Token and Phrase Spell Correction Job
Detect misspellings in queries or documents using the numbers of occurrences of words and phrases.
Default job name |
|
Input |
Raw signals (the |
Output |
Synonyms (the |
query |
count_i |
type |
timstamp_tdt |
user_id |
doc_id |
session_id |
fusion_query_id |
|
|---|---|---|---|---|---|---|---|---|
Required signals fields: |
|
|
|
This job extracts tail tokens (one word) and phrases (two words) and finds similarly-spelled head tokens and phrases. For example, if two queries are spelled similarly, but one leads to a lot of traffic (head) and the other leads to a little or zero traffic (tail), then it is likely that the tail query is misspelled and the head query is its correction.
If several matching head tokens are found for each tail token, the job can pick the best correction using multiple configurable criteria.
You can review, edit, deploy, or delete output from this job using the Query Rewriting UI.
| Misspelled terms are completely replaced by their corrected terms. If you want to expand the query to include all alternative terms, set the synonyms to bi-directional. See Synonym Detection for more information. |
This job’s output, and output from the Phrase Extraction job, can be used as input for the Synonym Detection job.
Solr treats spelling corrections as synonyms. See the blog post Multi-Word Synonyms: Solr Adds Query-Time Support for more details.
1. Create a job
Create a Token and Phrase Spell Correction job in the Jobs Manager.
-
In the Fusion workspace, navigate to
 > Jobs.
> Jobs. -
Click Add and select the job type Token and phrase spell correction.
The New Job Configuration panel appears.
2. Configure the job
Use the information in this section to configure the Token and Phrase Spell Correction job.
Required configuration
The configuration must specify:
-
Spark Job ID. Used in the API to reference the job. Maximum 63 alphabetic characters, hyphen (-), and underscore (_).
-
INPUT COLLECTION. The
trainingCollectionparameter that can contain signal data or non-signal data. For signal data, select Input is Signal Data (signalDataIndicator). Signals can be raw (from the_signalscollection) aggregated (from the_signals_aggrcollection). -
INPUT FIELD. The
fieldToVectorizeparameter. -
COUNT FIELD
For example, if signal data follows the default Fusion setup, then
count_iis the field that records the count of raw signals andaggr_count_iis the field that records the count after aggregation.
| See Configuration properties for more information. |
Event types
The spell correction job lets you analyze query performance based on two different events:
-
The main event (the Main Event Type/
mainTypeparameter) -
The filtering/secondary event (the Filtering Event Type/
filterTypeparameter)If you only have one event type, leave this parameter empty.
For example, if you specify the main event type to be click with a minimum count of 0 and the filtering event type to be query with a minimum count of 20, then the job:
-
Filters on the queries that get searched at least 20 times.
-
Checks among those popular queries to determine which ones didn’t get clicked at all, or were only clicked a few times.
Spell check documents
If you unselect the Input is Signal Data checkbox to indicate finding misspellings from content documents rather than signals, then you do not need to specify the following parameters:
-
Count Field
-
Main Event Field
-
Filtering Event Type
-
Field Name of Signal Type
-
Minimum Main Event Count
-
Minimum Filtering Event Count
Use a custom dictionary
You can upload a custom dictionary of terms that are specific to your data, and specify it using the Dictionary Collection (dictionaryCollection) and Dictionary Field (dictionaryField) parameters. For example, in an e-commerce use case, you can use the catalog terms as the custom dictionary by specifying the product catalog collection as the dictionary collection and the product description field as the dictionary field.
Example configuration
This is an example configuration:
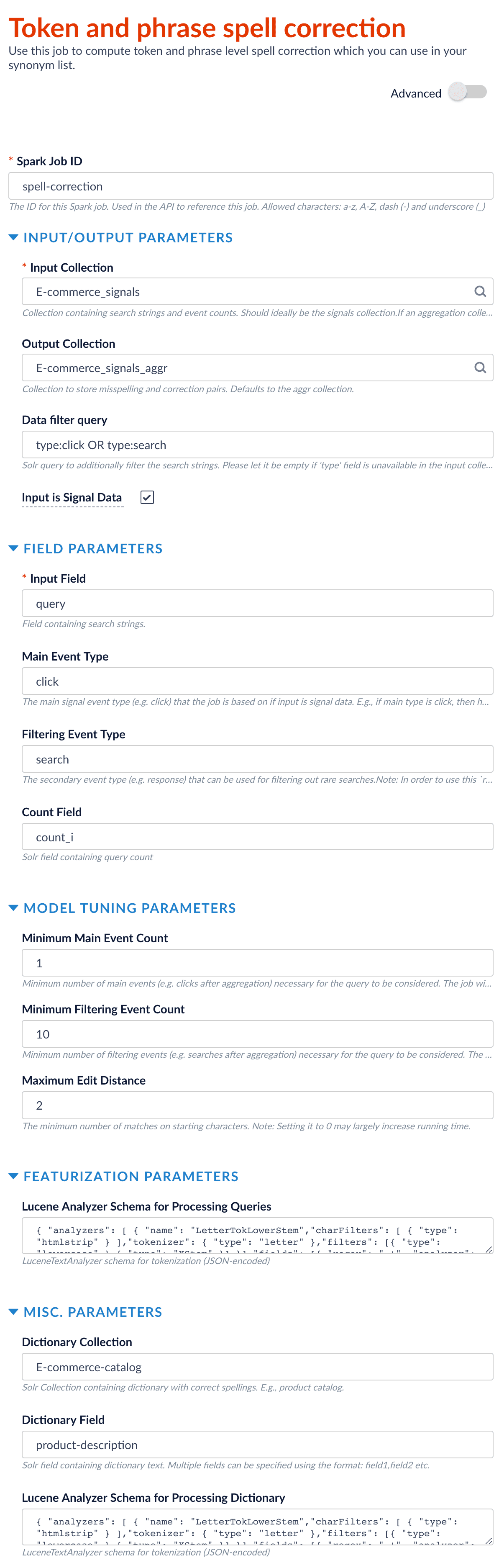
When you have configured the job, click Save to save the configuration.
