(entire app) App configuration
(combine apps) | - | - | Object Explorer | | **Objects API**
(endpoints) | GET from `export` endpoint | POST to `import` endpoint | GET from `export` endpoint | POST to `import` endpoint | - | For more information about using the Objects API to export and import objects, see [Objects API](/api-reference/objects/get-objects-service-status). The remainder of this topic describes approaches in the Fusion UI. Use the parts of the Fusion UI indicated in the table to export and import apps and specific objects. Exporting creates a zip file. To import, you select a data file and possibly a variable file. The approach with Object Explorer differs. With Object Explorer, you can add objects from other apps (or that are not linked to any apps) to the currently open app. ## Export an app with the Fusion UI **How to export an app with the Fusion UI** 1. Navigate to the launcher. 2. Hover over the app you want to export and click the Configure icon:
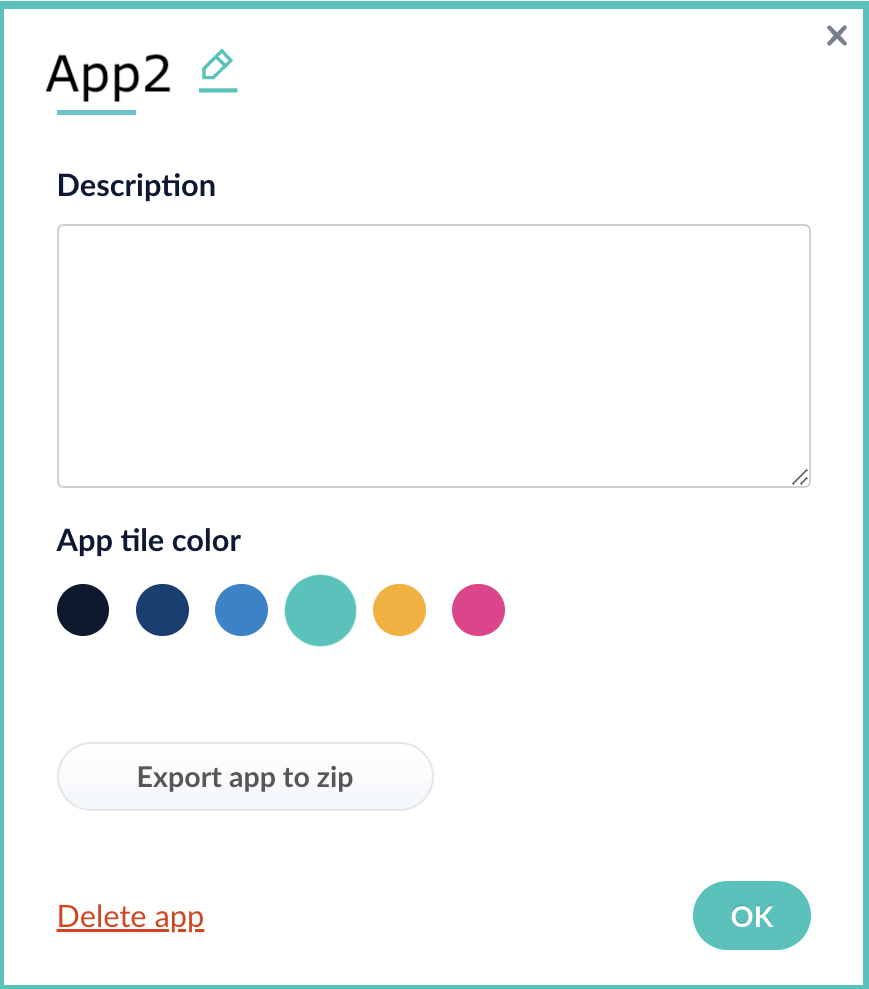
 3. In the app config window, click **Export app to zip**:
3. In the app config window, click **Export app to zip**:
 See import for information to import the downloaded zip file into other instances of Fusion 5.x.
