> ## Documentation Index
> Fetch the complete documentation index at: https://doc.lucidworks.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Fusion 5.9.13
> June 17, 2025
export const InlineImage = ({src, alt = '', height = '2em'}) => {
return  ;
};
[localhost link]: http://localhost:3000/docs/5/fusion/release-notes/5.9.13-release-notes
[mintlify link]: https://doc.lucidworks.com/docs/5/fusion/release-notes/5.9.13-release-notes
[old doc.lw link]: https://doc.lucidworks.com/fusion/5.9/4dtlz0
Fusion 5.9.13 is a
[maintenance release](/docs/policies/lifecycle-policies/lw-version-support-lifecycle#maintenance-release-support-policy) that introduces
advanced SKU grouping with Solr collapse, custom certificates for indexing and querying services, and compatibility with Kubernetes 1.32.
Fusion 5.9.13 also improves authentication resilience with a configurable JWT timeout, and resolves key scheduling and security bugs to ensure greater stability and compliance in enterprise environments.
**Security patch available for api-gateway: Netty request smuggling vulnerabilities**
A patch is available for the `api-gateway` service to address critical Netty request smuggling vulnerabilities (CVE-2026-42581, CVE-2026-42585, CVE-2026-42587). These vulnerabilities allow attackers to smuggle HTTP requests through the gateway, potentially bypassing security controls.
The `api-gateway` service requires the Netty security patch.
Follow these steps to apply the patched image:
1. Open your Fusion Helm values file.
2. Add or update the `api-gateway` image configuration:
```yaml theme={"dark"}
api-gateway:
image:
repository: lucidworks
name: api-gateway
tag: 5.9.13-SUST-1634-patch
imagePullPolicy: IfNotPresent
```
3. Save the values file.
4. For Fusion Cloud Native deployments, run the `upgrade_fusion.sh` script you used for your current deployment. For Helm deployments, run:
```bash theme={"dark"}
helm upgrade --namespace NAMESPACE RELEASE_NAME PATH_TO_VALUES
```
Replace `NAMESPACE` with your Kubernetes namespace, `RELEASE_NAME` with your Helm release name, and `PATH_TO_VALUES` with the path to your updated values file.
5. Wait for the `api-gateway` pods to restart and verify they are using the patched image.
**Urgent action required by November 26, 2025**
A patch is required by November 26, 2025 for all self-hosted Fusion deployments running on Amazon Elastic Kubernetes Service (EKS). Certain Java versions used by Fusion components reach end of life on this date. Failure to apply the patch will result in compatibility issues.
The following Fusion services require the `cgroupv2` patch:
| Service | Affected Fusion versions | Patch tag |
| ---------------- | ------------------------ | ---------------------------------------------- |
| `insights` | 5.9.4 to 5.9.15 | `lucidworks/insights:5.9-cgroupv2-patch` |
| `spark-solr-etl` | 5.9.4 to 5.9.11 | `lucidworks/spark-solr-etl:5.9-cgroupv2-patch` |
| `keytool-utils` | 5.9.4 to 5.9.10 | `lucidworks/keytool-utils:5.9-cgroupv2-patch` |
Follow these steps to apply the patched images:
1. Open your Fusion Helm values file. For Fusion Cloud Native deployments, use the values file for your current deployment. For Helm deployments, use the values file you used to create the deployment.
2. For each service listed in the following table that applies to your Fusion version, add or update the image configuration:
Expand the following code snippet for the complete image configuration list.
```yaml expandable theme={"dark"}
global:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
sql-service:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
reverse-search:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
solr:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
zookeeper:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
kafka:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
zookeeper:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
ml-model-service:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
fusion-admin:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
fusion-indexing:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
query-pipeline:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
async-parsing:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
admin-ui:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
api-gateway:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
auth-ui:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
classic-rest-service:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
fusion-resources:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
job-config:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
insights:
image:
imagePullPolicy: Always
name: insights
repository: lucidworks
tag: 5.9-cgroupv2-patch
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
job-launcher:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
job-rest-server:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
connectors:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
connector-plugin:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
connectors-backend:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
rules-ui:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
pm-ui:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
lwai-gateway:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
webapps:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
apps-manager:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
templating:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
tikaserver:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
argo:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
seldon-core-operator:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
argo-common-workflows:
image:
imagePullPolicy: Always
repository: lucidworks
sparkSolrEtlTag: 5.9-cgroupv2-patch
utilitiesTag: 5.9.11
```
```yaml theme={"dark"}
insights:
image:
name: insights
pullPolicy: IfNotPresent
repository: lucidworks
tag: 5.9-cgroupv2-patch
argo-common-workflows:
image:
imagePullPolicy: IfNotPresent
repository: lucidworks
sparkSolrEtlTag: 5.9-cgroupv2-patch
```
```yaml theme={"dark"}
insights:
image:
name: insights
pullPolicy: IfNotPresent
repository: lucidworks
tag: insights:5.9-cgroupv2-patch
```
3. Save the values file.
4. For Fusion Cloud Native deployments, run the `upgrade_fusion.sh` script you used for your current deployment. For Helm deployments, run the following command:
```bash theme={"dark"}
helm upgrade --namespace NAMESPACE RELEASE_NAME PATH_TO_VALUES
```
Replace `NAMESPACE` with your Kubernetes namespace. Replace `RELEASE_NAME` with your Helm release name. Replace `PATH_TO_VALUES` with the path to your updated values file.
5. Wait for the affected service pods to restart and verify they are using the patched images.
**Looking to upgrade?**
See [Fusion 5 Upgrades](/docs/5/fusion/operations/fusion-5-upgrades) for detailed instructions.
Fusion 5.9.5 introduced changes that affect Spark jobs. If you are upgrading from any Fusion version earlier than 5.9.5 to a version later than 5.9.5, Lucidworks recommends first upgrading to Fusion 5.9.5 before proceeding to the target version.
For supported Kubernetes versions and key component versions, see [Platform support and component versions](#platform-support-and-component-versions).
## What’s new
### Unidirectional multi-region Solr for self hosted Fusion (CrossDC)
This release introduces built-in support for Apache Solr's CrossDC (Cross Data Center) replication framework, enabling seamless uni-directional synchronization of Solr updates between data centers.
