Query Rewriting
Query rewriting is a strategy for improving relevancy using AI-generated data. Many of Fusion AI’s features can be used to rewrite incoming queries prior to submitting them to Fusion’s Solr core. These rewrites produce more relevant search results with higher conversion rates.
For example, when spelling corrections are used for query rewriting, a misspelled query can return the same search results as a correctly-spelled query, instead of returning irrelevant results or no results. Spelling corrections are one of several available query rewriting strategies. Apply all available strategies for best results.
See also the Query Rewriting API.
Fusion can also rewrite Solr’s responses before returning them to the search application; see Response Rewriting.
If you have apps created in Fusion 4.1 and earlier, see these instructions for enabling business rules in those apps.
See also these subtopics:
Query rewriting strategies
Fusion AI provides a variety of query rewriting strategies to improve relevancy:
With the exception of business rules, which are always manually created, these strategies correspond to certain Spark jobs. Lucidworks recommends configuring and scheduling all of these jobs for best results. You can also train the jobs by manually adding documents to their output. Manually-added documents are used for machine learning and are never overwritten by new job output.
Query rewriting strategies are applied in the following order:
-
Business rules
If a query triggers a business rule, then the business rule overrides any query rewriting strategies that conflict with it.
-
Underperforming query rewriting
If a query triggers an underperforming query rewrite, then this strategy overrides all subsequent query rewriting strategies.
-
Synonym detection
-
Misspelling detection and phrase detection
The query rewriting results from both of these strategies are applied together. To use only the strategy with the longest surface form, you can configure the Text Tagger query stage with Overlapping Tag Policy set to "LONGEST_DOMINANT_RIGHT".
Business rules
Business rules are manually-created formulas for rewriting queries. This is the most versatile strategy for creating custom query rewrites. It supports a variety of conditions and actions to address a wide range of use cases. When you need a very specific query rewrite, this is the best strategy.
Business rules are applied in the Apply Rules stage of the query pipeline.
See Business Rules to learn how to create, edit, and publish business rules.
Underperforming query rewriting
The Underperforming Query Rewriting feature:
-
Uses signals data to identify underperforming queries
-
Suggests improved queries that could produce better conversion rates
When underperforming query rewriting is enabled and an incoming query contains a matching underperforming query term, the original query term is replaced by the improved query term.
Query improvements are applied in the Text Tagger stage of the query pipeline.
See Underperforming Query Rewriting to learn how to review, edit, create, and publish query improvements.
Misspelling detection
The Misspelling Detection feature maps misspellings to their corrected spellings. When Fusion receives a query containing a known misspelling, it rewrites the query using the corrected spelling in order to return relevant results instead of an empty or irrelevant results set.
Spelling corrections are applied in the Text Tagger stage of the query pipeline.
See Misspelling Detection to learn how to review, edit, create, and publish spelling corrections.
| Misspelled terms are completely replaced by their corrected terms. To expand the query to include all alternative terms, see the Synonym Detection feature and set your synonyms to be bi-directional. |
Phrase detection
Phrase detection identifies phrases in your signals so that results with matching phrases can be boosted. This helps compensate for queries where phrases are not distinguished with quotation marks. For example, the query ipad case is rewritten as “ipad case”~10^2, meaning if ipad and case appear within 10 terms (whitespace-delimited tokens) of each other, then boost the result by a factor of 2.
Phrases are applied in the Text Tagger stage of the query pipeline.
See Phrase Detection to learn how to review, edit, create, and publish phrases.
Synonym detection
The Synonym Detection feature generates pairs of synonyms and pairs of similar queries. Two words are considered potential synonyms when they are used in a similar context in similar queries. When synonym detection is enabled, a query that contains a matching term is expanded to include all of its synonyms, with the original term boosted by a factor of two.
Synonyms are applied in the Text Tagger stage of the query pipeline.
See Synonym Detection to learn how to review, edit, create, and publish pairs of synonyms and similar queries.
The Query Rewriting UI
To open the query rewriting interface, navigate to Relevance > Rules > Query Rewriting.