## Import an app with the Fusion UI
**How to import an app with the Fusion UI**
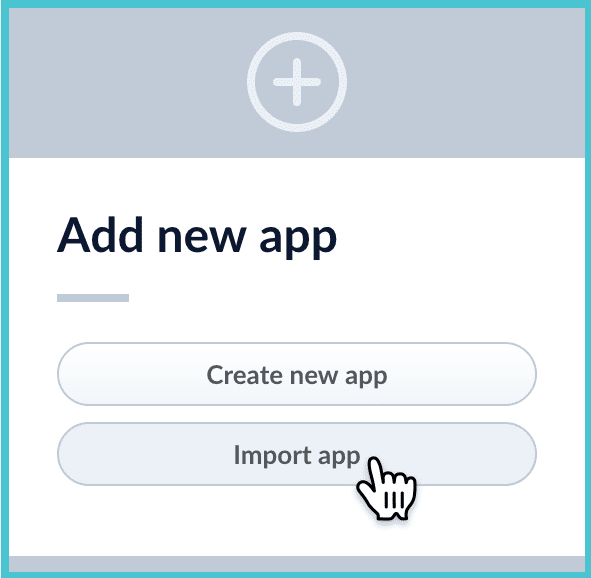
1. Navigate to the launcher.
2. Click **Import app**.
See import for information to import the downloaded zip file into other instances of Fusion 5.x.
## Import an app with the Fusion UI
**How to import an app with the Fusion UI**
1. Navigate to the launcher.
2. Click **Import app**.
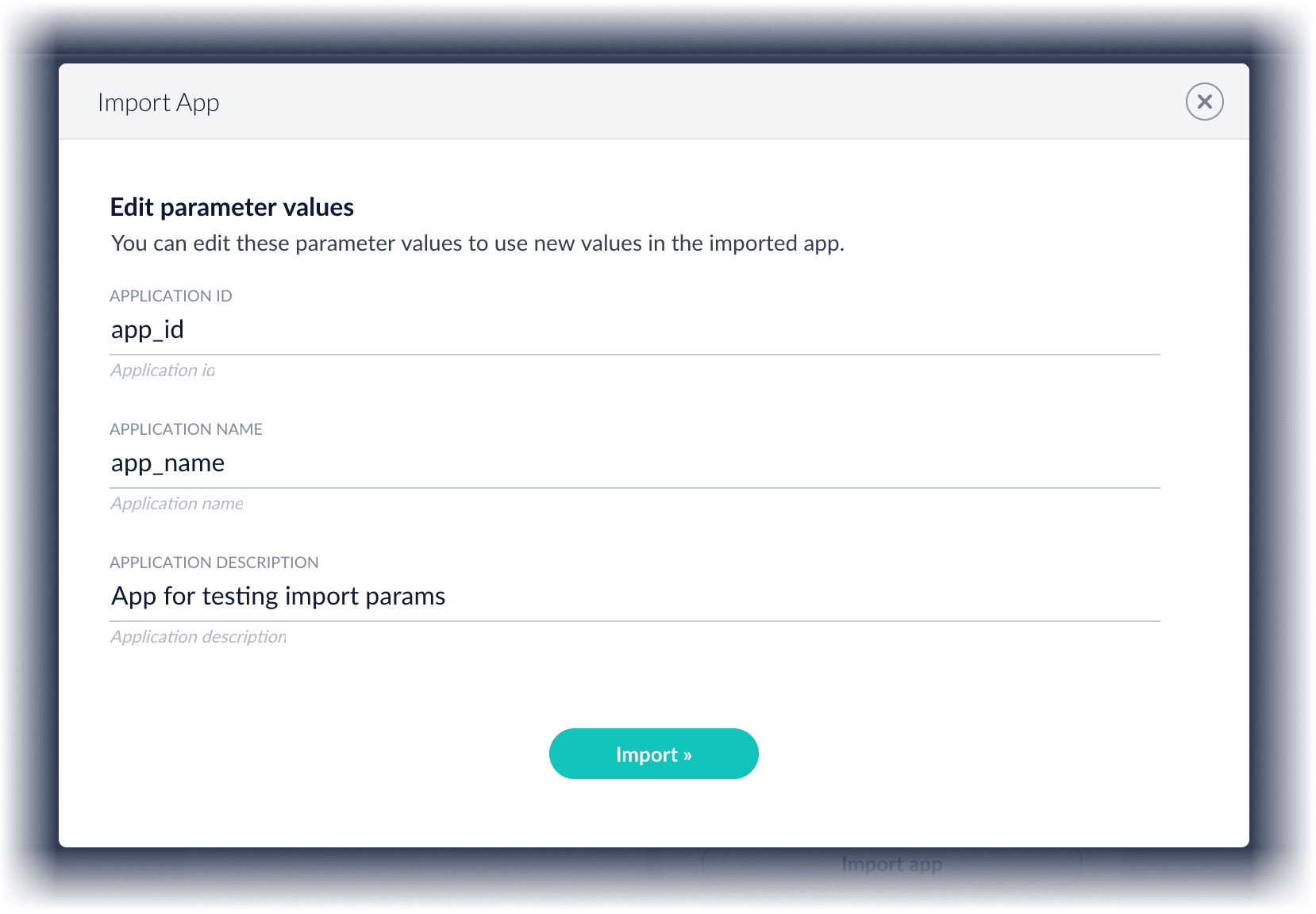
 3. Under **Data File**, click **Choose File** and select the zip file containing the app you want to import.
4. If your app has [usernames and passwords](/api-reference/objects/list-imported-variables) in a separate file, select it under **Variables File**.
If the Variables File is needed, it *must* be a separate file that is not in a .zip file. It is a .json map of variables to values. The following is an example:
```json theme={"dark"}
{
"secret.dataSources.Inventory_BR_S3_DS.password":"SOMETHING",
"secret.dataSources.LLM_A_BR_S3_DS.password":"FmJSaDE9Tj5REDACTED",
"secret.dataSources.LLM_BR_Inventory_S3_DS.password":"FmJSaDE9Tj5GzIVvethAC4Huh",
"secret.dataSources.LLM_BR_Load_S3_DS.password":"FmJSaDE9Tj5GzIVvethAC4"
}
```
5. You can sometimes edit parameter values to use the new values in the imported app. If this is the case, Fusion displays a dialog box that lets you edit the parameter values.
3. Under **Data File**, click **Choose File** and select the zip file containing the app you want to import.
4. If your app has [usernames and passwords](/api-reference/objects/list-imported-variables) in a separate file, select it under **Variables File**.
