reject (False) -
case-sensitive (
TrueorFalse)
For example, with <str name="addGazetteers">eng,/path/to/spacecraft_gaz.txt,True,True</str>:
| language | file | accept | case-sensitive |
|---|---|---|---|
|
|
|
|
The addRegularExpressions option takes two parameters:
-
file
-
accept (
True) or reject (False)
For example, with <str name="addRegularExpressions">/path/to/zulu_time_regex.xml,True</str>:
| file | accept |
|---|---|
|
|
The result in the solrconfig.xml file:
<updateRequestProcessorChain name="rex">
<processor class="com.basistech.rosette.solr.EntityExtractorUpdateProcessorFactory">
<str name="rootDirectory">/opt/basistech/rex-je</str>
<str name="fields">text_eng</str>
<str name="calculateConfidence">True</str>
<str name="confidenceThreshold">0.2</str>
<str name="addGazetteers">eng,/path/to/spacecraft_gaz.txt,True,True</str>
<str name="addRegularExpressions">/path/to/zulu_time_regex.xml,True</str>
</processor>
<processor class="solr.LogUpdateProcessorFactory"/>
<processor class="solr.RunUpdateProcessorFactory"/>
</updateRequestProcessorChain>Now, when you re-index your data and search *:*, the SpaceX document will have new entities listed in the text_eng_REX_SPACECRAFT and text_eng_REX_ZULU_TIME dynamic fields.
| Additional Fusion deployment configurations are needed to use the REX gazetteer and regex options. |
Using Multilingual Search (RBL)
RBL provides a set of linguistic tools to prepare your data for analysis. Language-specific models provide base forms (lemmas) of words, parts-of-speech tagging, compound components, normalized tokens, stems, and roots.
In this tutorial, we will index and query headlines in English, Chinese, and German to demonstrate the linguistics capabilities of RBL: lemmatization, tokenization, and decompounding.
Create Application
To begin, create a new application called "multilingual".
Configuration
Edit Solr Configuration
We will begin by adding the Basis library elements to the solrconfig.xml file.
-
Navigate to System > Solr Config to edit the
solrconfig.xmlfile. -
In the
<lib/>directive section, add the following lines:<lib dir="/opt/basistech/solr/lib/" regex=".*\.jar" />For Fusion 4.x users, the dirpath is the local REX installation path. -
Save your changes to
solrconfig.xml.
Edit Schema
Add a fieldType element for each language to be processed by the application. The fieldType element includes two analyzers: one for indexing documents and one for querying documents. Each analyzer contains a tokenizer and a token filter. The language attribute is set to the language code, equal to the ISO 639-3 code in most cases. The rootDirectory points to the RBL directory.
-
Navigate to System > Solr Config to edit the managed-schema file.
-
In the fieldType section, add the following new field types:
basis_english,basis_chinese, andbasis_german.<fieldtype class="solr.TextField" name="basis_english"> <analyzer type="index"> <tokenizer class="com.basistech.rosette.lucene.BaseLinguisticsTokenizerFactory" language="eng" rootDirectory="/opt/basistech/rbl-je"/> <filter class="com.basistech.rosette.lucene.BaseLinguisticsTokenFilterFactory" language="eng" rootDirectory="/opt/basistech/rbl-je"/> </analyzer> <analyzer type="query"> <tokenizer class="com.basistech.rosette.lucene.BaseLinguisticsTokenizerFactory" language="eng" query="true" rootDirectory="/opt/basistech/rbl-je"/> <filter class="com.basistech.rosette.lucene.BaseLinguisticsTokenFilterFactory" language="eng" query="true" rootDirectory="/opt/basistech/rbl-je"/> </analyzer> </fieldtype> <fieldtype class="solr.TextField" name="basis_chinese"> <analyzer type="index"> <tokenizer class="com.basistech.rosette.lucene.BaseLinguisticsTokenizerFactory" language="zho" rootDirectory="/opt/basistech/rbl-je"/> <filter class="com.basistech.rosette.lucene.BaseLinguisticsTokenFilterFactory" language="zho" rootDirectory="/opt/basistech/rbl-je"/> </analyzer> <analyzer