Queries-for-Query Recommendations
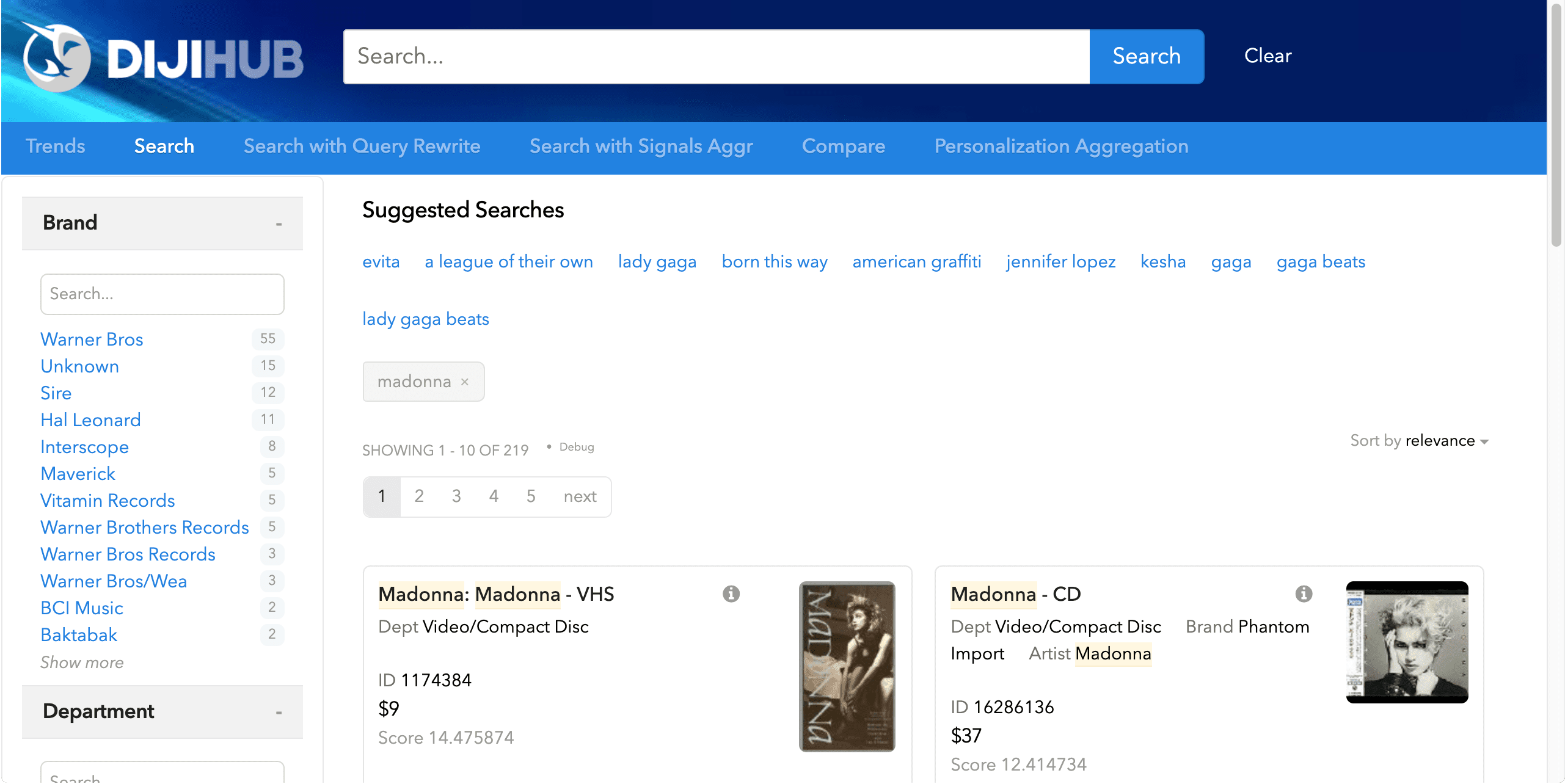
Queries-for-query recommendations are queries performed by other users who also performed the current query. For example, when a user searches for "madonna", your app may also suggest searches for "evita", "a league of their own", "lady gaga", and so on.
