{description &&
{formatDescription(description)}
}
{visibleProps.map(([name, prop]) => {
const isRequired = requiredProps.includes(name);
const hasDefault = prop.default !== undefined;
const rawDefault = prop.default;
const isComplexDefault = hasDefault && (typeof rawDefault === "object" || typeof rawDefault === "string" && (rawDefault.length > 20 || rawDefault.includes('"')));
const fieldProps = {
key: name,
body: prop.title || name,
type: prop.type,
...prop.title && ({
post: [<>
API property: {name}]
}),
...isRequired && ({
required: true
}),
...!isComplexDefault && hasDefault ? {
default: sanitize(String(rawDefault))
} : {}
};
const isObject = prop.type === "object" && prop.properties;
const isArrayOfObjects = prop.type === "array" && prop.items?.type === "object" && prop.items.properties;
return
{prop.description && {formatDescription(prop.description)}
}
{isComplexDefault &&
Default:
{JSON.stringify(rawDefault, null, 2)}
}
{isArrayOfObjects &&
Object attributes:
{'{\n'}
{Object.entries(prop.items.properties).map(([iname, iprop]) => <>
{` ${iname}`}
{prop.items?.required?.includes(iname) && required}
{`: {\n display name: ${sanitize(iprop.title || '')}\n type: ${iprop.type}\n }\n`}
)}
{'}'}
}
{isObject &&
}
;
})}
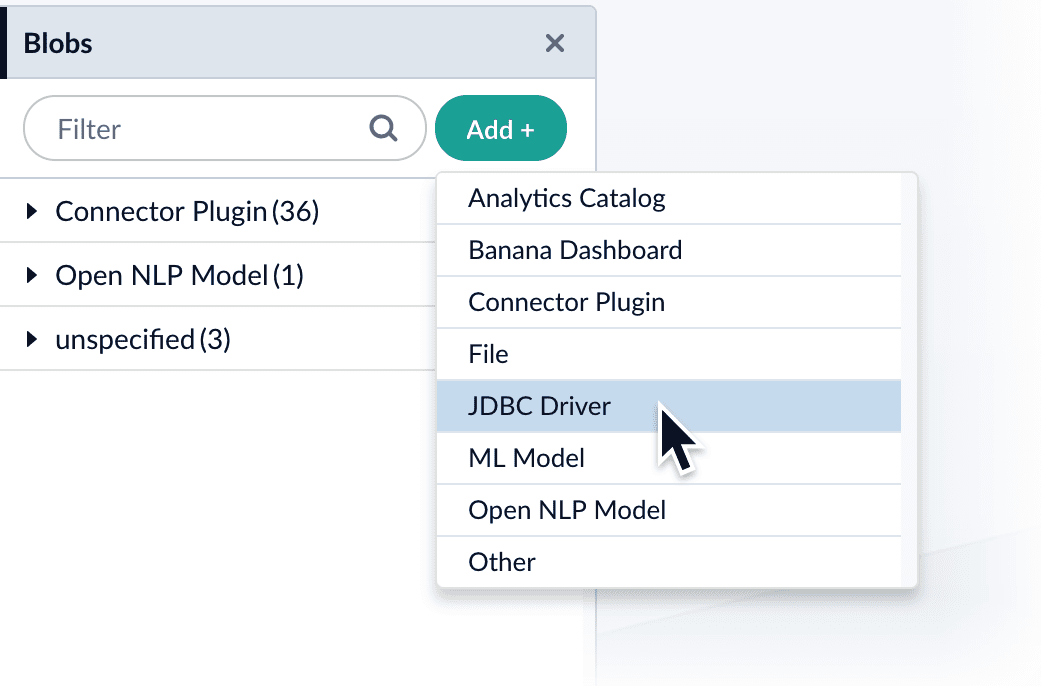 4. Click **Choose File** and select the .jar file from your file system.