type="query"> <tokenizer class="com.basistech.rosette.lucene.BaseLinguisticsTokenizerFactory" language="zho" query="true" rootDirectory="/opt/basistech/rbl-je"/> <filter class="com.basistech.rosette.lucene.BaseLinguisticsTokenFilterFactory" language="zho" query="true" rootDirectory="/opt/basistech/rbl-je"/> </analyzer> </fieldtype> <fieldtype class="solr.TextField" name="basis_german"> <analyzer type="index"> <tokenizer class="com.basistech.rosette.lucene.BaseLinguisticsTokenizerFactory" language="deu" rootDirectory="/opt/basistech/rbl-je"/> <filter class="com.basistech.rosette.lucene.BaseLinguisticsTokenFilterFactory" language="deu" rootDirectory="/opt/basistech/rbl-je"/> </analyzer> <analyzer type="query"> <tokenizer class="com.basistech.rosette.lucene.BaseLinguisticsTokenizerFactory" language="deu" query="true" rootDirectory="/opt/basistech/rbl-je"/> <filter class="com.basistech.rosette.lucene.BaseLinguisticsTokenFilterFactory" language="deu" query="true" rootDirectory="/opt/basistech/rbl-je"/> </analyzer> </fieldtype>
| You can incorporate any additional Solr filters you need, such as the Solr lowercase filter. However, filters should be added into the chain after the Base Linguistics token filter. If you modify the token stream too significantly before RBL, you degrade its ability to analyze the text. |
-
Save your changes to managed-schema.
Define Fields
The data file we will use, multilingual_headlines.csv, contains fields for headlines in three languages: eng_headline, zho_headline, and deu_headline. The analysis chain requires a field definition with a type attribute that maps to the fieldType you defined in the schema.
To create new fields, navigate to Collections > Fields and click Add a Field. Create the following fields:
| Field name | Field type | Other options |
|---|---|---|
|
|
Use default options. |
|
|
Use default options. |
|
|
Use default options. |
| Be sure to save each field after creating it. |
Indexing Data
Create Indexing Pipeline
-
Navigate to Indexing > Indexing Pipelines.
-
Click Add and create a new pipeline called
test-multilingual. -
Select the Field Mapping stage.
-
In the Field Translations section, add three new rows:
Field name Field name Operation eng_headlinetext_engmovezho_headlinetext_zhomovedeu_headlinetext_deumove -
Save the new pipeline.
Create Datasource
In this step, we will upload and index our documents from the data file.
-
Navigate to Indexing > Datasources.
-
Click Add and select File Upload from the dropdown menu.
-
Enter
multilingual_headlinesfor the Datasource ID. Alternatively, use a name you prefer. -
Select
test-multilingualfor the Pipeline ID. -
In the File Upload field, choose the sample file
multilingual_headlines.csvand click Upload File.The File ID field will be automatically populated. Leave all other values as their defaults.
-
Save the new datasource. The form will refresh, adding a set of buttons at the top.
-
Click Run and then Start. When the job is finished, you will see "Success" in the popup form.
Querying Data
-
Navigate to Querying > Query Workbench. The default query is
*:*, which should bring up ten documents. -
Follow the examples in the subsections below to see how Fusion’s Advanced Linguistics capabilities can improve your search results.
Lemmatization
A "lemma" is the canonical form of a word, or the version of a word that you find in the dictionary. For example, the lemma of "mice" is "mouse". The words "speaks", "speaking", "spoke", and "spoken" all share the same lemma: "speak".
With RBL, you can perform searches by lemma, thus increasing your search results. This example demonstrates this practice with the words "knife" and "knives" below.
-
For ease of viewing results, select the Display Fields dropdown and enter
text_engin the Description field. -
Enter the query
text_eng:knifein the search box.