The "Suggested Searches" shown below are one example of queries-for-query recommendations:
To enable queries-for-query recommendations, use the Query-to-Query Session-Based Similarity job, which is session-based unlike the Synonym Detection job.
| The Query-to-Query Similarity recommender job was deprecated in Fusion 5.2. |
The job generates two sets of recommendations based on the two approaches described below, then merges and de-duplicates them to present unique query-recommender pairs.
| Similar queries based on documents clicked | Similar queries based on co-occurrence in sessions |
|---|---|
Queries are considered for recommendation if two queries have similar sets of document IDs clicked according to the signals data. This is directly implemented from the similar queries portion of the Synonym Detection job. This approach can work on both raw and aggregated signals. |
Queries are considered for recommendation if two queries have co-occurred in the same session based on the assumption that users search for similar items in a single search session (this may or may not hold true depending on the data). This approach, based on session/user IDs, needs raw signals to work. |

A default Query-to-Query Session-Based Similarity job (COLLECTION_NAME_query_recs) and a dedicated collection and pipeline are created when you enable recommendations for a collection.
At a minimum, you must configure these:
-
an ID for this job
-
the input collection containing the signals data, usually
COLLECTION_NAME_signals -
the data format, usually
solr -
the query field name, usually
query_s -
the document ID field name, usually
doc_id_s -
optionally, the user session ID or user ID field name
If this field is not specified, then the job generates click-based recommendations only, without session-based recommendations.
Data tips
-
Running the job on other types of data than signals is not recommended and may yield unexpected results.
-
To get about 90% query coverage with the query pipeline, we recommend a raw signals dataset of about ~170k unique queries. More signals will generally improve coverage.
-
On a raw signal dataset of about 3 million records, the job finishes execution in about 7-8 minutes on two executor pods with one CPU and about 3G of memory each. Your performance may vary depending on your configuration.
Boosting recommendations
Generally if a query and recommendation has some token overlap, then they’re closely related and we want to highlight these. Therefore, query-recommendation pair similarity scores can be boosted based on token overlap. This overlap is calculated in terms of the number or fractions of tokens that overlap.
For example, consider the pair (“a red polo shirt”, “red polo”). If the minimum match parameter is set to 1, then there should be 1 token in common. For this example there is 1 token in common and therefore it is boosted. If it is set to 0.5, then at least half of the tokens from the shorter string (in terms of space separated tokens) should match. Here, the shorter string is “red polo” which is 2 tokens long. Therefore, to satisfy the boosting requirement, at least 1 token should match.
Tuning tips
These tuning tips pertain to the advanced Model Tuning Parameters:
-
Special characters to be filtered out. Special characters can cause problems with matching queries and are therefore removed in the job.
Only the characters are removed, not the queries, so a query like ps3$becomesps3. -
Query similarity threshold. This is for use by the similar queries portion of the job and is the same as that used in the Synonym and Similar Queries Detection job.
-
Boost on token overlap. This enables or disables boosting of query recommendation pairs where all or some tokens match. How much match is required to boost can be configured using the next parameter.
For example, if this is enabled, then a query-recommendation pair like
(playstation 3, playstation console)is boosted with a similarity score of 1, provided the minimum match is set to 1 token or 0.5. -
Minimum match for token overlap. Similar to the
mmparam in Solr, this defines the number/fraction of tokens that should overlap if boosting is enabled. Queries and recommendations are split by “ “ (space) and each part is considered a token. If using a less-than sign (<), it must be escaped using a backslash.The value can be an integer, such as 1, in which case that many tokens should match. So in the previous example, pair is boosted because the term “playstation” is common to both and the
mmvalue is set to 1.The value can also be a fraction, in which case that fraction of the shorter member of the query and recommendation pair should match. For example, if the value is set to 0.5 and query is 4 tokens long and recommendation is 6 tokens long then there should be at least 2 common tokens between query and recommendation.
Here the stopwords specified in the list of stopwords are ignored while calculating the overlap.
-
Query clicks threshold. The minimum number of clicked documents needed for comparing queries.
-
Minimum query-recommendation pair occurrence count. Minimum limit for the number of times a query-recommendation pair needs to be generated to make it to the final similar query recommendation list. Default is set to 2. Higher value will improve quality but reduce coverage.
The similar queries collection
The following fields are stored in the COLLECTION_NAME_queries_query_recs collection:
-
query_t -
recommendation_t -
similarity_d, the similarity score -
source_s, the approach that generated this pair, one of the following:SessionBasedorClickedDocumentBased -
query_count_l, the number of times the query occurred in signals -
recommendation_count_l, the number of times recommendations occurred in signals -
pair_count_l, the number of instances of the pair generated in the final recommendations using either of the approaches -
type_s, always set tosimilar_queries
The query pipeline
When you enable recommendations, a default query pipeline, COLLECTION_NAME_queries_query_recs. is created.