This feature is now integrated into Fusion's packaging to reduce the operational complexity and cost of implementing high availability and disaster recovery in self-hosted environments.
With CrossDC, Solr update requests (including indexing, collection, and configset changes) from a primary cluster are mirrored to a secondary cluster using Apache Kafka.
The new support includes:
* A preconfigured Solr plugin for mirroring updates directly from the source Fusion cluster
* A dedicated CrossDC consumer application for replaying those updates on the target cluster
* Centralized configuration support with Solr ZooKeeper
* Optional dead-letter queue handling for failed requests
* Support for selective replication using command whitelisting
This update eliminates the need for custom configuration to enable CrossDC and ensures Fusion is ready for geo-redundant or hybrid-cloud architectures out of the box.
For complete details, see [Cross Data Center Replication](/docs/5/fusion/operations/solr-crossdc).
This initial release supports uni-directional replication only, from a source to a target Solr cluster.
### Expanded support for collapsed search results
Now Fusion gives you access to all of the available Solr settings for collapsing search results, giving you finer control over how Fusion groups variations of each item into a single search result.
You can use collapse to improve conversion rates and customer satisfaction by streamlining search results, reducing cognitive load, and surfacing the most relevant product variations first.
For example, you can use a `product_id` field as the collapse field to group all versions or SKUs of a product into a single search result.
You can also control how Fusion selects the variation that represents the collapsed group; the default is the one most relevant to the user’s query.
For example, a user who searches for "red shoes" sees all of the red variations of shoes first, with the option to drill down and see all the variations.
;
};
[localhost link]: http://localhost:3000/docs/5/fusion/release-notes/5.9.13-release-notes
[mintlify link]: https://doc.lucidworks.com/docs/5/fusion/release-notes/5.9.13-release-notes
[old doc.lw link]: https://doc.lucidworks.com/fusion/5.9/4dtlz0
Fusion 5.9.13 is a
[maintenance release](/docs/policies/lifecycle-policies/lw-version-support-lifecycle#maintenance-release-support-policy) that introduces
advanced SKU grouping with Solr collapse, custom certificates for indexing and querying services, and compatibility with Kubernetes 1.32.
Fusion 5.9.13 also improves authentication resilience with a configurable JWT timeout, and resolves key scheduling and security bugs to ensure greater stability and compliance in enterprise environments.
**Security patch available for api-gateway: Netty request smuggling vulnerabilities**
A patch is available for the `api-gateway` service to address critical Netty request smuggling vulnerabilities (CVE-2026-42581, CVE-2026-42585, CVE-2026-42587). These vulnerabilities allow attackers to smuggle HTTP requests through the gateway, potentially bypassing security controls.
The `api-gateway` service requires the Netty security patch.
Follow these steps to apply the patched image:
1. Open your Fusion Helm values file.
2. Add or update the `api-gateway` image configuration:
```yaml theme={"dark"}
api-gateway:
image:
repository: lucidworks
name: api-gateway
tag: 5.9.13-SUST-1634-patch
imagePullPolicy: IfNotPresent
```
3. Save the values file.
4. For Fusion Cloud Native deployments, run the `upgrade_fusion.sh` script you used for your current deployment. For Helm deployments, run:
```bash theme={"dark"}
helm upgrade --namespace NAMESPACE RELEASE_NAME PATH_TO_VALUES
```
Replace `NAMESPACE` with your Kubernetes namespace, `RELEASE_NAME` with your Helm release name, and `PATH_TO_VALUES` with the path to your updated values file.
5. Wait for the `api-gateway` pods to restart and verify they are using the patched image.
**Urgent action required by November 26, 2025**
A patch is required by November 26, 2025 for all self-hosted Fusion deployments running on Amazon Elastic Kubernetes Service (EKS). Certain Java versions used by Fusion components reach end of life on this date. Failure to apply the patch will result in compatibility issues.
The following Fusion services require the `cgroupv2` patch:
| Service | Affected Fusion versions | Patch tag |
| ---------------- | ------------------------ | ---------------------------------------------- |
| `insights` | 5.9.4 to 5.9.15 | `lucidworks/insights:5.9-cgroupv2-patch` |
| `spark-solr-etl` | 5.9.4 to 5.9.11 | `lucidworks/spark-solr-etl:5.9-cgroupv2-patch` |
| `keytool-utils` | 5.9.4 to 5.9.10 | `lucidworks/keytool-utils:5.9-cgroupv2-patch` |
Follow these steps to apply the patched images:
1. Open your Fusion Helm values file. For Fusion Cloud Native deployments, use the values file for your current deployment. For Helm deployments, use the values file you used to create the deployment.
2. For each service listed in the following table that applies to your Fusion version, add or update the image configuration:
Expand the following code snippet for the complete image configuration list.
```yaml expandable theme={"dark"}
global:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
sql-service:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
reverse-search:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
solr:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
zookeeper:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
kafka:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
zookeeper:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
ml-model-service:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
fusion-admin:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
fusion-indexing:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
query-pipeline:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
async-parsing:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
admin-ui:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
api-gateway:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
auth-ui:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
classic-rest-service:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
fusion-resources:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
job-config:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
insights:
image:
imagePullPolicy: Always
name: insights
repository: lucidworks
tag: 5.9-cgroupv2-patch
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
job-launcher:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
job-rest-server:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
connectors:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
connector-plugin:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
connectors-backend:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
rules-ui:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
pm-ui:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
lwai-gateway:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
webapps:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
apps-manager:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
templating:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
tikaserver:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
argo:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
seldon-core-operator:
keytoolUtils:
image:
repository: lucidworks
name: "keytool-utils"
tag: "5.9-cgroupv2-patch"
imagePullPolicy: "IfNotPresent"
argo-common-workflows:
image:
imagePullPolicy: Always
repository: lucidworks
sparkSolrEtlTag: 5.9-cgroupv2-patch
utilitiesTag: 5.9.11
```
```yaml theme={"dark"}
insights:
image:
name: insights
pullPolicy: IfNotPresent
repository: lucidworks
tag: 5.9-cgroupv2-patch
argo-common-workflows:
image:
imagePullPolicy: IfNotPresent
repository: lucidworks
sparkSolrEtlTag: 5.9-cgroupv2-patch
```
```yaml theme={"dark"}
insights:
image:
name: insights
pullPolicy: IfNotPresent
repository: lucidworks
tag: insights:5.9-cgroupv2-patch
```
3. Save the values file.
4. For Fusion Cloud Native deployments, run the `upgrade_fusion.sh` script you used for your current deployment. For Helm deployments, run the following command:
```bash theme={"dark"}
helm upgrade --namespace NAMESPACE RELEASE_NAME PATH_TO_VALUES
```
Replace `NAMESPACE` with your Kubernetes namespace. Replace `RELEASE_NAME` with your Helm release name. Replace `PATH_TO_VALUES` with the path to your updated values file.