Two documents are returned. One of the headlines, "Iowa City Man Arrested After Alleged Altercation with a Knife", is an exact match on the query term knife. With a standard Solr text field type, this would be the only result returned. However, the special type basis_english we configured allows the search engine to recognize "knives" as a form of "knife". Therefore, the article "The Best Ways to Sharpen Kitchen Knives at Home" is also returned.
RBL can significantly reduce your dependence on creating, maintaining, and using large synonym lists.
Tokenization
Tokenization is the process of separating a piece of text into smaller units called "tokens". Tokens can be words, characters, or subwords, depending on how they are defined and analyzed. The RBL tokenizer first determines sentence boundaries, then segments each sentence into individual tokens. The most useful tokens are often words, though they may also be numbers or other characters.
In some languages like Chinese and Japanese, word tokens are not separated by whitespace, and words can consist of one, two, or more characters. For example, the tokens in 我喜歡貓 (I like cats) are 我 (I), 喜歡 (like), and 貓 (cats). RBL uses statistical models to identify token boundaries, allowing for more accurate search results.
-
For ease of viewing results, select the Display Fields dropdown and enter
text_zhoin the Description field. -
Enter the query
text_zho:美國(United States) in the search box.
The document "美國男子染疫無呼吸道症狀但難以說話行走" ("U.S. Man has no Respiratory Symptoms but has Difficulty Talking and Walking") is returned, as 美國 (United States) is a token in the headline.
With a standard Solr text field type, this headline would be naively tokenized with one character per token. Therefore, a search for 美 (beautiful) would trigger a false positive match, even though it is not a word in this context. However, with the advanced analytics we have configured here, the query text_zho:美 will correctly return zero results.
Compounds
RBL can decompose Chinese, Danish, Dutch, German, Hungarian, Japanese, Korean, Norwegian, and Swedish compounds, returning the lemmas of each of the components. The lemmas may differ from their surface form in the compound, such that the concatenation of the components is not the same as the original compound (or its lemma). Components are often connected by elements that are present only in the compound form. RBL allows Solr to index and query on these components, increasing recall of search results.
-
For ease of viewing results, select the Display Fields dropdown and enter
text_deuin the Description field. -
Enter the query
text_deu:Landin the search box.
The result "Mitarbeiter sitzen in ihren Heimatländern fest" ("Employees are Stuck in Their Home Countries") returned.
This headline contains the compound "Heimatländern" (home countries). A search on Land (country) with a standard Solr text field type would not trigger a match. However, because RBL performs decompounding with lemmatization, searching on Heimat or Land will return a result.
Customization (Advanced)
When setting up the Solr configuration, you specified the language and rootDirectory options in your field type definition. This is sufficient for most use cases. However, RBL does provide more options to control the behavior of the tokenizer and analyzer. For example, the default tokenization does not consider URLs. As a result, https://lucidworks.com is tokenized as https, lucidworks, and com.
If you wish to recognize URLs, you can add the option urls="true" to the tokenizer in your field type definition:
<fieldtype class="solr.TextField" name="basis_english">
<analyzer type="index">
<tokenizer class="com.basistech.rosette.lucene.BaseLinguisticsTokenizerFactory" language="eng" rootDirectory="/opt/basistech/rbl-je" urls="true"/>
<filter class="com.basistech.rosette.lucene.BaseLinguisticsTokenFilterFactory" language="eng" rootDirectory="/opt/basistech/rbl-je"/>
</analyzer>
<analyzer type="query">
<tokenizer class="com.basistech.rosette.lucene.BaseLinguisticsTokenizerFactory" language="eng" query="true" rootDirectory="/opt/basistech/rbl-je" urls="true"/>
<filter class="com.basistech.rosette.lucene.BaseLinguisticsTokenFilterFactory" language="eng" query="true" rootDirectory="/opt/basistech/rbl-je"/>
</analyzer>
</fieldtype>This will instruct RBL to consider URLs as a single token, for example: https://lucidworks.com.
To see a list of all options, consult the full RBL documentation.