If the Variables File is needed, it *must* be a separate file that is not in a .zip file. It is a .json map of variables to values. The following is an example:
```json theme={"dark"}
{
"secret.dataSources.Inventory_BR_S3_DS.password":"SOMETHING",
"secret.dataSources.LLM_A_BR_S3_DS.password":"FmJSaDE9Tj5REDACTED",
"secret.dataSources.LLM_BR_Inventory_S3_DS.password":"FmJSaDE9Tj5GzIVvethAC4Huh",
"secret.dataSources.LLM_BR_Load_S3_DS.password":"FmJSaDE9Tj5GzIVvethAC4"
}
```
5. You can sometimes edit parameter values to use the new values in the imported app. If this is the case, Fusion displays a dialog box that lets you edit the parameter values.
 Make desired changes, and then click **Import**.
## Copy an app
To copy an app from one deployment to a different one, [export the app](#export-an-app-with-the-fusion-ui) on the source deployment, and then [import the app](#import-an-app-with-the-fusion-ui) on the target deployment.
## Import objects into an app
You can import objects into the currently open app.
**How to import objects into an open app**
1. In the Fusion launcher, click the app into which you want to import objects.
The Fusion workspace appears.
2. Click **System > Import Fusion Objects**.
The Import Fusion Objects window opens.
Make desired changes, and then click **Import**.
## Copy an app
To copy an app from one deployment to a different one, [export the app](#export-an-app-with-the-fusion-ui) on the source deployment, and then [import the app](#import-an-app-with-the-fusion-ui) on the target deployment.
## Import objects into an app
You can import objects into the currently open app.