5. Wait for the affected service pods to restart and verify they are using the patched images.
**Looking to upgrade?**
See [Fusion 5 Upgrades](/docs/5/fusion/operations/fusion-5-upgrades) for detailed instructions.
Fusion 5.9.5 introduced changes that affect Spark jobs. If you are upgrading from any Fusion version earlier than 5.9.5 to a version later than 5.9.5, Lucidworks recommends first upgrading to Fusion 5.9.5 before proceeding to the target version.
For supported Kubernetes versions and key component versions, see [Platform support and component versions](#platform-support-and-component-versions).
## What’s new
### Unidirectional multi-region Solr for self hosted Fusion (CrossDC)
This release introduces built-in support for Apache Solr's CrossDC (Cross Data Center) replication framework, enabling seamless uni-directional synchronization of Solr updates between data centers.
This feature is now integrated into Fusion's packaging to reduce the operational complexity and cost of implementing high availability and disaster recovery in self-hosted environments.
With CrossDC, Solr update requests (including indexing, collection, and configset changes) from a primary cluster are mirrored to a secondary cluster using Apache Kafka.
The new support includes:
* A preconfigured Solr plugin for mirroring updates directly from the source Fusion cluster
* A dedicated CrossDC consumer application for replaying those updates on the target cluster
* Centralized configuration support with Solr ZooKeeper
* Optional dead-letter queue handling for failed requests
* Support for selective replication using command whitelisting
This update eliminates the need for custom configuration to enable CrossDC and ensures Fusion is ready for geo-redundant or hybrid-cloud architectures out of the box.
For complete details, see [Cross Data Center Replication](/docs/5/fusion/operations/solr-crossdc).
This initial release supports uni-directional replication only, from a source to a target Solr cluster.
### Expanded support for collapsed search results
Now Fusion gives you access to all of the available Solr settings for collapsing search results, giving you finer control over how Fusion groups variations of each item into a single search result.
You can use collapse to improve conversion rates and customer satisfaction by streamlining search results, reducing cognitive load, and surfacing the most relevant product variations first.
For example, you can use a `product_id` field as the collapse field to group all versions or SKUs of a product into a single search result.
You can also control how Fusion selects the variation that represents the collapsed group; the default is the one most relevant to the user’s query.
For example, a user who searches for "red shoes" sees all of the red variations of shoes first, with the option to drill down and see all the variations.
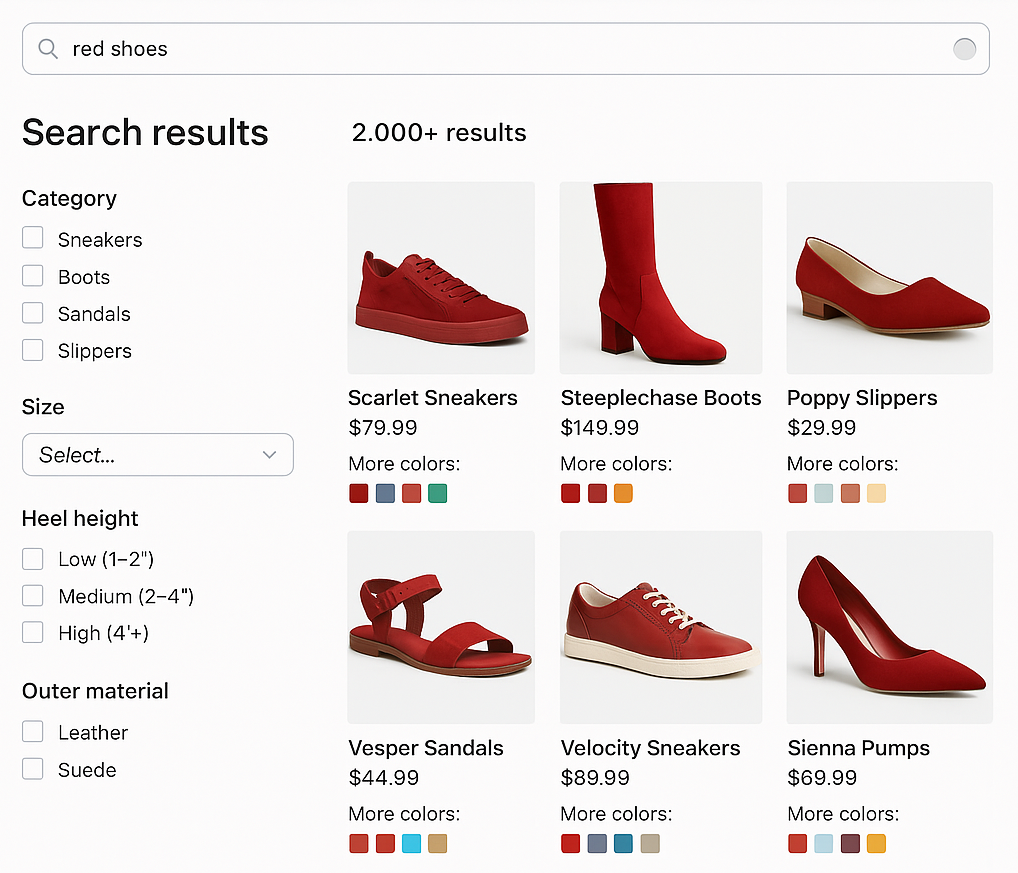 Additional capabilities include:
* **Faceting compatibility**: Facets can reflect counts based on collapsed groups instead of individual SKUs.