3. Run the job
| If you are finding spelling corrections in aggregated data, you need to run an aggregation job before running the Token and Phrase Spelling Correction job. You do not need to run a Head/Tail Analysis job. The Token and Phrase Spell Correction job does the head/tail processing it requires. |
-
In the Fusion workspace, navigate to
> Jobs. -
Select the job from the job list.
-
Click Run.
-
Click Start.
4. Analyze job output
After the job finishes, misspellings and corrections are output into the
query_rewrite_staging
collection by default; you can change this by setting the outputCollection.
An example record is as follows:
correction_s laptop battery
mis_string_len_i 14
misspelling_s laptop baytery
aggr_job_id_s 162fcf94b20T3704c333
score 1
collation_check_s token correction included
corCount_misCount_ratio_d 2095
sound_match_b true
id bf79c43b-fc6d-43a7-931e-185fdac5b624
aggr_type_s tokenPhraseSpellCorrection
aggr_id_s ecom_spell_check
correction_types_s phrase => phrase
cor_count_i 68648960
suggested_correction_s baytery=>battery
cor_string_len_i 14
token_wise_correction_s baytery=>battery
cor_token_size_i 2
edit_dist_i 1
timestamp_tdt 2018-04-25T13:23:40.728Z
mis_count_i 32768
lastChar_match_b true
mis_token_size_i 2
token_corr_for_phrase_cnt_i 1For easy evaluation, you can export the result output to a CSV file.
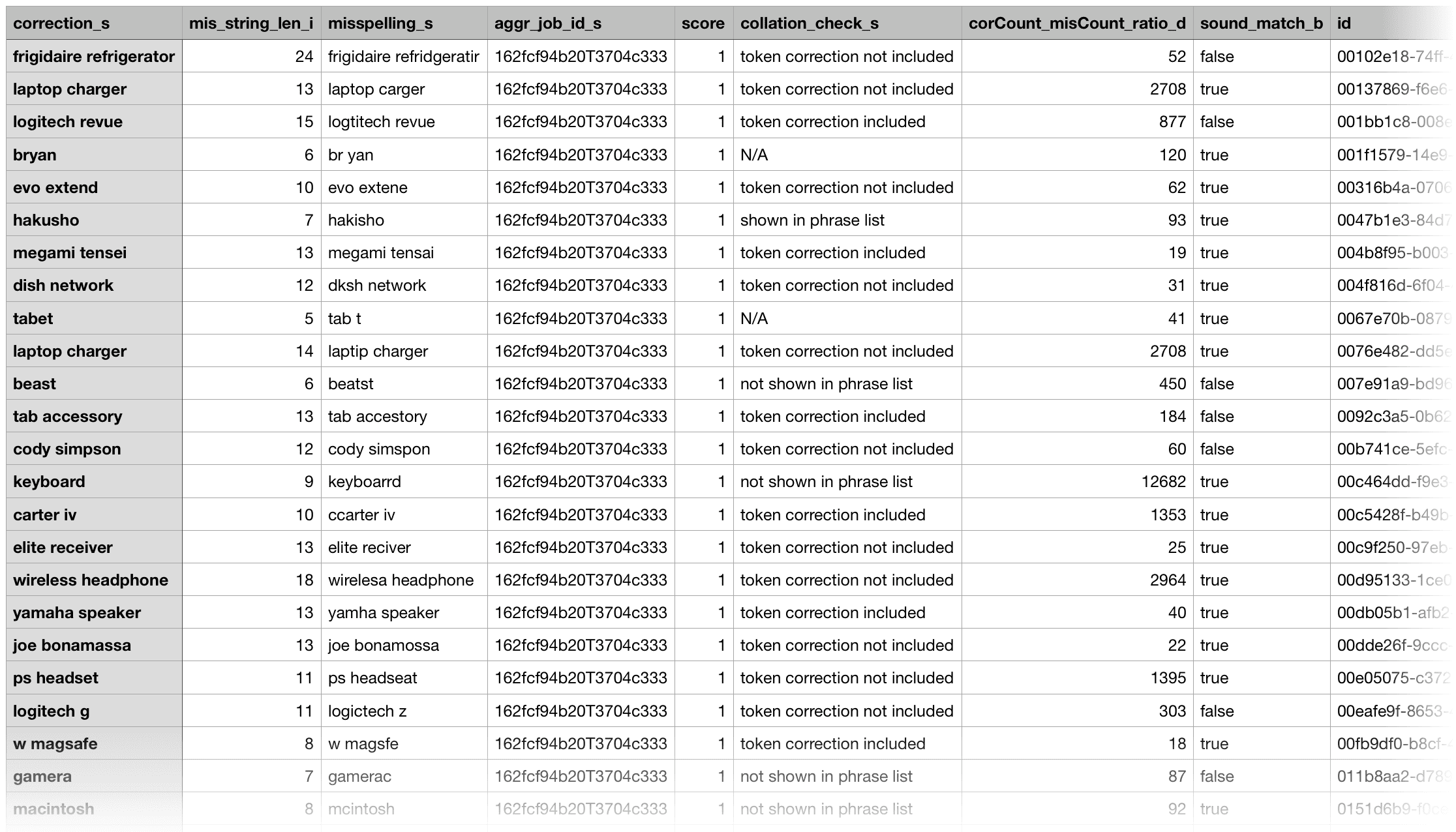
5. Use spell correction results
You can use the resulting corrections in various ways. For example:
-
Put misspellings into the synonym list to perform auto-correction.
-
Help evaluate and guide the Solr spellcheck configuration.
-
Put misspellings into typeahead or autosuggest lists.
-
Perform document cleansing (for example, clean a product catalog or medical records) by mapping misspellings to corrections.
Useful output fields
In the job output, you generally only need to analyze the suggested_corrections field, which provides suggestions about using token correction or whole-phrase correction. If the confidence of the correction is not high, then the job labels the pair as "review" in this field. Pay special attention to the output records with the "review" labels.
With the output in a CSV file, you can sort by mis_string_len (descending) and edit_dist (ascending) to position more probable corrections at the top. You can also sort by the ratio of correction traffic over misspelling traffic (the corCount_misCount_ratio field) to only keep high-traffic boosting corrections.
