{description &&
{formatDescription(description)}
}
{visibleProps.map(([name, prop]) => {
const isRequired = requiredProps.includes(name);
const hasDefault = prop.default !== undefined;
const rawDefault = prop.default;
const isComplexDefault = hasDefault && (typeof rawDefault === "object" || typeof rawDefault === "string" && (rawDefault.length > 20 || rawDefault.includes('"')));
const fieldProps = {
key: name,
body: prop.title || name,
type: prop.type,
...prop.title && ({
post: [<>
API property: {name}]
}),
...isRequired && ({
required: true
}),
...!isComplexDefault && hasDefault ? {
default: sanitize(String(rawDefault))
} : {}
};
const isObject = prop.type === "object" && prop.properties;
const isArrayOfObjects = prop.type === "array" && prop.items?.type === "object" && prop.items.properties;
return
{prop.description && {formatDescription(prop.description)}
}
{isComplexDefault &&
Default:
{JSON.stringify(rawDefault, null, 2)}
}
{isArrayOfObjects &&
Object attributes:
{'{\n'}
{Object.entries(prop.items.properties).map(([iname, iprop]) => <>
{` ${iname}`}
{prop.items?.required?.includes(iname) && required}
{`: {\n display name: ${sanitize(iprop.title || '')}\n type: ${iprop.type}\n }\n`}
)}
{'}'}
}
{isObject &&
}
;
})}
 * Under **Channels and Messages Settings**, select *Index channels* and *Index from public channels*:
* Under **Channels and Messages Settings**, select *Index channels* and *Index from public channels*:
 4. Click **Save**.
5. Click **Run** to run the indexing job.
{/* [#configure-data-model] */}
## Configure the data model
Some connectors include built-in data models with pre-configured object types. However, you can add new data models or customize existing ones to fit your particular needs.
1. Navigate to **Indexing > Data Models**.
2. Click the **Add** button.
3. Create a new data model. For example, `person`.
4. Assign the index pipeline for the data model. In this example, create a new index pipeline named `companyDirectory-data-pipeline`.
This pipeline is ideally for operation with data models only. For the sake of this example, we will only be using the default stages. Applying additional logic/stages specific to the object would occur here.