* **Sorting options**: Choose how the representative SKU is selected using sort fields like `sales_rank` or `popularity_score`.
* **Expand support**: Optional expansion of collapsed groups allows users to see all SKUs for a product on demand.
* **Commerce Studio integration**: Merchandising actions such as pinning, boosting, and burying now apply to the entire product group, not just individual SKUs.
* **Query Workbench support**: You can preview collapsed and expanded result sets directly in Query Workbench for easy validation.
This update eliminates the need for custom collapse implementations and makes SKU/product rollup behavior a first-class capability in Fusion.
For complete details about the new configuration options, see the [Query Fields stage](/docs/5/fusion/reference/config-ref/pipeline-stages/query-stages/search-fields-query-stage) configuration reference.
### Kubernetes 1.32 support for better security and long-term compatibility
Fusion 5.9.13 introduces full compatibility with Kubernetes version 1.32, ensuring seamless deployment and operation on the latest Kubernetes platforms.
This update allows you to take advantage of the latest stability, performance, and security improvements in Kubernetes, including better control over sidecar container behavior and improvements to admission webhooks and scheduling logic.
By supporting Kubernetes 1.32, Fusion stays aligned with cloud provider upgrades and helps future-proof your infrastructure, especially on managed services like AKS, EKS, and GKE.
### Improved JWT authentication resilience with configurable timeout
Fusion now allows you to configure the `jwkSetTimeout` variable in the JWT Realm settings, enabling better control over how long Fusion waits for a response when retrieving a JSON Web Key (JWK) set.
This improves authentication reliability in environments where key providers may respond slowly.
By increasing the default 500 ms timeout as needed (for example, to 2000 ms), you can reduce the risk of failed authentication due to network latency or external service delays.
You can configure this in the Fusion UI under the **System > Access Control > Security Realms** tab.
Alternatively, you can set this in the `security.initial-realm-configs` spring boot properties:
```yml theme={"dark"}
security:
initial-realm-configs:
realmType: jwt
enabled: true
name: jwt_okta
config:
autoCreateUsers: true
jwtIssuer: https://HOSTNAME/oauth2/default
jwkSetUri: https://HOSTNAME/oauth2/default/v1/keys
jwkSetTimeout: 2000
roleNames:
- developer
```
### Configurable vector quantization method in LWAI pipeline stages
Fusion 5.9.13 adds vector quantization in certain Lucidworks AI (LWAI) pipeline stages, making it easier to reduce memory usage and accelerate vector search without sacrificing quality.
Quantization converts high-precision float vectors into compact 8-bit integer vectors, significantly lowering storage and compute costs.
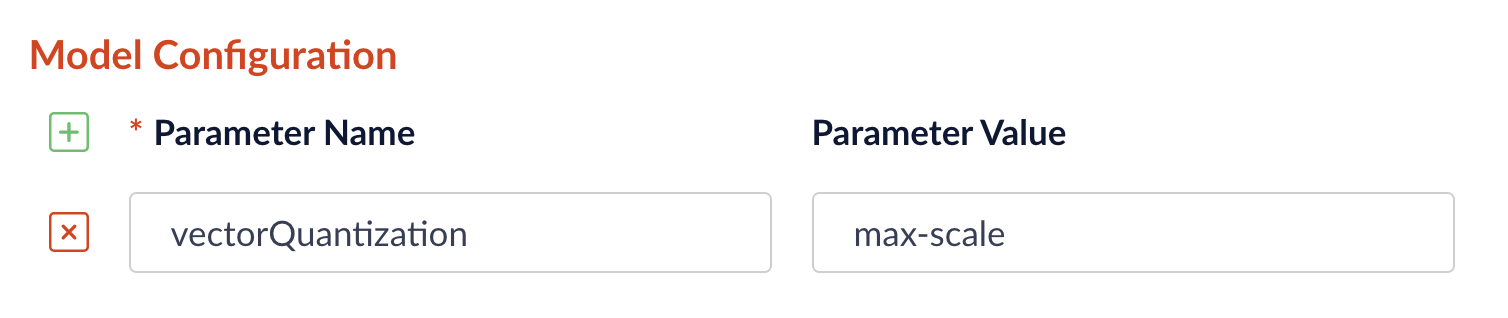
Now you can choose between `min-max` or `max-scale` quantization methods directly in the pipeline configuration interface for the LWAI vectorization stages:
* [LWAI Vectorize Field Index stage](/docs/5/fusion/reference/config-ref/pipeline-stages/index-stages/lwai-vectorize-field)
* [LWAI Vectorize Query Stage](/docs/5/fusion/reference/config-ref/pipeline-stages/query-stages/lwai-vectorize-query)
To select the quantization method, go to **Model Config** in the LWAI pipeline stage configuration and enter the `vectorQuantizationMethod` parameter with the value for the desired method:
Additional capabilities include:
* **Faceting compatibility**: Facets can reflect counts based on collapsed groups instead of individual SKUs.
* **Sorting options**: Choose how the representative SKU is selected using sort fields like `sales_rank` or `popularity_score`.
* **Expand support**: Optional expansion of collapsed groups allows users to see all SKUs for a product on demand.
* **Commerce Studio integration**: Merchandising actions such as pinning, boosting, and burying now apply to the entire product group, not just individual SKUs.
* **Query Workbench support**: You can preview collapsed and expanded result sets directly in Query Workbench for easy validation.
This update eliminates the need for custom collapse implementations and makes SKU/product rollup behavior a first-class capability in Fusion.
For complete details about the new configuration options, see the [Query Fields stage](/docs/5/fusion/reference/config-ref/pipeline-stages/query-stages/search-fields-query-stage) configuration reference.
### Kubernetes 1.32 support for better security and long-term compatibility
Fusion 5.9.13 introduces full compatibility with Kubernetes version 1.32, ensuring seamless deployment and operation on the latest Kubernetes platforms.
This update allows you to take advantage of the latest stability, performance, and security improvements in Kubernetes, including better control over sidecar container behavior and improvements to admission webhooks and scheduling logic.
