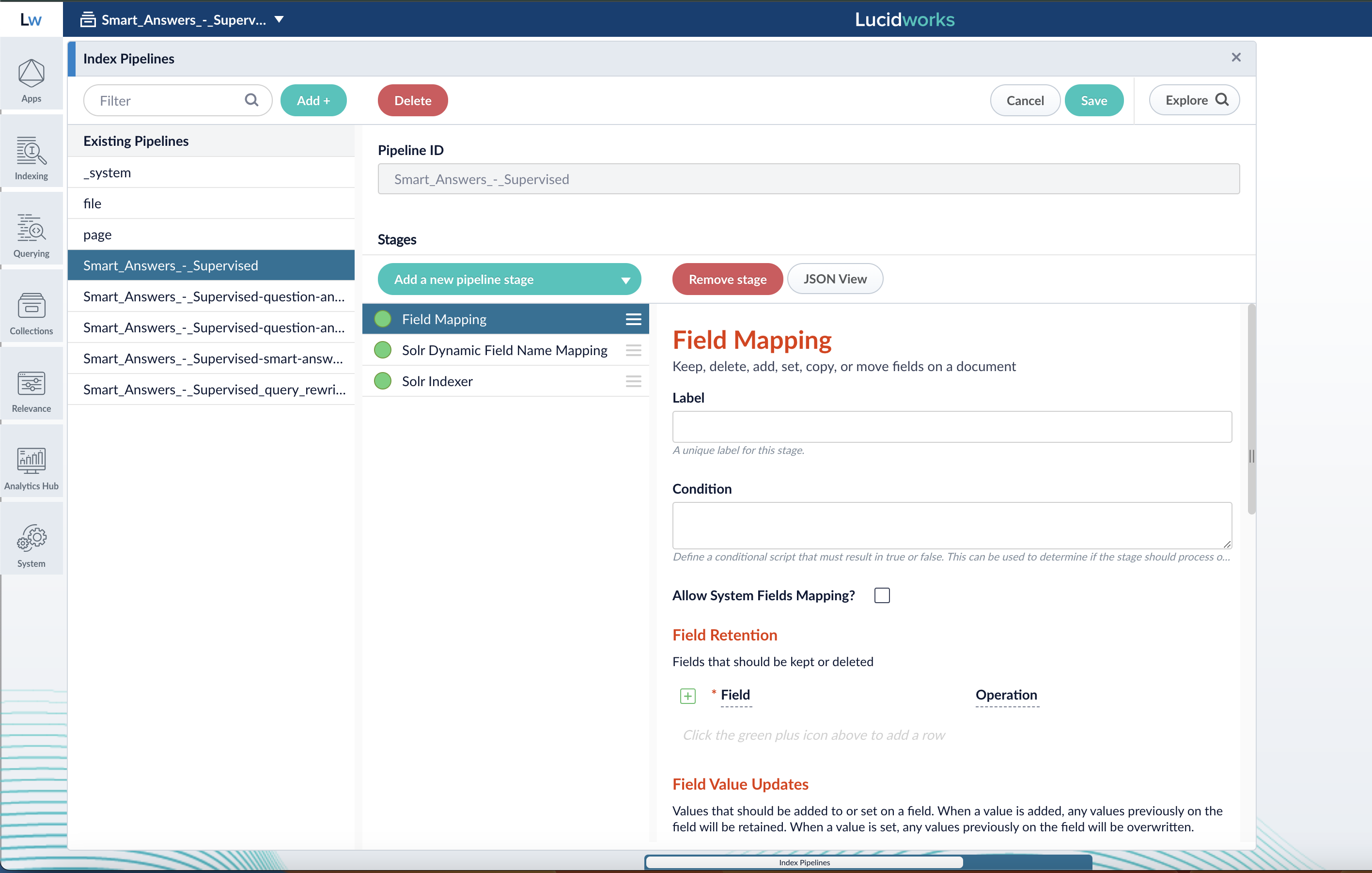
Index Pipeline Stages
An Index Pipeline takes content and transforms it into a document suitable for indexing by Solr via a series of modular operations called stages. The objects sent from stage to stage are PipelineDocument objects. Fusion provides many specialized index stages as well as a JavaScript Index stage that allows for custom processing via a JavaScript program. The general outline of the Extract/Transform/Load processing performed by an index pipeline is:
-
Raw content is parsed into one or more PipelineDocument objects.
-
Any number of intermediate stages operate on the document fields directly, or, in the case of specialized NLP tools, add annotations to a document.
-
Finally, the PipelineDocument is sent to Solr for indexing.
A pipeline stage definition associates a unique ID with a set of properties. Pipeline definitions are stored in ZooKeeper for reuse across pipelines and search applications. The Fusion UI provides stage-specific panels used to define and configure each pipeline stage. Alternatively, JSON can be used to specify the sequence of pipeline stages and registered via the Fusion REST API. Some stages require additional resources, e.g., text files that contain lists of names, synonyms, places, or binary files which NLP language models. These resources can be uploaded via the Fusion UI or the REST API.
| The Index Pipeline Stages Reference section contains articles that detail the configuration for each of the Fusion index pipeline stages. The configuration information includes field names and values, as well as examples and other key reference information. |
Pipeline stage JSON editor
The pipeline stage JSON editor gives the ability to create and copy pipeline stages by pasting JSON objects in the Fusion UI. Only JSON is supported, and JSON validation is included to prevent the user from saving an invalid object.