**How to import objects into an open app**
1. In the Fusion launcher, click the app into which you want to import objects.
The Fusion workspace appears.
2. Click **System > Import Fusion Objects**.
The Import Fusion Objects window opens.
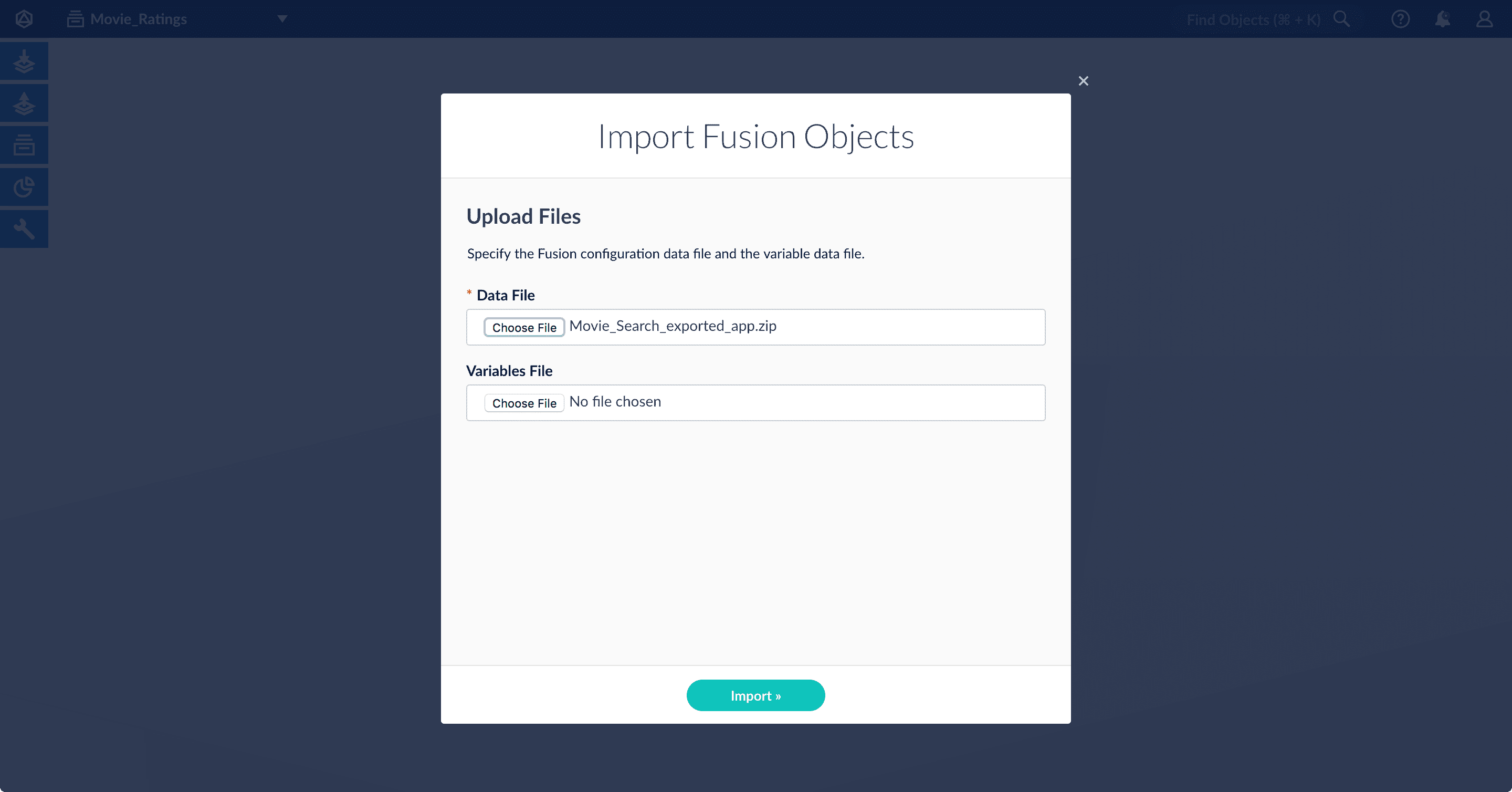 3. Select the data file from your local filesystem.