By supporting Kubernetes 1.32, Fusion stays aligned with cloud provider upgrades and helps future-proof your infrastructure, especially on managed services like AKS, EKS, and GKE.
### Improved JWT authentication resilience with configurable timeout
Fusion now allows you to configure the `jwkSetTimeout` variable in the JWT Realm settings, enabling better control over how long Fusion waits for a response when retrieving a JSON Web Key (JWK) set.
This improves authentication reliability in environments where key providers may respond slowly.
By increasing the default 500 ms timeout as needed (for example, to 2000 ms), you can reduce the risk of failed authentication due to network latency or external service delays.
You can configure this in the Fusion UI under the **System > Access Control > Security Realms** tab.
Alternatively, you can set this in the `security.initial-realm-configs` spring boot properties:
```yml theme={"dark"}
security:
initial-realm-configs:
realmType: jwt
enabled: true
name: jwt_okta
config:
autoCreateUsers: true
jwtIssuer: https://HOSTNAME/oauth2/default
jwkSetUri: https://HOSTNAME/oauth2/default/v1/keys
jwkSetTimeout: 2000
roleNames:
- developer
```
### Configurable vector quantization method in LWAI pipeline stages
Fusion 5.9.13 adds vector quantization in certain Lucidworks AI (LWAI) pipeline stages, making it easier to reduce memory usage and accelerate vector search without sacrificing quality.
Quantization converts high-precision float vectors into compact 8-bit integer vectors, significantly lowering storage and compute costs.
Now you can choose between `min-max` or `max-scale` quantization methods directly in the pipeline configuration interface for the LWAI vectorization stages:
* [LWAI Vectorize Field Index stage](/docs/5/fusion/reference/config-ref/pipeline-stages/index-stages/lwai-vectorize-field)
* [LWAI Vectorize Query Stage](/docs/5/fusion/reference/config-ref/pipeline-stages/query-stages/lwai-vectorize-query)
To select the quantization method, go to **Model Config** in the LWAI pipeline stage configuration and enter the `vectorQuantizationMethod` parameter with the value for the desired method:
 ### Custom certificates for indexing and querying services
Fusion 5.9.13 introduces the ability add custom certificates for indexing and querying services, making it easier to align to your organization’s specific security requirements. This feature allows a Helm chart update to support persistent custom certificates and adding them into truststores during pod startup.
To add a custom certificate, create a new YAML file for your custom certificates and edit it to include your indexing or querying certificates. You must use different YAML files in order to use different certificates for indexing and querying services. See **Deploy Fusion at Scale** for full instructions, including the Helm chart update.
Before you begin, see [Fusion Server Deployment](/docs/5/fusion/operations/deployment) to understand the architecture and requirements.
This article explains how to plan and execute a Fusion deployment at the scale required for staging or production.
While the `setup_f5_*.sh` scripts are handy for getting started and proof-of-concept purposes, this article covers the planning process for building a production-ready environment.
The course for **Preparing for Fusion Implementation** focuses on the key elements for a successful implementation, defining your business requirements, preparing clean data, and involving the right personnel.
## Prerequisites
You must meet the following prerequisites before you can customize your Fusion cluster:
* A local copy of the [fusion-cloud-native repository](https://github.com/lucidworks/fusion-cloud-native). This must be up-to-date with the latest master branch.
* Any cloud provider-specific **command line tools**, such as `gcloud` or `aws`, and `kubectl`.\
See the platform-specific instructions linked above, or check with your cloud provider.
* Helm v3
* To install on a Mac:
```bash theme={"dark"}
brew upgrade kubernetes-helm
```
* For other operating systems, download from [Helm Releases](https://github.com/helm/helm/releases).
* Verify your installation:
```bash theme={"dark"}
helm version --short
v3.0.0+ge29ce2a
```
* Kubernetes namespace
* Collect the following information about your Kubernetes environment:
* **CLUSTER**: Cluster name (passed to our setup scripts using the `-c` arg)
* **NAMESPACE**: Kubernetes namespace where to install Fusion; a namespace should only contain lowercase letters (a-z), digits (0-9), or dash. No periods or underscores allowed.
* *(optional)* Clarify your organization’s DockerHub policy. The Fusion Helm chart points to public Docker images on DockerHub. Your organization may not allow Kubernetes to pull images directly from DockerHub or may require extra security scanning before loading images into production clusters.\
Consult your Kubernetes and Docker admin team to find how to get the Fusion images loaded into a registry that’s accessible to your cluster. You can update the image for each service using the [custom values YAML file](#custom-values-yaml-file).
**Kubernetes namespace tips**
* Fusion 5 service discovery requires all services for the same release be deployed in the same namespace. Moreover, you should only run one instance of Fusion in a namespace. If you need multiple instances of Fusion running in the same Kubernetes cluster, then you need to deploy them in separate namespaces.
* If your organization requires CPU / Memory quotas for namespaces, you can start with a minimum of 12 CPU and 45GB of RAM (such as 3 x n1-standard-4 on GKE), but you will need to increase the quotas once you start load testing Fusion with production workloads and real datasets.
* Fusion requires at least 3 ZooKeeper nodes and 2 Solr nodes to achieve high availability.
## Custom values YAML file
1. Clone the `fusion-cloud-native` repository: `git clone https://github.com/lucidworks/fusion-cloud-native`
2. Run the `customize_fusion_values.sh` script.
```bash theme={"dark"}
./customize_fusion_values.sh --provider -c -n \
--num-solr 3 \
--solr-disk-gb 100 \
--node-pool \
--prometheus true \
--with-resource-limits \
--with-affinity-rules
```
Pass the `--help` parameter to see script usage details.
The script creates the following files:
| File | Description |
| --------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------ |
| `___fusion_values.yaml` | Main custom values YAML used to override Helm chart defaults for Fusion microservices. |
| `___monitoring_values.yaml` | Custom values yaml used to configure Prometheus and Grafana. |
| `___fusion_resources.yaml` | Resource requests and limits for all Microservices. |
| `___fusion_affinity.yaml` | Pod affinity rules to ensure multiple replicas for a single service are evenly distributed across zones and nodes. |
| `___upgrade_fusion.sh` | Script used to install and/or upgrade Fusion using the aforementioned custom values YAML files. |
For an explanation of these placeholder values, see [Configuration Values](#custom-values-yaml-file) below.