The query rewriting dashboard appears:
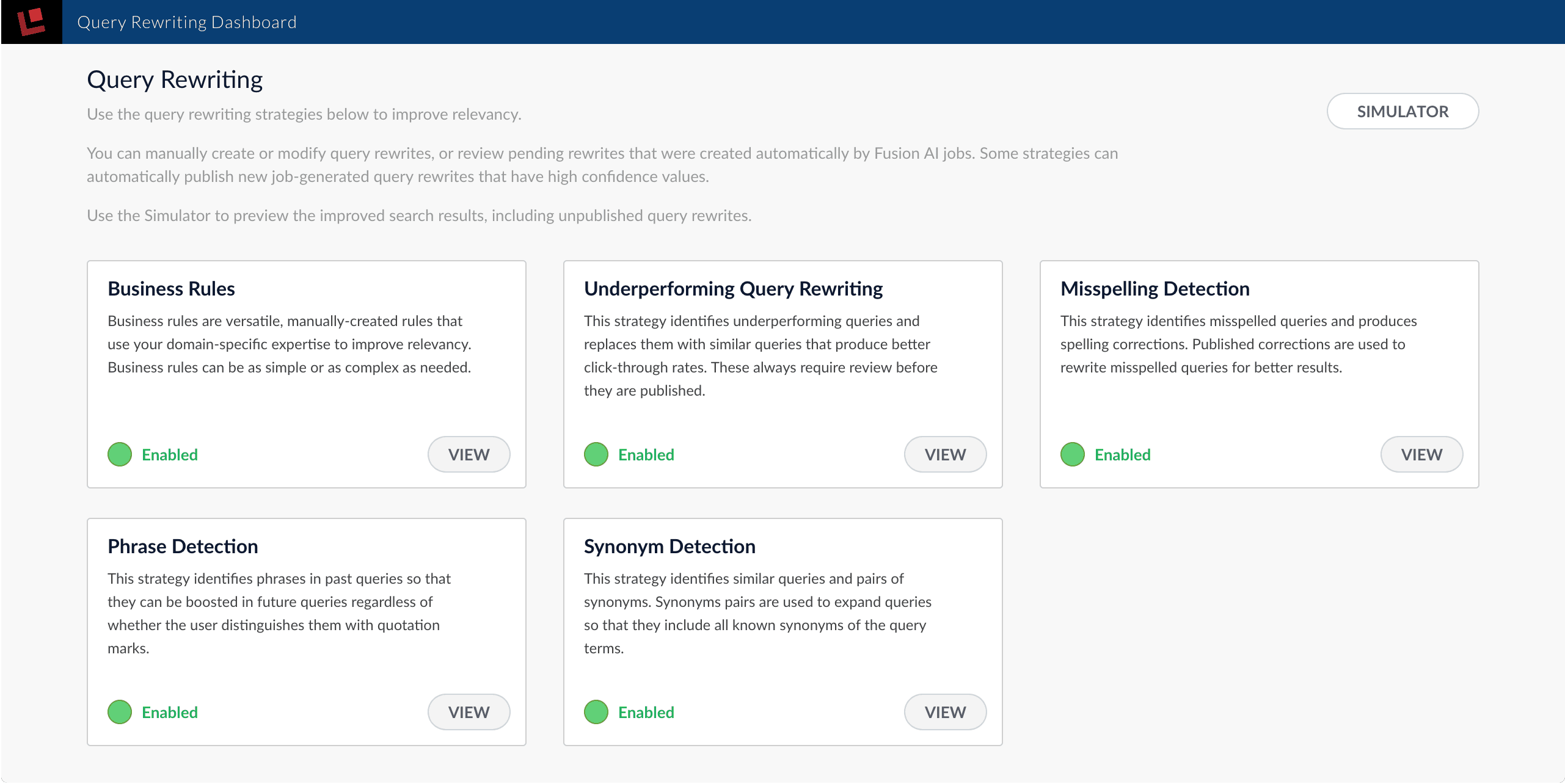
This page gives you access to the Simulator and the query rewriting strategies:
All of these components are enabled by default. You can click "Enabled" to toggle it to "Disabled".
| Enabling and disabling strategies in the Query Rewriting UI does not enable or disable their corresponding Spark jobs. |
Query rewrite collections
| For detailed information about query rewriting, see Manage Collections in the Fusion UI. |
For each app, two ancillary collections are dedicated to documents used for query rewriting:
-
_query_rewrite_stagingAs of Fusion 4.2, certain Spark jobs send their output to this collection. Rules are also written to this collection initially.