Navigate to your pipelines, select a pipeline stage, and click the JSON View button to open the editor:

Existing stages are considered READ-ONLY. They will have only a copy button which can be used to create stages. New stages will have the option to copy or paste valid JSON. Changes are applied to the stage with the Apply button.
| Users will still need to Save the stage for the changes made in the editor to be saved. |
The editor has several elements worth noting:
| Elements | Description |
|---|---|
|
Copies the JSON to the clipboard. |
|
Pastes the clipboard into the editor. Only valid JSON is accepted. |
|
Expands the editor to a fullscreen view. |
|
Condenses the editor to a compact view. |
|
Applies the JSON in the editor and updates the stage. The stage must be saved to preserve the changes. |
|
Resets changes made since the last time changes were applied. |
For instructions, see Use the Pipeline Stage JSON Editor.
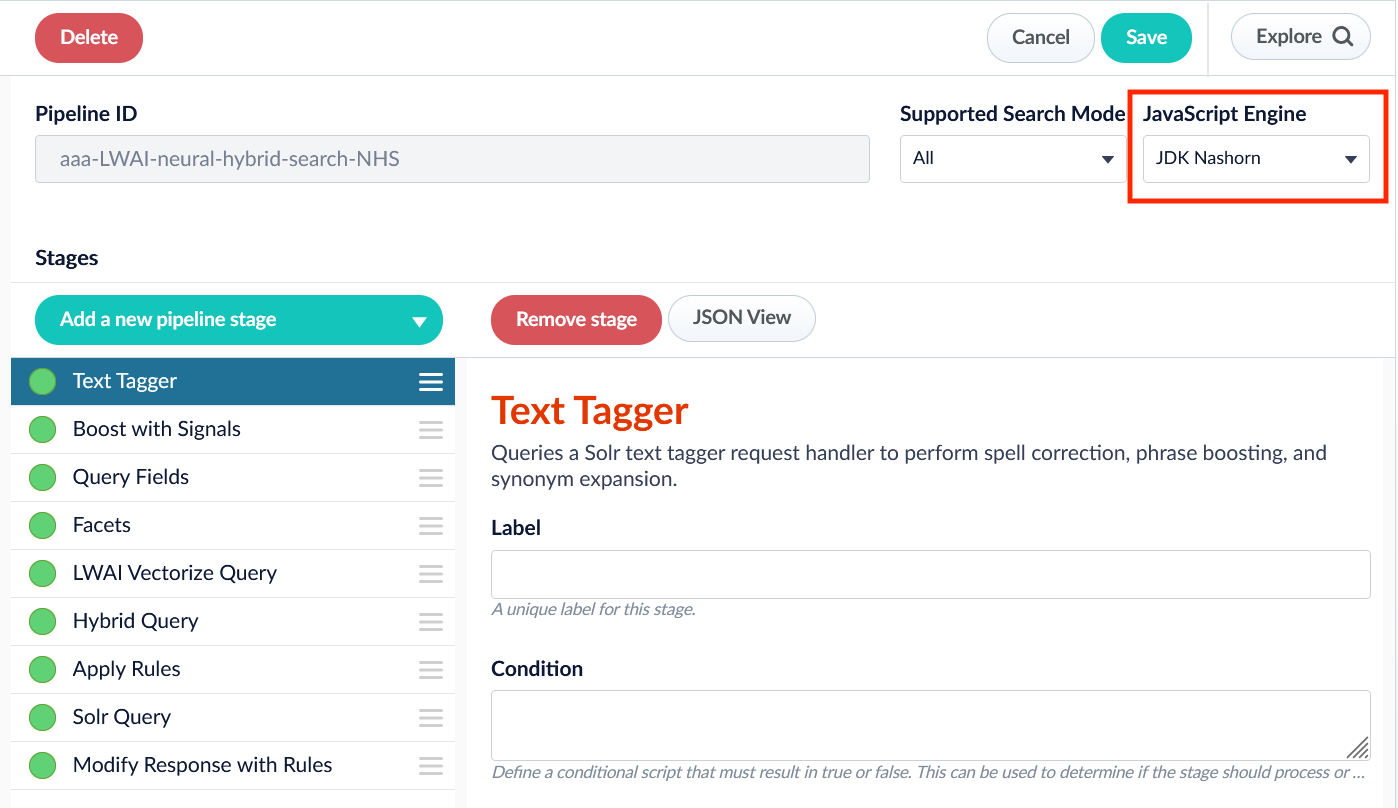
JavaScript selector
Now your pipeline definitions can include your choice of JavaScript engine, either Nashorn or OpenJDK Nashorn. While Nashorn is the default option, it is in the process of being deprecated and will eventually be removed, so it is recommended to use OpenJDK Nashorn when possible. You can select the JavaScript engine in the pipeline views or in the workbenches. Your JavaScript pipeline stages are interpreted by the selected engine.
|
Lucidworks offers free training to help you get started. The Quick Learning for Top 3 Index Pipeline Stages focuses on useful indexing stages:
Visit the LucidAcademy to see the full training catalog. |