If you are importing [usernames and passwords](/api-reference/objects/import-objects) in a separate file, select it under **Variables File**.
4. Click **Import**.
If there are conflicts, Fusion prompts you to specify an import policy:
3. Select the data file from your local filesystem.
If you are importing [usernames and passwords](/api-reference/objects/import-objects) in a separate file, select it under **Variables File**.
4. Click **Import**.
If there are conflicts, Fusion prompts you to specify an import policy:
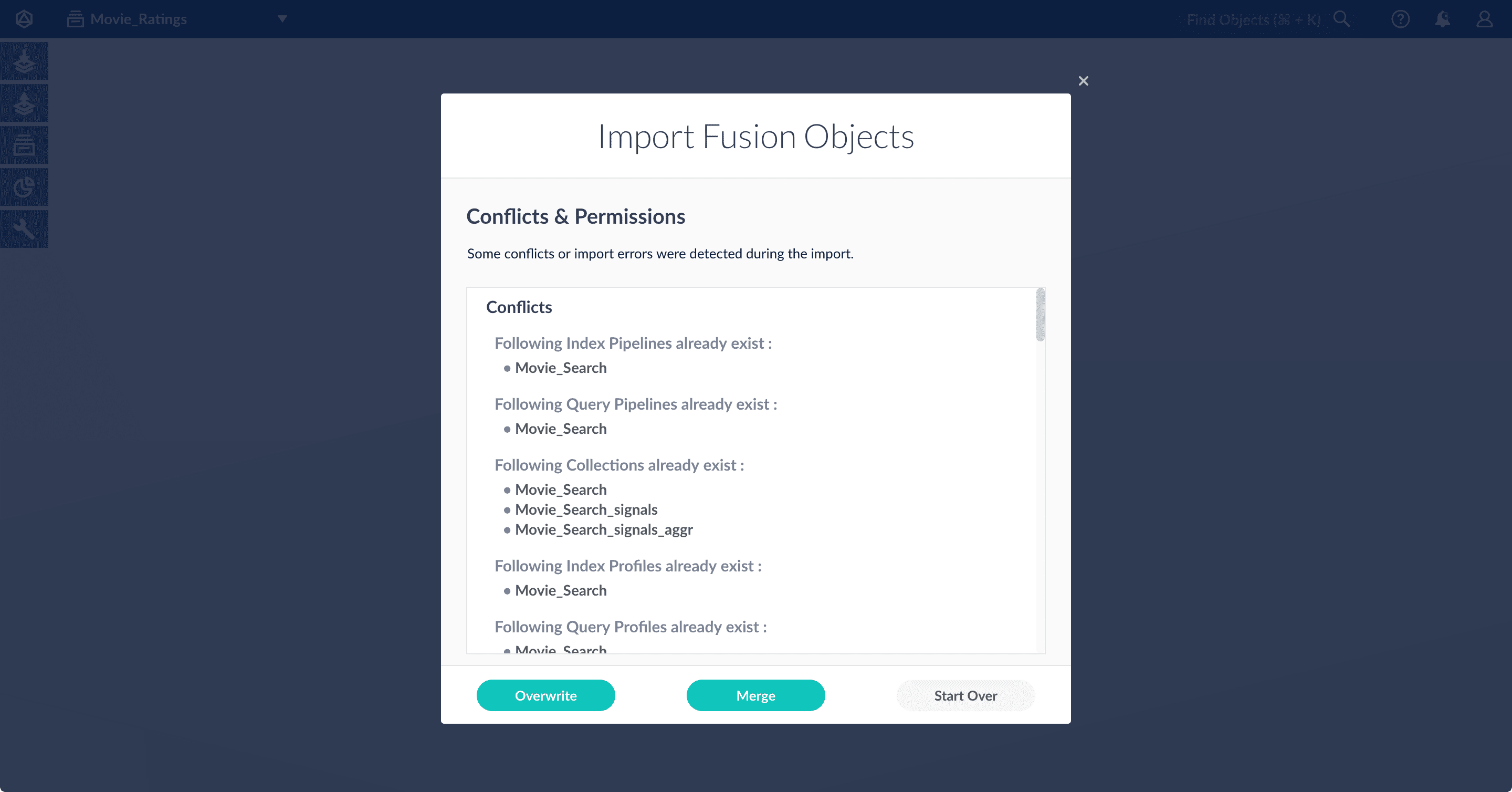 * Click **Overwrite** to overwrite the objects on the target system with the ones in the import file.