4. Click **Choose File** and select the .jar file from your file system.
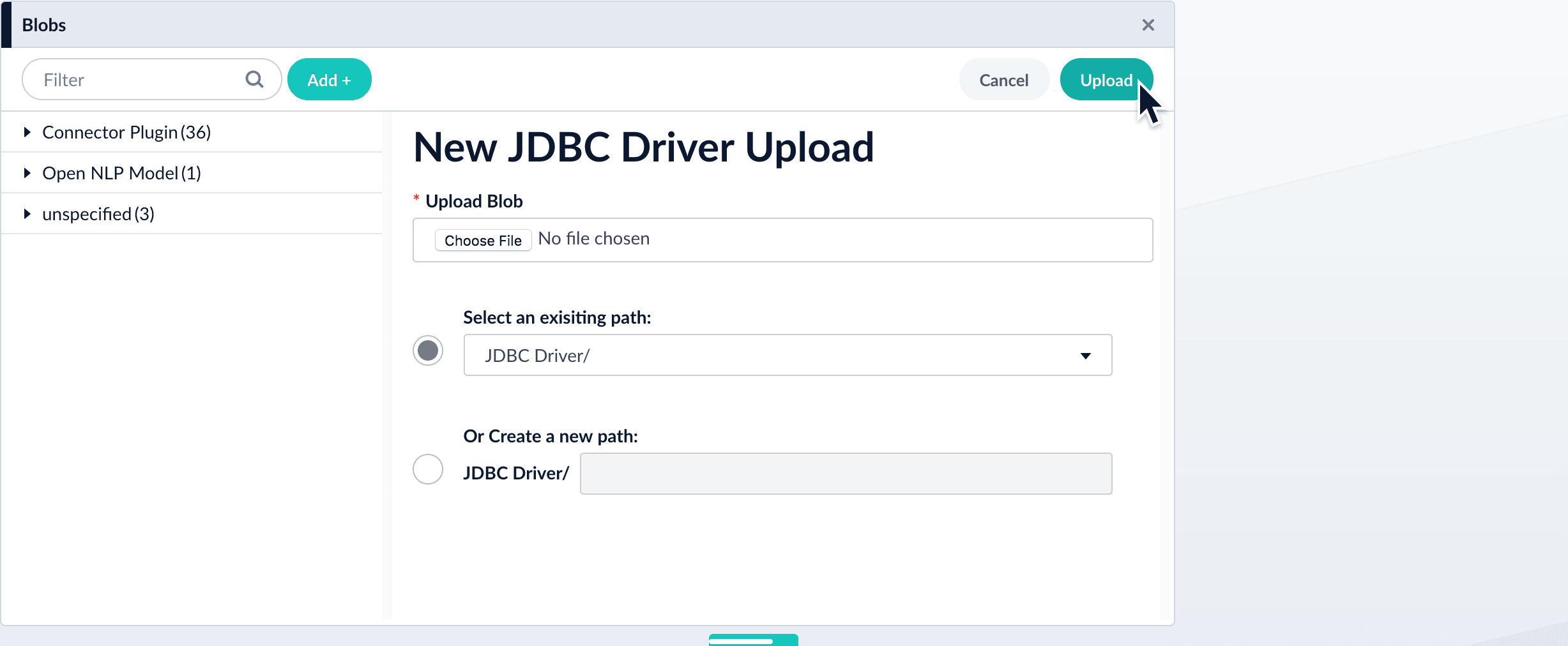 5. Click **Upload**.\
The new driver’s blob manifest appears.
5. Click **Upload**.\
The new driver’s blob manifest appears.
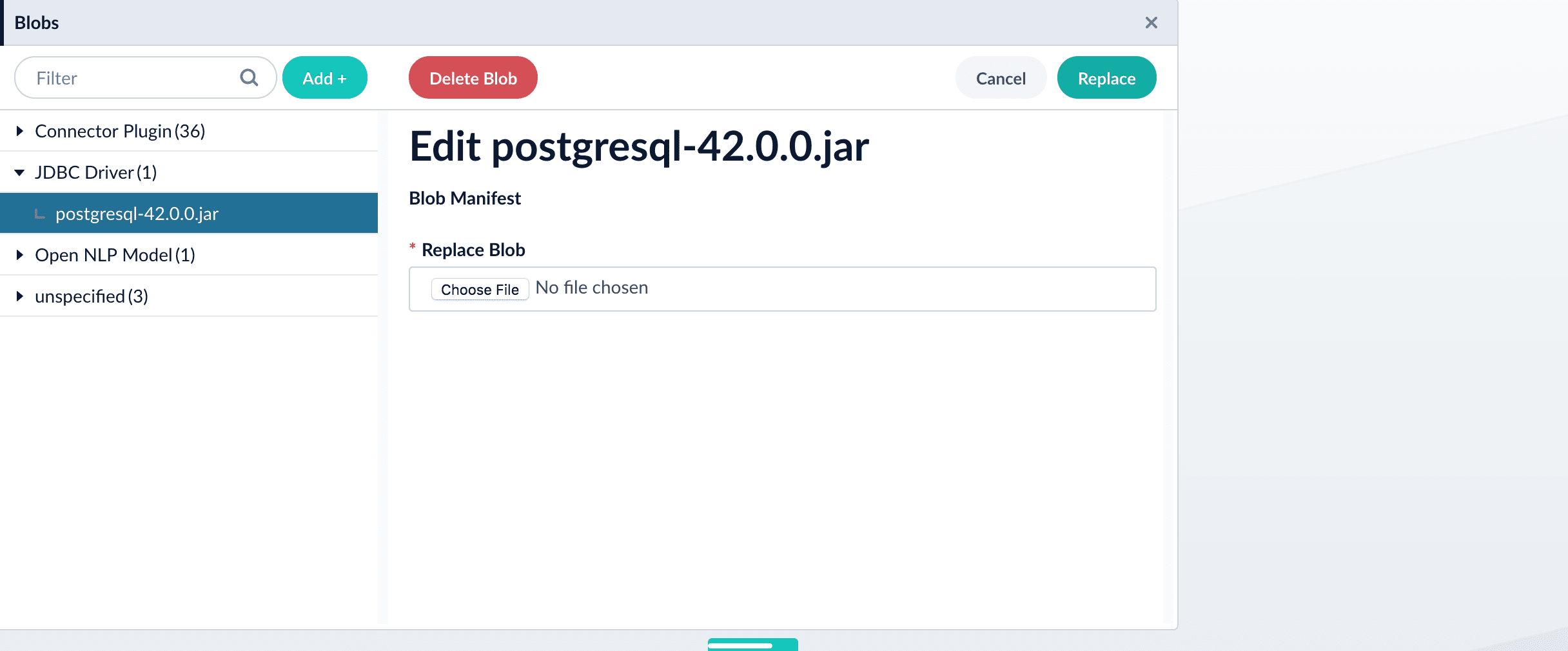 From this screen you can also delete or replace the driver.
{/* // end::upload[] */}
## How to install a JDBC driver using the API
1. Upload the JAR file to Lucidworks Search’s blob store using the [`/blobs/{id}` endpoint](/api-reference/blobs/get-blob-store-service-status).
Specify an arbitrary blob ID, and a `resourceType` value of `plugin:connector`, as in this example:
```bash theme={"dark"}
curl -u USERNAME:PASSWORD -H "content-type:application/java-archive" -H "content-length:707261" -X PUT --data-binary @postgresql-42.0.0.jar https://EXAMPLE_COMPANY.b.lucidworks.cloud/api/blobs/mydriver?resourceType=driver:jdbc
```
Success response:
```json theme={"dark"}
{
"name" : "mydriver",
"contentType" : "application/java-archive",
"size" : 707261,
"modifiedTime" : "2017-06-09T19:00:48.919Z",
"version" : 0,
"md5" : "c67163ca764bfe632f28229c142131b5",
"metadata" : {
"subtype" : "driver:jdbc",
"drivers" : "org.postgresql.Driver",
"resourceType" : "driver:jdbc"
}
}
```
