{description &&
{formatDescription(description)}
}
{visibleProps.map(([name, prop]) => {
const isRequired = requiredProps.includes(name);
const hasDefault = prop.default !== undefined;
const rawDefault = prop.default;
const isComplexDefault = hasDefault && (typeof rawDefault === "object" || typeof rawDefault === "string" && (rawDefault.length > 20 || rawDefault.includes('"')));
const fieldProps = {
key: name,
body: prop.title || name,
type: prop.type,
...prop.title && ({
post: [<>
API property: {name}]
}),
...isRequired && ({
required: true
}),
...!isComplexDefault && hasDefault ? {
default: sanitize(String(rawDefault))
} : {}
};
const isObject = prop.type === "object" && prop.properties;
const isArrayOfObjects = prop.type === "array" && prop.items?.type === "object" && prop.items.properties;
return
{prop.description && {formatDescription(prop.description)}
}
{isComplexDefault &&
Default:
{JSON.stringify(rawDefault, null, 2)}
}
{isArrayOfObjects &&
Object attributes:
{'{\n'}
{Object.entries(prop.items.properties).map(([iname, iprop]) => <>
{` ${iname}`}
{prop.items?.required?.includes(iname) && required}
{`: {\n display name: ${sanitize(iprop.title || '')}\n type: ${iprop.type}\n }\n`}
)}
{'}'}
}
{isObject &&
}
;
})}
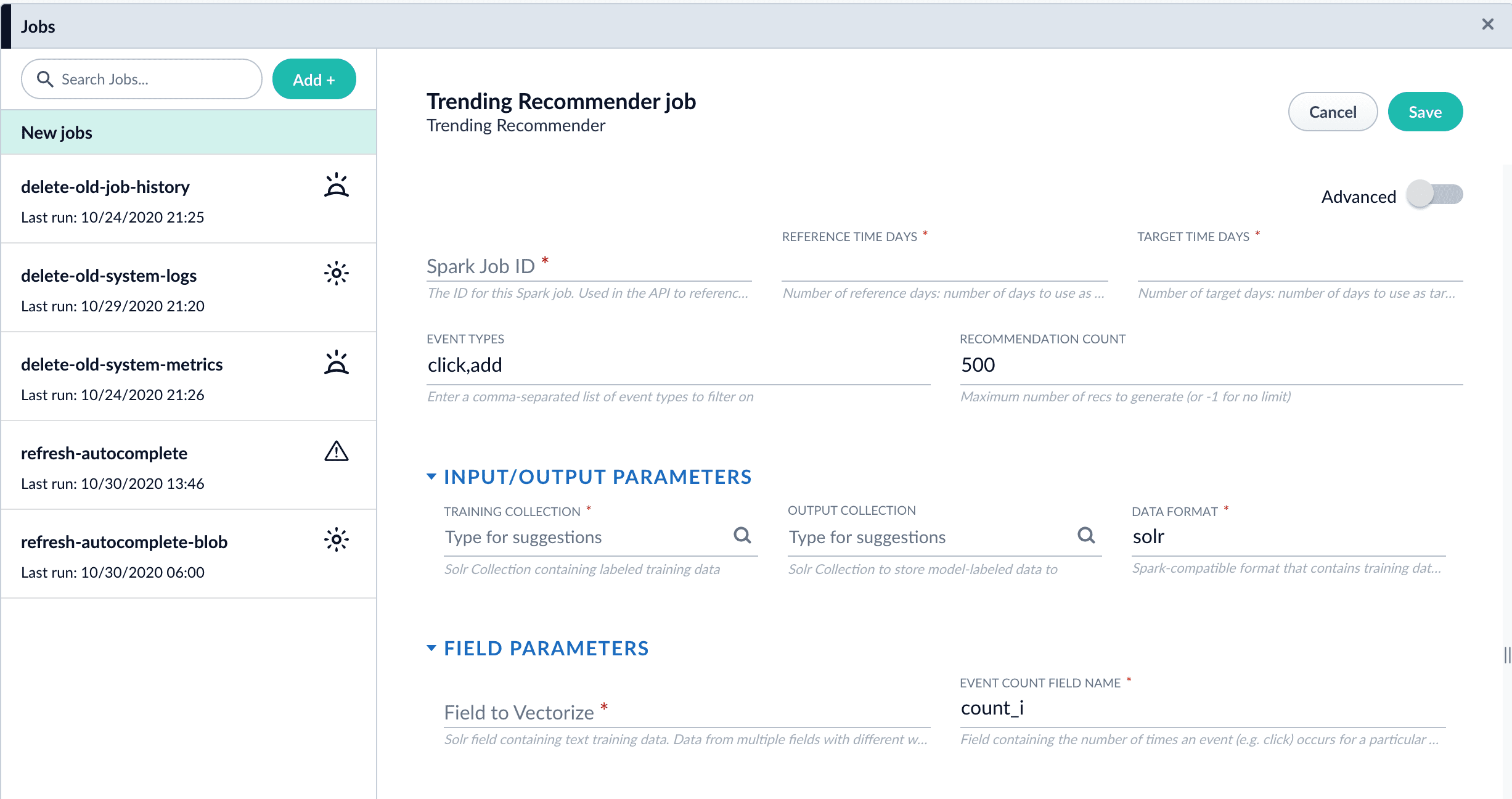 2. Configure the job:
1. Enter an ID for this job.
2. In the **Reference Time Days** field, enter the number of days to use as a *baseline* for identifying trends, starting from today.\
For example, enter 21 days to analyze three weeks of signals data to use as a baseline.
3. In the **Target Time Days** field, enter the number of days to use as a *target* for identifying trends, starting from today.\
For example, enter 7 days to get documents or products whose popularity has spiked in the past week.
2. Configure the job:
1. Enter an ID for this job.
2. In the **Reference Time Days** field, enter the number of days to use as a *baseline* for identifying trends, starting from today.\
For example, enter 21 days to analyze three weeks of signals data to use as a baseline.
3. In the **Target Time Days** field, enter the number of days to use as a *target* for identifying trends, starting from today.\
For example, enter 7 days to get documents or products whose popularity has spiked in the past week.