Documentation Index
Fetch the complete documentation index at: https://doc.lucidworks.com/llms.txt
Use this file to discover all available pages before exploring further.
This feature is available starting in Fusion 5.9.11 and in all subsequent Fusion 5.9 releases.
Use Tika Asynchronous Parsing
Use Tika Asynchronous Parsing
This document describes how to set up your application to use Tika asynchronous parsing.Unlike synchronous Tika parsing, which uses a parser stage, asynchronous Tika parsing is configured in the datasource and index pipeline. For more information, see Asynchronous Tika Parsing.
Field names change with asynchronous Tika parsing.In contrast to synchronous parsing, asynchronous Tika parsing prepends
parser_ to fields added to a document. System fields, which start with \_lw_, are not prepended with parser_. If you are migrating to asynchronous Tika parsing, and your search application configuration relies on specific field names, update your search application to use the new fields.Configure the connectors datasource
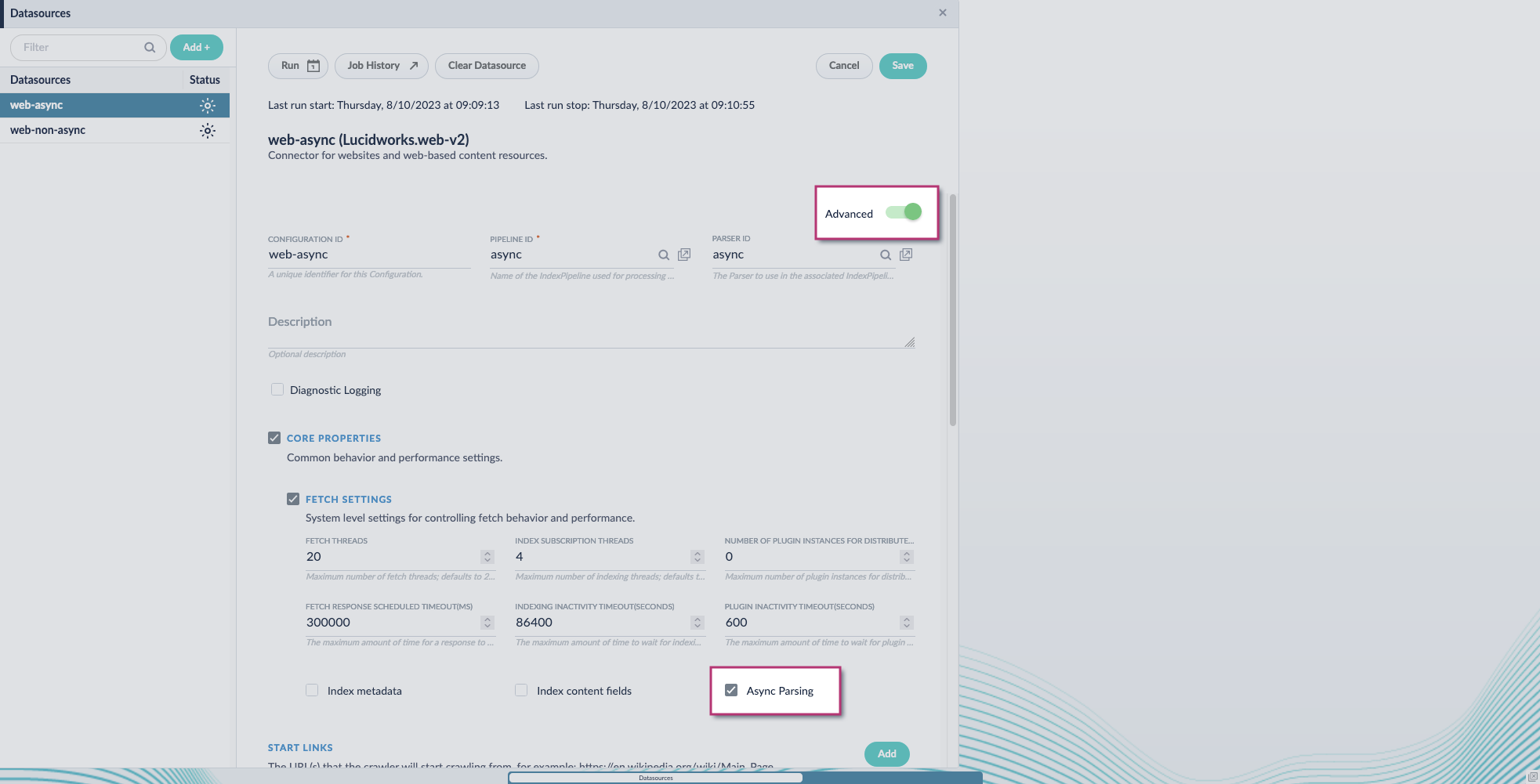
- Navigate to your datasource.