* Click **Merge** to skip all conflicting objects and import only the non-conflicting objects.
* Click **Start Over** to abort the import.
Fusion confirms that the import was successful:
* Click **Overwrite** to overwrite the objects on the target system with the ones in the import file.
* Click **Merge** to skip all conflicting objects and import only the non-conflicting objects.
* Click **Start Over** to abort the import.
Fusion confirms that the import was successful:
 5. Click **Close** to close the Import Fusion Objects window.
## Add an object to an app
You can add objects present in other apps (or in no apps) to the open app. Some objects are linked to other apps. You can also add those directly to an app.
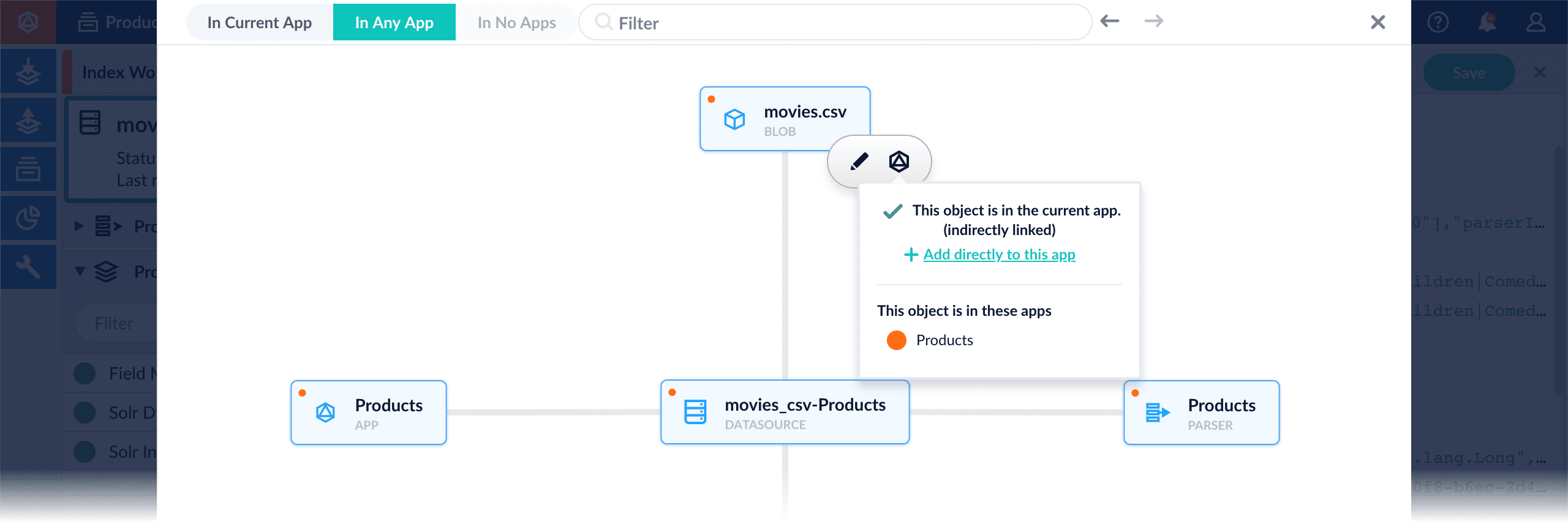
* **Add an object to an app** – While in the Fusion workspace for the app to which you want to add an object, open Object Explorer and click **In Any App**. Search for or browse to the object you want to add. Hover over the object, click the App
5. Click **Close** to close the Import Fusion Objects window.
## Add an object to an app
You can add objects present in other apps (or in no apps) to the open app. Some objects are linked to other apps. You can also add those directly to an app.