3. Add the new files to version control. You will make changes to it over time as you fine-tune your Fusion installation. You will also need it to perform upgrades. If you try to upgrade your Fusion installation and don’t provide the custom values YAML, your deployment will revert to chart defaults.\
Review the `___fusion_values.yaml` file to familiarize yourself with its structure and contents. Notice it contains a separate section for each of the Fusion microservices. The example configuration of the `query-pipeline` service below illustrates some important concepts about the custom values YAML file.
```yaml highlight={1,2,3,5,6} theme={"dark"}
query-pipeline:
enabled: true
nodeSelector:
cloud.google.com/gke-nodepool: default-pool
javaToolOptions: "..."
pod:
annotations:
prometheus.io/port: "8787"
prometheus.io/scrape: "true"
prometheus.io/path: "/actuator/prometheus"
```
4. Service-specific setting overrides under the top-level heading
5. Every Fusion service has an implicit enabled flag that defaults to true, set to false to remove this service from your cluster
6. Node selector identifies the label find nodes to schedule pods on
7. Used to pass JVM options to the service
8. Pod annotations to allow Prometheus to scrape metrics from the service
Once we go through all of the configuration topics in this topic, you’ll have a well-configured custom values YAML file for your Fusion 5 installation. You’ll then use this file during the Helm v3 installation at the end of this topic.
### Deployment-specific values
The script creates a custom values YAML file using the naming convention: `___fusion_values.yaml`. For example, `gke_search_f5_fusion_values.yaml`.
| Parameter | Description |
| ----------------- | -------------------------------------------------------------------------- |
| `` | The K8s platform you’re running on, such as `gke`. |
| `` | The name of your cluster. |
| `` | The K8s namespace where you want to install Fusion. |
| `` | Specifies a `nodeSelector` label to find nodes to schedule Fusion pods on. |
Providing the correct `--node-pool ` label is very important. Using the wrong value will cause your pods to be stuck in the `pending` state. If you’re not sure about the correct value for your cluster, pass ’{}'\` to let Kubernetes decide which nodes to schedule Fusion pods on.
Default `nodeSelector` labels are provider-specific. The `fusion-cloud-native` scripts use the following defaults for GKE and EKS:
| Provider | Default node selector |
| -------- | ------------------------------------------------ |
| GKE | cloud.google.com/gke-nodepool: default-pool |
| EKS | alpha.eksctl.io/nodegroup-name: standard-workers |
If you are deploying Fusion 5.9.12, add the following to your `values.yaml` file to avoid a known issue that prevents the `kuberay-operator` pod from launching successfully: `yaml kuberay-operator: crd: create: true `
### Flags
The script provides flags for additional configuration:
| Flag | Description |
| ------------------------ | ------------------------------------------------- |
| `--node-pool` | Add a Fusion specific label to your nodes. |
| `--with-resource-limits` | Configure resource requests/limits. |
| `--with-replicas` | Configure replica counts. |
| `--with-affinity-rules` | Configure pod affinity rules for Fusion services. |
Use `--node-pool` to add a Fusion specific label to your nodes by doing:
```bash theme={"dark"}
kubectl label fusion_node_type=
```
Then, pass `--node-pool 'fusion_node_type: '`.
## Configure Solr sizing
When you’re ready to build a production-ready setup for Fusion 5, you need to customize the Fusion Helm chart to ensure Fusion is well-configured for production workloads.
You’ll be able to scale the number of nodes for Solr up and down after building the cluster, but you need to establish the initial size of the nodes (memory and CPU) and the size and type of disks you need.
See the example config below to learn which parameters to change in the custom values YAML file.
```yaml expandable theme={"dark"}
solr:
resources: # Set resource limits for Solr to help K8s pod scheduling;
limits: # these limits are not just for the Solr process in the pod,
cpu: "7700m" # so allow ample memory for loading index files into the OS cache (mmap)
memory: "26Gi"
requests:
cpu: "7000m"
memory: "25Gi"
logLevel: WARN
nodeSelector:
fusion_node_type: search # Run this Solr StatefulSet in the "search" node pool
exporter:
enabled: true # Enable the Solr metrics exporter (for Prometheus) and
# schedule on the default node pool (system partition)
podAnnotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9983"
prometheus.io/path: "/metrics"
nodeSelector:
cloud.google.com/gke-nodepool: default-pool
image:
tag: 8.4.1
updateStrategy:
type: "RollingUpdate"
javaMem: "-Xmx3g -Dfusion_node_type=system" # Configure memory settings for Solr
solrGcTune: "-XX:+UseG1GC -XX:-OmitStackTraceInFastThrow -XX:+UseStringDeduplication -XX:+PerfDisableSharedMem -XX:+ParallelRefProcEnabled -XX:MaxGCPauseMillis=150 -XX:+UseLargePages -XX:+AlwaysPreTouch"
volumeClaimTemplates:
storageSize: "100Gi" # Size of the Solr disk
replicaCount: 6 # Number of Solr pods to run in this StatefulSet
zookeeper:
nodeSelector:
cloud.google.com/gke-nodepool: default-pool
replicaCount: 3 # Number of Zookeepers
persistence:
size: 20Gi
resources: {}
env:
ZK_HEAP_SIZE: 1G
ZOO_AUTOPURGE_PURGEINTERVAL: 1
```
To be clear, you can tune GC settings and number of replicas after the cluster is built. But changing the size of the persistent volumes is more complicated so you should try to pick a good size initially.
### Configure storage class for Solr pods (optional)
If you wish to run with a storage class other than the default you can create a storage class for your Solr pods before you install. For example, to create regional disks in GCP you can create a file called `storageClass.yaml` with the following contents:
```yaml theme={"dark"}
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: solr-gke-storage-regional
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-standard
replication-type: regional-pd
zones: us-west1-b, us-west1-c
```
and then provision into your cluster by calling:
```bash theme={"dark"}
kubectl apply -f storageClass.yaml
```
to then have Solr use the storage class by adding the following to the custom values YAML:
```yaml theme={"dark"}
solr:
volumeClaimTemplates:
storageClassName: solr-gke-storage-regional
storageSize: 250Gi
```
We’re not advocating that you must use regional disks for Solr storage, as that would be redundant with Solr replication. We’re just using this as an example of how to configure a custom storage class for Solr disks if you see the need. For instance, you could use regional disks without Solr replication for write-heavy type collections.