For phrase misspellings, the misspelled tokens are separated out and put in the token_wise_correction field. If the associated token correction is already included in the one-word correction list, then the collation_check field is labeled as "token correction include." You can choose to drop those phrase misspellings to reduce duplications.
Fusion counts how many phrase corrections can be solved by the same token correction and puts the number into the token_corr_for_phrase_cnt field. For example, if both "outdoor surveillance" and "surveillance camera" can be solved by correcting "surveillance" to "surveillance", then this number is 2, which provides some confidence for dropping such phrase corrections and further confirms that correcting "surveillance" to "surveillance" is legitimate.
You might also see cases where the token-wise correction is not included in the list. For example, "xbow" to "xbox" is not included in the list because it can be dangerous to allow an edit distance of 1 in a word of length 4. But if multiple phrase corrections can be made by changing this token, then you can add this token correction to the list.
Phrase corrections with a value of 1 for token_corr_for_phrase_cnt and with collation_check labeled as "token correction not included" could be potentially-problematic corrections.
|
Fusion labels misspellings due to misplaced whitespaces with "combine/break words" in the correction_types field. If there is a user-provided dictionary to check against, and both spellings are in the dictionary with and without whitespace in the middle, we can treat these pairs as bi-directional synonyms ("combine/break words (bi-direction)" in the correction_types field).
The sound_match and lastChar_match fields also provide useful information.
Job tuning
The job’s default configuration is a conservative, designed for higher accuracy and lower output. To produce a higher volume of output, you can consider giving more permissive values to the parameters below. Likewise, give them more restrictive values if you are getting too many results with low accuracy.
| When tuning these values, always test the new configuration in a non-production environment before deploying it in production. |
|
See Event types above, then adjust this value to reflect the secondary event for your search application. To query all data, set this to |
|
Lower this value to include less-frequent misspellings based on the data filter query. |
|
Raise this value to increase the number of potentially-related tokens and phrases detected. |
|
Lower this value to include shorter misspellings (which are harder to correct accurately). |
Query rewrite jobs post-processing cleanup
To perform more extensive cleanup of query rewrites, complete the procedures in Query Rewrite Jobs Post-processing Cleanup.