* **Add an object to an app** – While in the Fusion workspace for the app to which you want to add an object, open Object Explorer and click **In Any App**. Search for or browse to the object you want to add. Hover over the object, click the App 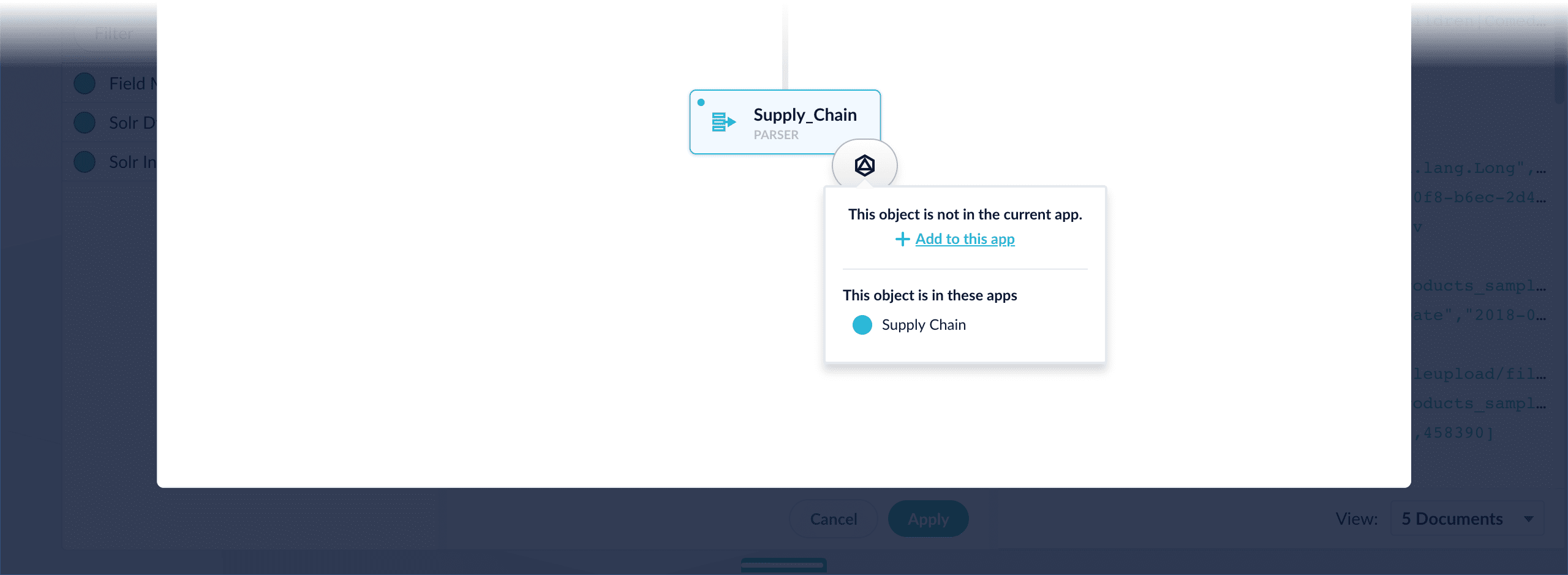 * **Add an object to an app directly** – In cases when an object is linked to an app, but is not linked directly to the app (it is linked via some dependency), you can add the object to an app directly.
While in the Fusion workspace for the app to which you want to add an object directly, open Object Explorer and click **In Any App**. Search for or browse to the object you want to add. Hover over the object, click the App
* **Add an object to an app directly** – In cases when an object is linked to an app, but is not linked directly to the app (it is linked via some dependency), you can add the object to an app directly.
While in the Fusion workspace for the app to which you want to add an object directly, open Object Explorer and click **In Any App**. Search for or browse to the object you want to add. Hover over the object, click the App