Lucidworks Search automatically publishes the event to the cluster, and the listeners perform the driver installation process on each node.
From this screen you can also delete or replace the driver.
{/* // end::upload[] */}
## How to install a JDBC driver using the API
1. Upload the JAR file to Lucidworks Search’s blob store using the [`/blobs/{id}` endpoint](/api-reference/blobs/get-blob-store-service-status).
Specify an arbitrary blob ID, and a `resourceType` value of `plugin:connector`, as in this example:
```bash theme={"dark"}
curl -u USERNAME:PASSWORD -H "content-type:application/java-archive" -H "content-length:707261" -X PUT --data-binary @postgresql-42.0.0.jar https://EXAMPLE_COMPANY.b.lucidworks.cloud/api/blobs/mydriver?resourceType=driver:jdbc
```
Success response:
```json theme={"dark"}
{
"name" : "mydriver",
"contentType" : "application/java-archive",
"size" : 707261,
"modifiedTime" : "2017-06-09T19:00:48.919Z",
"version" : 0,
"md5" : "c67163ca764bfe632f28229c142131b5",
"metadata" : {
"subtype" : "driver:jdbc",
"drivers" : "org.postgresql.Driver",
"resourceType" : "driver:jdbc"
}
}
```
Lucidworks Search automatically publishes the event to the cluster, and the listeners perform the driver installation process on each node.