- Enable the Advanced view.
-
Enable the Async Parsing option.
 Fusion 5.9.11 and later uses your parser configuration when using asynchronous parsing.The asynchronous parsing service performs Tika parsing using Apache Tika Server. In Fusion 5.8 through 5.9.10, other parsers, such as HTML and JSON, are not supported by the asynchronous parsing service. By enabling asynchronous parsing, the parser configuration linked to your datasource is ignored. In Fusion 5.9.11 and later, other parsers, such as HTML and JSON, are supported by the asynchronous parsing service. By enabling asynchronous parsing, the parser configuration linked to your datasource is used.
Fusion 5.9.11 and later uses your parser configuration when using asynchronous parsing.The asynchronous parsing service performs Tika parsing using Apache Tika Server. In Fusion 5.8 through 5.9.10, other parsers, such as HTML and JSON, are not supported by the asynchronous parsing service. By enabling asynchronous parsing, the parser configuration linked to your datasource is ignored. In Fusion 5.9.11 and later, other parsers, such as HTML and JSON, are supported by the asynchronous parsing service. By enabling asynchronous parsing, the parser configuration linked to your datasource is used. - Save the datasource configuration.
Configure the parser stage
You must do this step in Fusion 5.9.11 and later.
- Navigate to Parsers.
- Select the parser, or create a new parser.
- From the Add a parser stage menu, select Apache Tika Container Parser.
- (Optional) Enter a label for this stage. This label changes the names from Apache Tika Container Parser to the value you enter in this field.
- If the Apache Tika Container Parser stage is not already the first stage, drag and drop the stage to the top of the stage list so it is the first stage that runs.
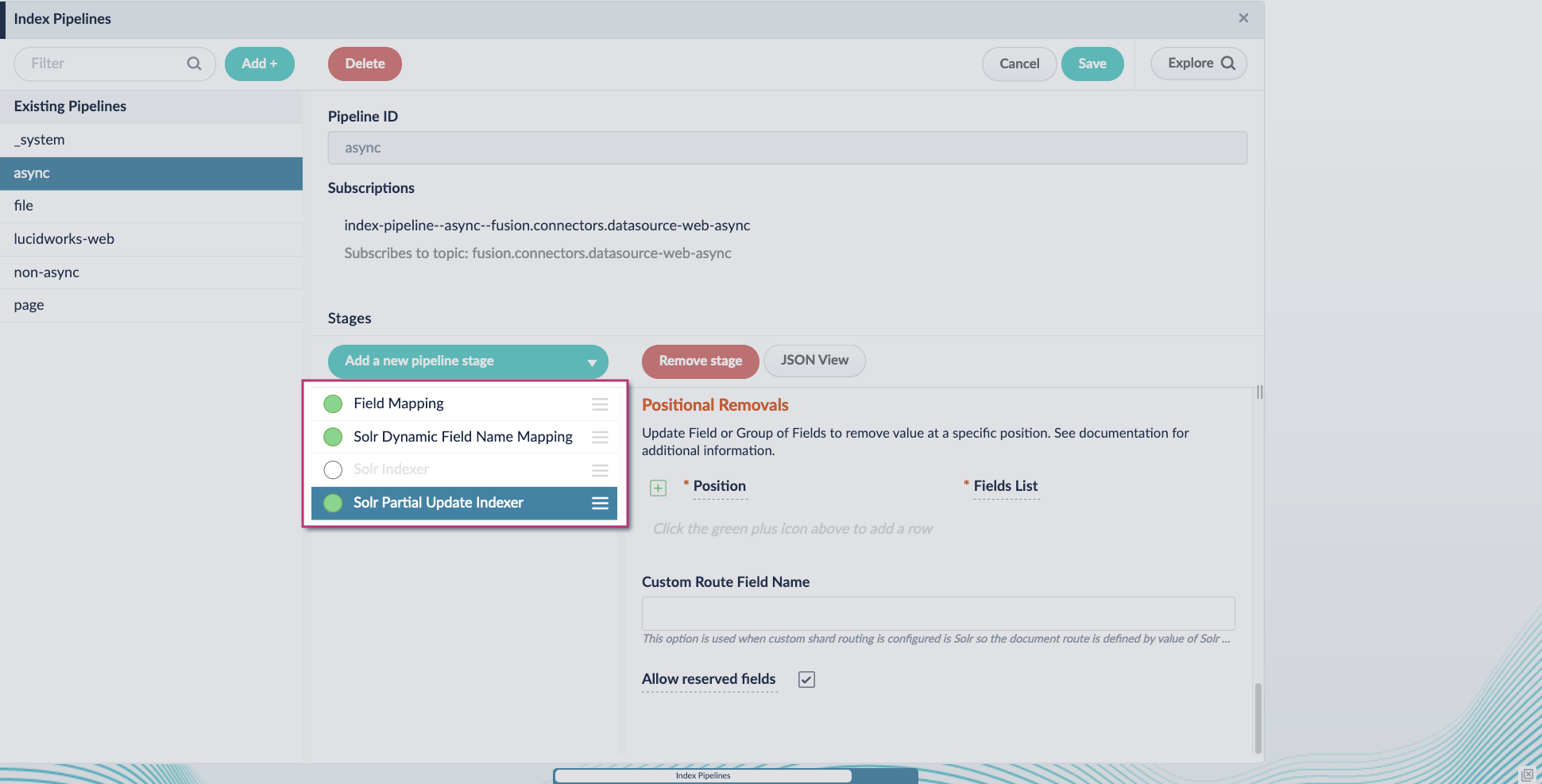
Configure the index pipeline
- Go to the Index Pipeline screen.