## Configure multiple node pools
Lucidworks recommends isolating search workloads from analytics workloads using multiple node pools. The included scripts do not do this for you; this is a manual process.
See the example script for GKE, see [create\_gke\_cluster\_node\_pools.sh](https://github.com/lucidworks/fusion-cloud-native/blob/master/additional_environments/create_gke_cluster_node_pools.sh).
In the custom values YAML file, you can add additional Solr StatefulSets by adding their names to the list under the `nodePools` property. If any property for that statefulset needs to be changed from the default set of values, then it can be set directly on the object representing the node pool, any properties that are omitted are defaulted to the base value. See the following example (additional whitespace added for display purposes only):
```yaml expandable highlight={3,4,9,17,22,31} theme={"dark"}
solr:
nodePools:
- name: ""
- name: "analytics"
javaMem: "-Xmx6g"
replicaCount: 6
storageSize: "100Gi"
nodeSelector:
fusion_node_type: analytics
resources:
requests:
cpu: 2
memory: 12Gi
limits:
cpu: 3
memory: 12Gi
- name: "search"
javaMem: "-Xms11g -Xmx11g"
replicaCount: 12
storageSize: "50Gi"
nodeSelector:
fusion_node_type: search
resources:
limits:
cpu: "7700m"
memory: "26Gi"
requests:
cpu: "7000m"
memory: "25Gi"
nodeSelector:
cloud.google.com/gke-nodepool: default-pool
...
```
1. The empty string `""` is the suffix for the default partition.
2. Overrides the settings for the **analytics** Solr pods.
3. Assigns the **analytics** Solr pods to the node pool and attaches the label `fusion_node_type=analytics`. You can use the `fusion_node_type` property in Solr auto-scaling policies to govern replica placement during collection creation.
4. Overrides the settings for the **search** Solr pods.
5. Assigns the **search** Solr pods to the node pool and attaches the label `fusion_node_type=search`.
6. Sets the default settings for all Solr pods, if not specifically overridden in the `nodePools` section above.
Do not edit the `nodePools` value `""`.
In the example above, the **analytics** partition `replicaCount`, or number of Solr pods, is six. The **search** partition `replicaCount` is twelve.
Each nodePool is automatically be assigned the -Dfusion\_node\_type property of ``, ``, or ``. This value matches the name of the nodePool. For example, `-Dfusion_node_type=`.
The Solr pods have a `fusion_node_type` system property, as shown below:
### Custom certificates for indexing and querying services
Fusion 5.9.13 introduces the ability add custom certificates for indexing and querying services, making it easier to align to your organization’s specific security requirements. This feature allows a Helm chart update to support persistent custom certificates and adding them into truststores during pod startup.
To add a custom certificate, create a new YAML file for your custom certificates and edit it to include your indexing or querying certificates. You must use different YAML files in order to use different certificates for indexing and querying services. See **Deploy Fusion at Scale** for full instructions, including the Helm chart update.
Before you begin, see [Fusion Server Deployment](/docs/5/fusion/operations/deployment) to understand the architecture and requirements.
This article explains how to plan and execute a Fusion deployment at the scale required for staging or production.
While the `setup_f5_*.sh` scripts are handy for getting started and proof-of-concept purposes, this article covers the planning process for building a production-ready environment.
The course for **Preparing for Fusion Implementation** focuses on the key elements for a successful implementation, defining your business requirements, preparing clean data, and involving the right personnel.
## Prerequisites
You must meet the following prerequisites before you can customize your Fusion cluster:
* A local copy of the [fusion-cloud-native repository](https://github.com/lucidworks/fusion-cloud-native). This must be up-to-date with the latest master branch.
* Any cloud provider-specific **command line tools**, such as `gcloud` or `aws`, and `kubectl`.\
See the platform-specific instructions linked above, or check with your cloud provider.
* Helm v3
* To install on a Mac:
```bash theme={"dark"}
brew upgrade kubernetes-helm
```
* For other operating systems, download from [Helm Releases](https://github.com/helm/helm/releases).
* Verify your installation:
```bash theme={"dark"}
helm version --short
v3.0.0+ge29ce2a
```
* Kubernetes namespace
* Collect the following information about your Kubernetes environment:
* **CLUSTER**: Cluster name (passed to our setup scripts using the `-c` arg)
* **NAMESPACE**: Kubernetes namespace where to install Fusion; a namespace should only contain lowercase letters (a-z), digits (0-9), or dash. No periods or underscores allowed.
* *(optional)* Clarify your organization’s DockerHub policy. The Fusion Helm chart points to public Docker images on DockerHub. Your organization may not allow Kubernetes to pull images directly from DockerHub or may require extra security scanning before loading images into production clusters.\
Consult your Kubernetes and Docker admin team to find how to get the Fusion images loaded into a registry that’s accessible to your cluster. You can update the image for each service using the [custom values YAML file](#custom-values-yaml-file).
**Kubernetes namespace tips**
* Fusion 5 service discovery requires all services for the same release be deployed in the same namespace. Moreover, you should only run one instance of Fusion in a namespace. If you need multiple instances of Fusion running in the same Kubernetes cluster, then you need to deploy them in separate namespaces.
* If your organization requires CPU / Memory quotas for namespaces, you can start with a minimum of 12 CPU and 45GB of RAM (such as 3 x n1-standard-4 on GKE), but you will need to increase the quotas once you start load testing Fusion with production workloads and real datasets.
* Fusion requires at least 3 ZooKeeper nodes and 2 Solr nodes to achieve high availability.
## Custom values YAML file
1. Clone the `fusion-cloud-native` repository: `git clone https://github.com/lucidworks/fusion-cloud-native`
2. Run the `customize_fusion_values.sh` script.
```bash theme={"dark"}
./customize_fusion_values.sh --provider -c -n \
--num-solr 3 \
--solr-disk-gb 100 \
--node-pool \
--prometheus true \
--with-resource-limits \
--with-affinity-rules
```
Pass the `--help` parameter to see script usage details.
