{description &&
{formatDescription(description)}
}
{visibleProps.map(([name, prop]) => {
const isRequired = requiredProps.includes(name);
const hasDefault = prop.default !== undefined;
const rawDefault = prop.default;
const isComplexDefault = hasDefault && (typeof rawDefault === "object" || typeof rawDefault === "string" && (rawDefault.length > 20 || rawDefault.includes('"')));
const fieldProps = {
key: name,
body: prop.title || name,
type: prop.type,
...prop.title && ({
post: [<>
API property: {name}]
}),
...isRequired && ({
required: true
}),
...!isComplexDefault && hasDefault ? {
default: sanitize(String(rawDefault))
} : {}
};
const isObject = prop.type === "object" && prop.properties;
const isArrayOfObjects = prop.type === "array" && prop.items?.type === "object" && prop.items.properties;
return
{prop.description && {formatDescription(prop.description)}
}
{isComplexDefault &&
Default:
{JSON.stringify(rawDefault, null, 2)}
}
{isArrayOfObjects &&
Object attributes:
{'{\n'}
{Object.entries(prop.items.properties).map(([iname, iprop]) => <>
{` ${iname}`}
{prop.items?.required?.includes(iname) && required}
{`: {\n display name: ${sanitize(iprop.title || '')}\n type: ${iprop.type}\n }\n`}
)}
{'}'}
}
{isObject &&
}
;
})}
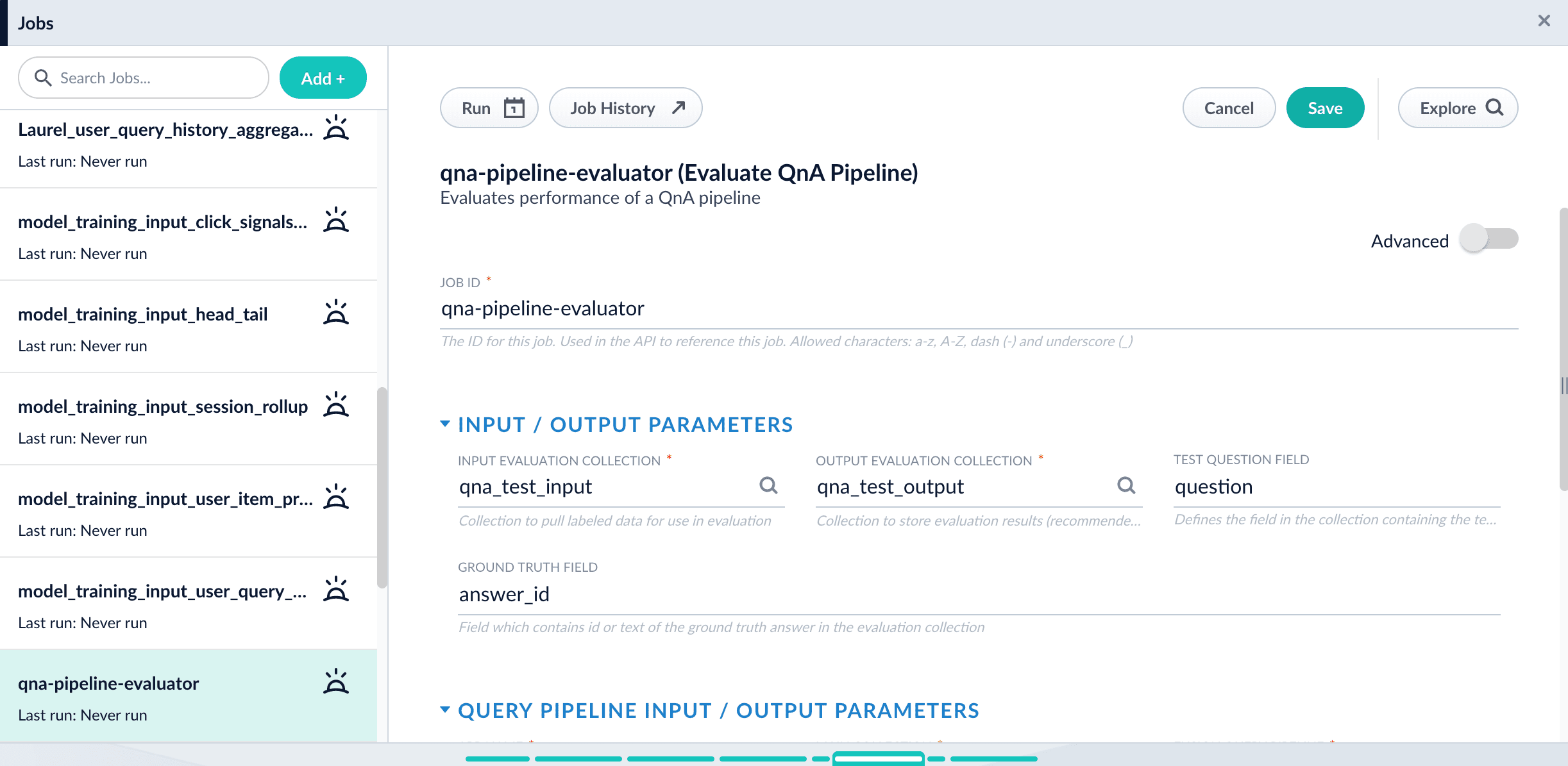 17\. Click **Run** > **Start**.
## Examine the output
The job provides a variety of metrics (controlled by the **Metrics list** advanced parameter) at different positions (controlled by the **Metrics\@k list** advanced parameter) for the chosen final ranking score (specified in **Ranking score** parameter).
**Example: Pipeline evaluation metrics**
17\. Click **Run** > **Start**.
## Examine the output
The job provides a variety of metrics (controlled by the **Metrics list** advanced parameter) at different positions (controlled by the **Metrics\@k list** advanced parameter) for the chosen final ranking score (specified in **Ranking score** parameter).
**Example: Pipeline evaluation metrics**
 **Example: recall\@1,3,5 for different weights and distances**
**Example: recall\@1,3,5 for different weights and distances**