- Add the Solr Partial Update Indexer stage.
-
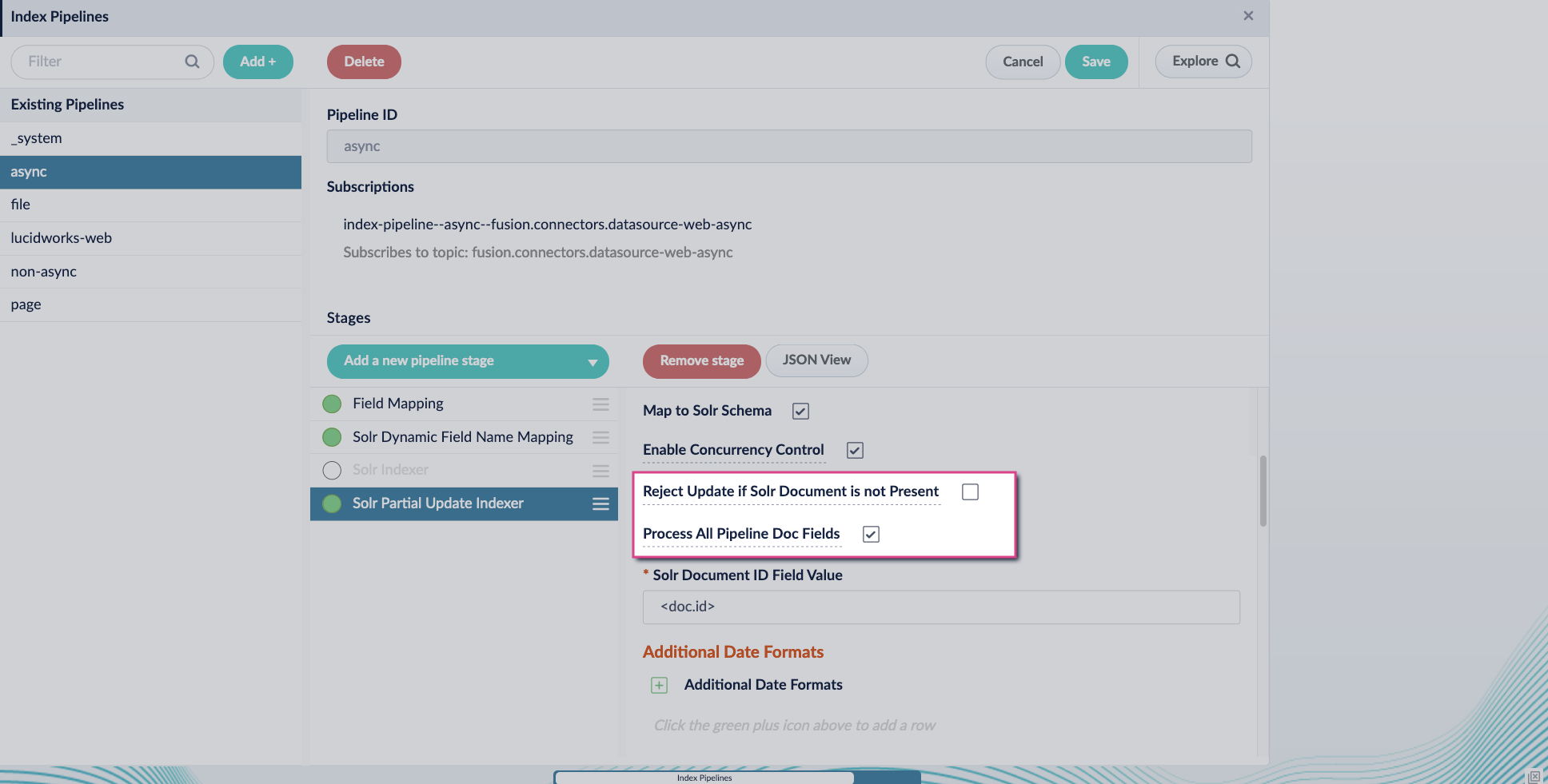
Turn off the Reject Update if Solr Document is not Present option and turn on the Process All Pipeline Doc Fields option:
-
Include an extra update field in the stage configuration using any update type and field name. In this example, an incremental field
docs_counter_iwith an increment value of1is added: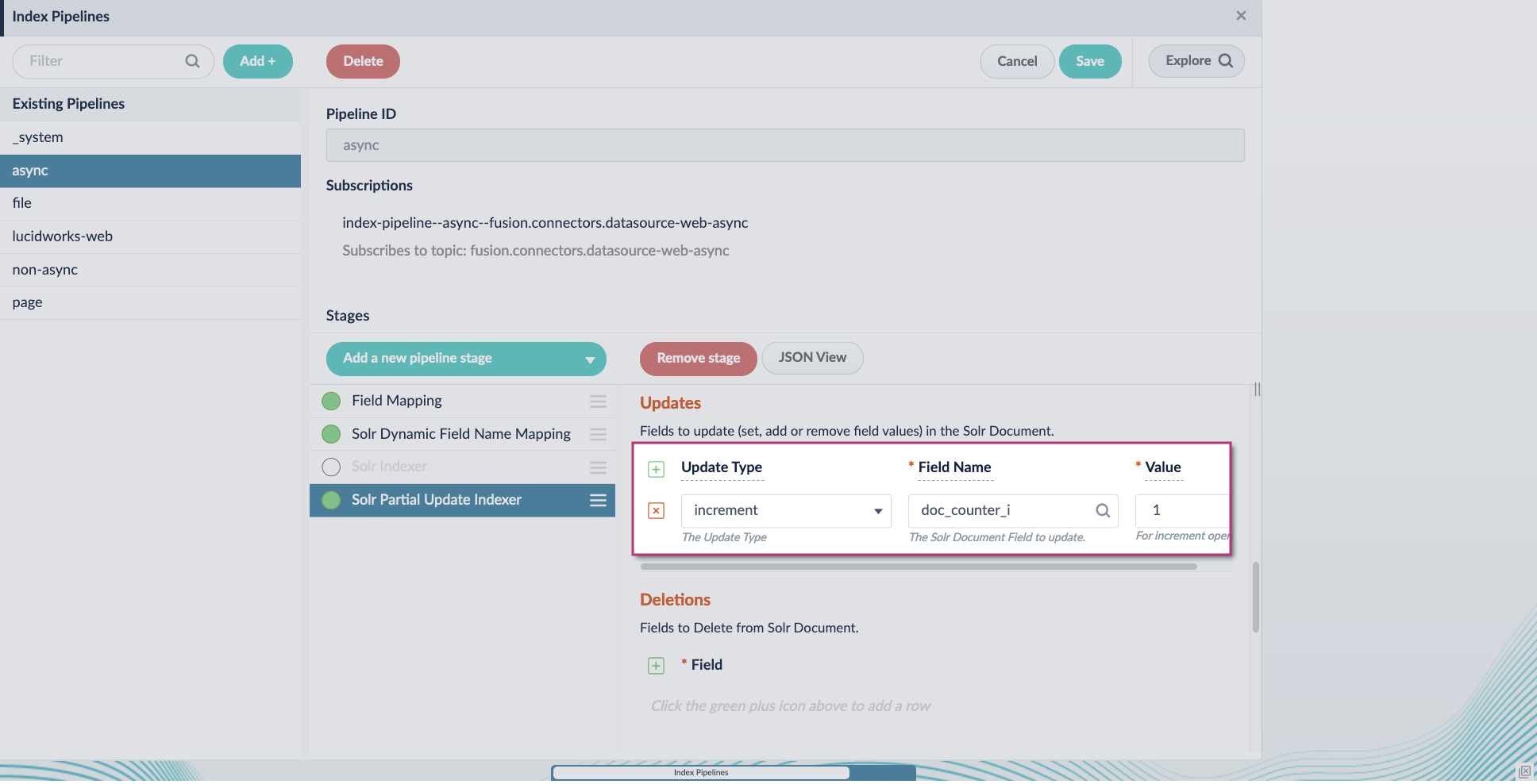
-
Enable the Allow reserved fields option:
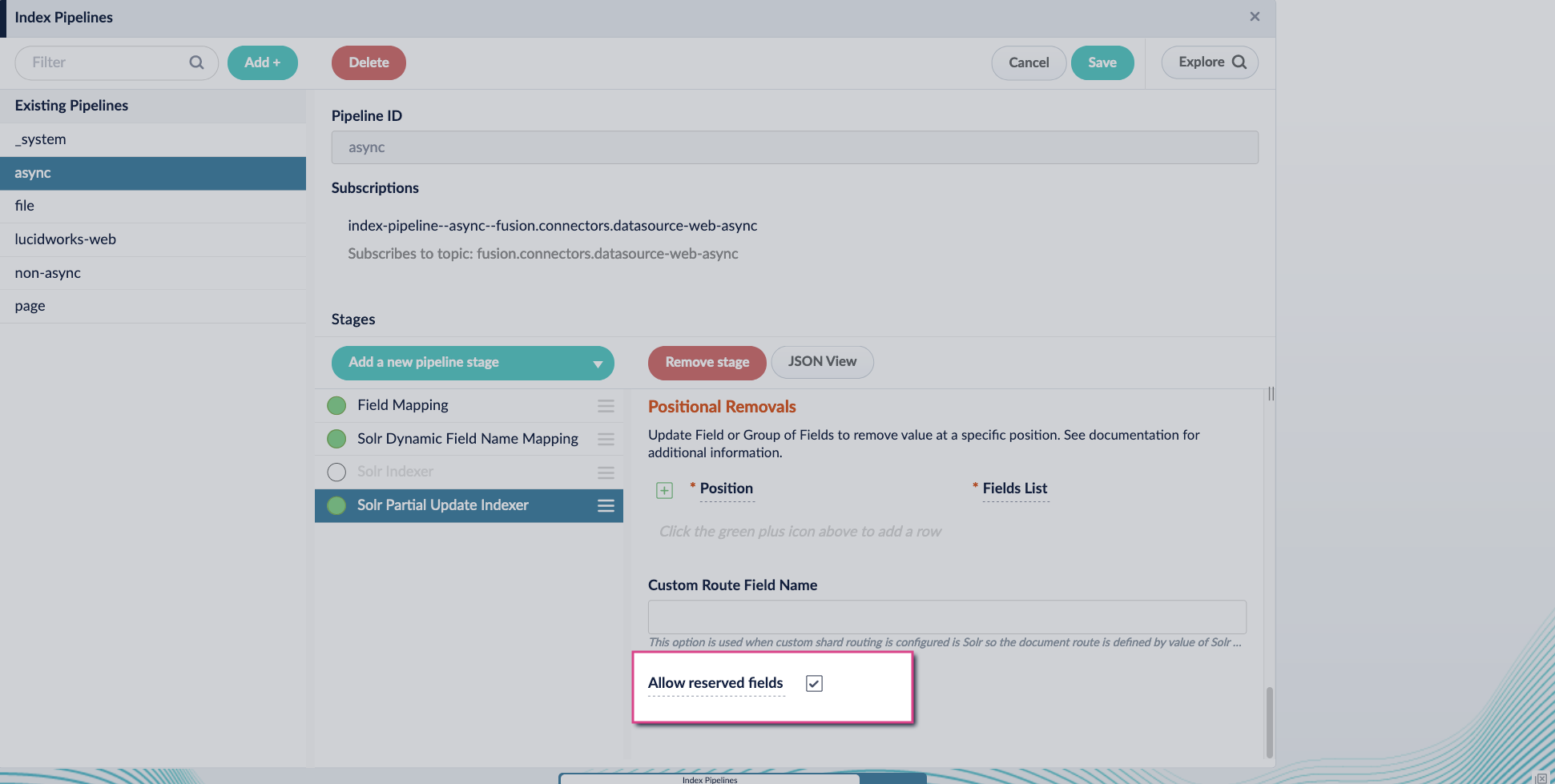
- Click Save.
-
Turn off or remove the Solr Indexer stage, and move the Solr Partial Update Indexer stage to be the last stage in the pipeline.