Some of the content in this collection requires manual review before it can be migrated to the
_query_rewrite, where query pipelines can read it. See below for details. -
_query_rewriteThis collection is optimized for high-volume traffic. Query pipelines can read from this collection to find rules, synonyms, spelling corrections, and more with which to rewrite queries and responses.
Each app contains exactly one of each of these collections, associated with the app’s default collection. They are not created again for additional collections created within the same app.
Documents move from query_rewrite_staging to the _query_rewrite collection only when they are approved (either automatically on the basis of their confidence scores or manually by a human reviewer) _and a Fusion user clicks Publish. The review field value indicates whether a document will be published when the user clicks Publish:
|
A job-generated document has a sufficiently high confidence score and is automatically approved for publication. |
|
A job-generated document has an ambiguous confidence score and must be reviewed by a Fusion user. |
|
A Fusion user has reviewed the document and approved it for publication. |
|
A job-generated document has a low confidence score, or a Fusion user has reviewed and denied it for publication. |
In the query rewriting UI, the value of the review field appears in the Status column.
|
You can review and approve or deny documents using the query rewriting UI. You can also change a document’s status to "pending" to save it for later review.
Rules Simulator query profile
The Rules Simulator allows product owners to experiment with rules and other query rewrites in the _query_rewrite_staging collection before deploying them to the _query_rewrite collection.
Each app has a _rules_simulator query profile, configured to use the _query_rewrite_staging collection for query rewrites instead of the _query_rewrite collection. This profile is created automatically whenever a new app is created.
Query pipeline stages for query rewriting
These query rewriting stages are part of any default query pipeline:
-
This stage looks up rules that have been deployed to the response rewriting are applied by the Modify Response with Rules stage later in the pipeline.
-
Text Tagger query pipeline stage
This stage uses the SolrTextTagger handler to identify known entities in the query by searching either of the following:
-
_query_rewritecollection. See Manage Collections in the Fusion UI for more information. -
_query_rewrite_stagingcollection in the case of the Fusion AI query rewriting Simulator.
To perform query rewriting, this stage searches for matching instances of:
Spark jobs for query rewriting
This section describes how Spark jobs support query rewriting. These jobs read from the signals collection and write their output to the _query_rewrite_staging collection. High-confidence results are automatically migrated from there to the _query_rewrite collection, while ambiguous results remain in the staging collection until they are reviewed and approved. You can review job results in the Query Rewriting UI.
-
Daily query rewriting jobs are created and scheduled automatically when you create a new app.
-
Additional query rewriting jobs can be created manually.
| For best relevancy, enable all of these jobs. |
Daily query rewriting jobs
When a new app is created, the jobs below are also created and scheduled to run daily, beginning 15 minutes after app creation, in the following order:
-
Token and Phrase Spell Correction job
Detect misspellings in queries or documents using the numbers of occurrences of words and phrases.
-
Identify multi-word phrases in signals.
-
Synonym and Similar Queries Detection job
Use this job to generate pairs of synonyms and pairs of similar queries. Two words are considered potential synonyms when they are used in a similar context in similar queries.
The first and second jobs can provide input to improve the Synonym job’s output:
-
Token and Phrase Spell Correction job results can be used to avoid finding mainly misspellings, or mixing synonyms with misspellings.
-
Phrase Extraction job results can be used to find pairs of synonyms with multiple tokens, such as "lithium ion"/"ion battery".
-
The second and third jobs are triggered by the success of the previous job, that is, the phrase detection job runs only if the spell correction job succeeds, and the synonym job runs only if the phrase detection job succeeds.
Additional query rewriting jobs
These jobs also produce results that are used for query rewriting, but must be created manually:
-
Perform head/tail analysis of queries from collections of raw or aggregated signals, to identify underperforming queries and the reasons. This information is valuable for improving overall conversions, Solr configurations, auto-suggest, product catalogs, and SEO/SEM strategies, in order to improve conversion rates.
-
Estimate ground truth queries using click signals and query signals, with document relevance per query determined using a click/skip formula.
"rules" role for query rewriting users
The "rules" role provides permissions to access query rewriting features for all Fusion apps. A Fusion admin can create a user account with this role to give a business user access to the Query Rewriting UI.
Query rewrite jobs post-processing cleanup
To perform more extensive cleanup of query rewrites, complete the procedures in Query Rewrite Jobs Post-processing Cleanup.