5. Assign the query pipeline you will use to query the indexed documents. In this example, create a new query pipeline named `companyDirectory-query-pipeline`.
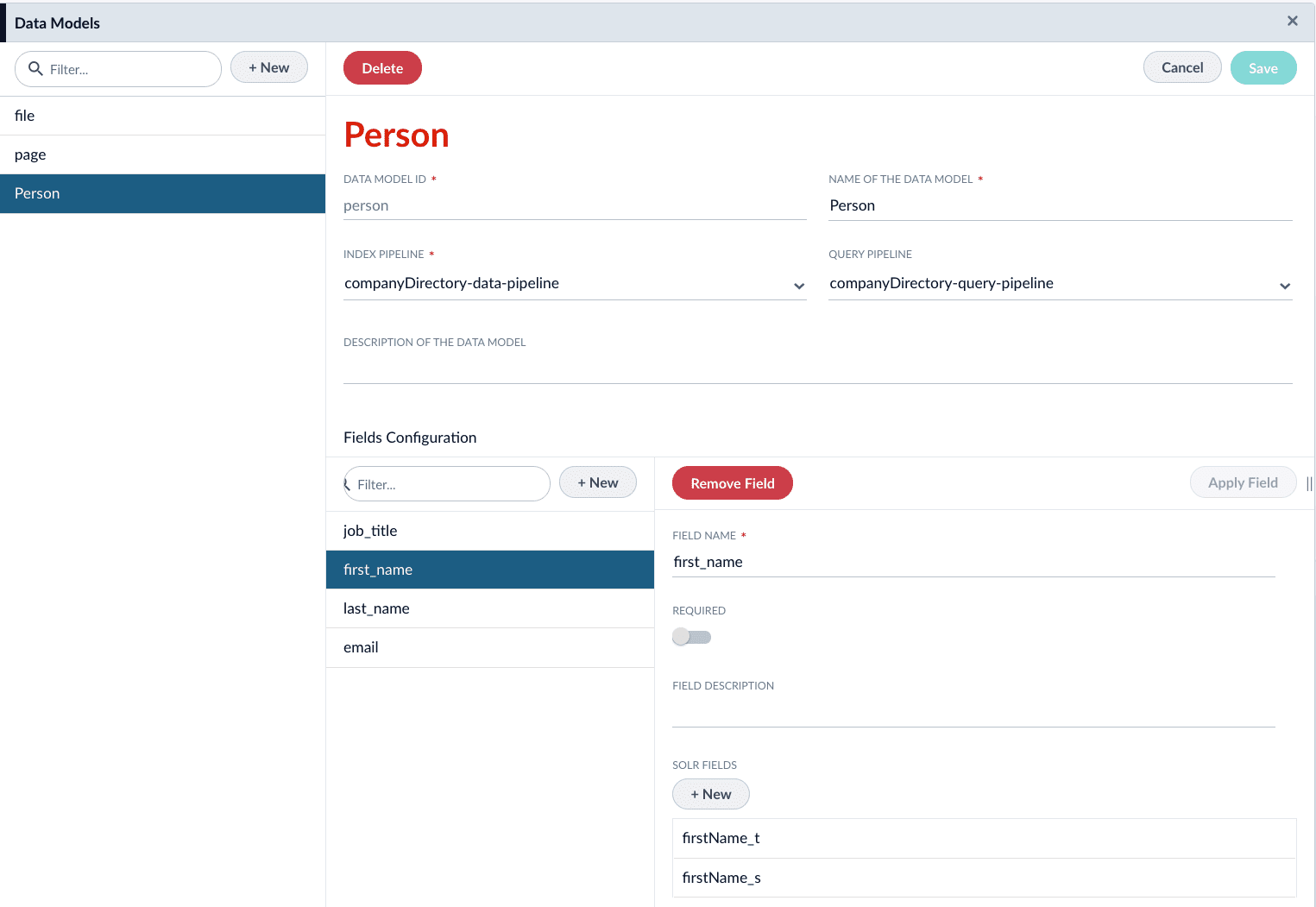
6. Click the **New** button under **Fields Configuration**.
7. Complete the required configurations, as detailed in [Data Models API Reference](/api-reference/data-models/get-data-models-service-status). Create fields for the following:
| Field Name | Solr Fields |
| ------------ | ---------------------------- |
| `first_name` | `firstName_t`, `firstName_s` |
| `last_name` | `lastName_t`, `lastName_s` |
| `email` | `email_s` |
| `job_title` | `jobTitle_t`, `jobTitle_s` |
4. Click **Save**.
5. Click **Run** to run the indexing job.
{/* [#configure-data-model] */}
## Configure the data model
Some connectors include built-in data models with pre-configured object types. However, you can add new data models or customize existing ones to fit your particular needs.
1. Navigate to **Indexing > Data Models**.
2. Click the **Add** button.
3. Create a new data model. For example, `person`.
4. Assign the index pipeline for the data model. In this example, create a new index pipeline named `companyDirectory-data-pipeline`.
This pipeline is ideally for operation with data models only. For the sake of this example, we will only be using the default stages. Applying additional logic/stages specific to the object would occur here.
5. Assign the query pipeline you will use to query the indexed documents. In this example, create a new query pipeline named `companyDirectory-query-pipeline`.
6. Click the **New** button under **Fields Configuration**.
7. Complete the required configurations, as detailed in [Data Models API Reference](/api-reference/data-models/get-data-models-service-status). Create fields for the following:
| Field Name | Solr Fields |
| ------------ | ---------------------------- |
| `first_name` | `firstName_t`, `firstName_s` |
| `last_name` | `lastName_t`, `lastName_s` |
| `email` | `email_s` |
| `job_title` | `jobTitle_t`, `jobTitle_s` |
 8. If needed, edit the JSON for the data model before saving. After saving the data model, this JSON viewer becomes read-only.
8. If needed, edit the JSON for the data model before saving. After saving the data model, this JSON viewer becomes read-only.
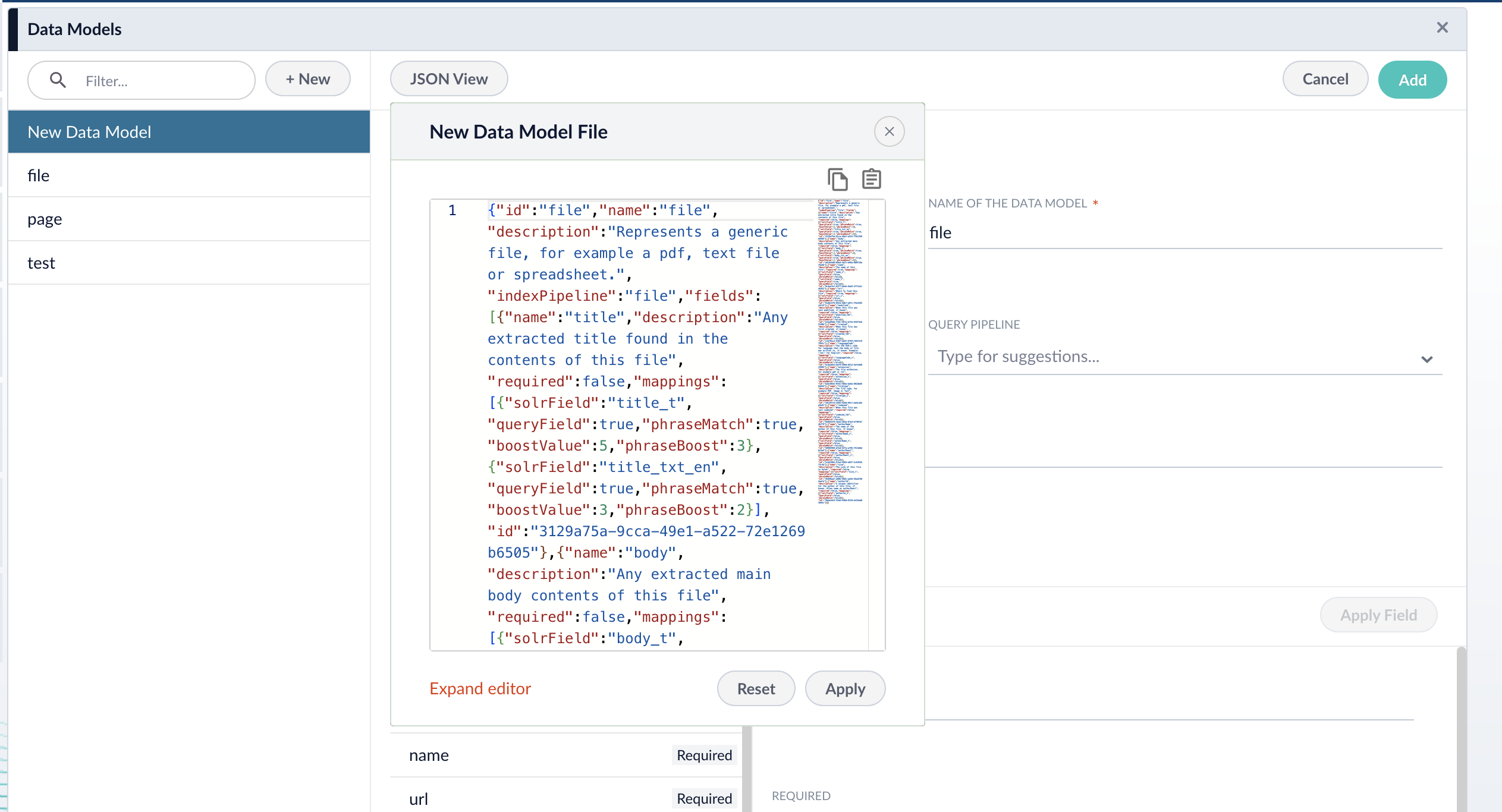 9. Click the **Save** button to save the data model.
## Configure the index pipeline
To begin, navigate to **Indexing > Index Workbench**. Alternatively, the `companyDirectory-index-pipeline` pipeline can be configured in **Indexing > Index Pipelines**, but you are not able to preview results.
9. Click the **Save** button to save the data model.
## Configure the index pipeline
To begin, navigate to **Indexing > Index Workbench**. Alternatively, the `companyDirectory-index-pipeline` pipeline can be configured in **Indexing > Index Pipelines**, but you are not able to preview results.