The script creates the following files:
| File | Description |
| --------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------ |
| `___fusion_values.yaml` | Main custom values YAML used to override Helm chart defaults for Fusion microservices. |
| `___monitoring_values.yaml` | Custom values yaml used to configure Prometheus and Grafana. |
| `___fusion_resources.yaml` | Resource requests and limits for all Microservices. |
| `___fusion_affinity.yaml` | Pod affinity rules to ensure multiple replicas for a single service are evenly distributed across zones and nodes. |
| `___upgrade_fusion.sh` | Script used to install and/or upgrade Fusion using the aforementioned custom values YAML files. |
For an explanation of these placeholder values, see [Configuration Values](#custom-values-yaml-file) below.
3. Add the new files to version control. You will make changes to it over time as you fine-tune your Fusion installation. You will also need it to perform upgrades. If you try to upgrade your Fusion installation and don’t provide the custom values YAML, your deployment will revert to chart defaults.\
Review the `___fusion_values.yaml` file to familiarize yourself with its structure and contents. Notice it contains a separate section for each of the Fusion microservices. The example configuration of the `query-pipeline` service below illustrates some important concepts about the custom values YAML file.
```yaml highlight={1,2,3,5,6} theme={"dark"}
query-pipeline:
enabled: true
nodeSelector:
cloud.google.com/gke-nodepool: default-pool
javaToolOptions: "..."
pod:
annotations:
prometheus.io/port: "8787"
prometheus.io/scrape: "true"
prometheus.io/path: "/actuator/prometheus"
```
4. Service-specific setting overrides under the top-level heading
5. Every Fusion service has an implicit enabled flag that defaults to true, set to false to remove this service from your cluster
6. Node selector identifies the label find nodes to schedule pods on
7. Used to pass JVM options to the service
8. Pod annotations to allow Prometheus to scrape metrics from the service
Once we go through all of the configuration topics in this topic, you’ll have a well-configured custom values YAML file for your Fusion 5 installation. You’ll then use this file during the Helm v3 installation at the end of this topic.
### Deployment-specific values
The script creates a custom values YAML file using the naming convention: `___fusion_values.yaml`. For example, `gke_search_f5_fusion_values.yaml`.
| Parameter | Description |
| ----------------- | -------------------------------------------------------------------------- |
| `` | The K8s platform you’re running on, such as `gke`. |
| `` | The name of your cluster. |
| `` | The K8s namespace where you want to install Fusion. |
| `` | Specifies a `nodeSelector` label to find nodes to schedule Fusion pods on. |
Providing the correct `--node-pool ` label is very important. Using the wrong value will cause your pods to be stuck in the `pending` state. If you’re not sure about the correct value for your cluster, pass ’{}'\` to let Kubernetes decide which nodes to schedule Fusion pods on.
Default `nodeSelector` labels are provider-specific. The `fusion-cloud-native` scripts use the following defaults for GKE and EKS:
| Provider | Default node selector |
| -------- | ------------------------------------------------ |
| GKE | cloud.google.com/gke-nodepool: default-pool |
| EKS | alpha.eksctl.io/nodegroup-name: standard-workers |
If you are deploying Fusion 5.9.12, add the following to your `values.yaml` file to avoid a known issue that prevents the `kuberay-operator` pod from launching successfully: `yaml kuberay-operator: crd: create: true `
### Flags
The script provides flags for additional configuration:
| Flag | Description |
| ------------------------ | ------------------------------------------------- |
| `--node-pool` | Add a Fusion specific label to your nodes. |
| `--with-resource-limits` | Configure resource requests/limits. |
| `--with-replicas` | Configure replica counts. |
| `--with-affinity-rules` | Configure pod affinity rules for Fusion services. |
Use `--node-pool` to add a Fusion specific label to your nodes by doing:
```bash theme={"dark"}
kubectl label fusion_node_type=
```
Then, pass `--node-pool 'fusion_node_type: '`.
## Configure Solr sizing
When you’re ready to build a production-ready setup for Fusion 5, you need to customize the Fusion Helm chart to ensure Fusion is well-configured for production workloads.
You’ll be able to scale the number of nodes for Solr up and down after building the cluster, but you need to establish the initial size of the nodes (memory and CPU) and the size and type of disks you need.
See the example config below to learn which parameters to change in the custom values YAML file.
```yaml expandable theme={"dark"}
solr:
resources: # Set resource limits for Solr to help K8s pod scheduling;
limits: # these limits are not just for the Solr process in the pod,
cpu: "7700m" # so allow ample memory for loading index files into the OS cache (mmap)
memory: "26Gi"
requests:
cpu: "7000m"
memory: "25Gi"
logLevel: WARN
nodeSelector:
fusion_node_type: search # Run this Solr StatefulSet in the "search" node pool
exporter:
enabled: true # Enable the Solr metrics exporter (for Prometheus) and
# schedule on the default node pool (system partition)
podAnnotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9983"
prometheus.io/path: "/metrics"
nodeSelector:
cloud.google.com/gke-nodepool: default-pool
image:
tag: 8.4.1
updateStrategy:
type: "RollingUpdate"
javaMem: "-Xmx3g -Dfusion_node_type=system" # Configure memory settings for Solr
solrGcTune: "-XX:+UseG1GC -XX:-OmitStackTraceInFastThrow -XX:+UseStringDeduplication -XX:+PerfDisableSharedMem -XX:+ParallelRefProcEnabled -XX:MaxGCPauseMillis=150 -XX:+UseLargePages -XX:+AlwaysPreTouch"
volumeClaimTemplates:
storageSize: "100Gi" # Size of the Solr disk
replicaCount: 6 # Number of Solr pods to run in this StatefulSet
zookeeper:
nodeSelector:
cloud.google.com/gke-nodepool: default-pool
replicaCount: 3 # Number of Zookeepers
persistence:
size: 20Gi
resources: {}
env:
ZK_HEAP_SIZE: 1G
ZOO_AUTOPURGE_PURGEINTERVAL: 1
```
To be clear, you can tune GC settings and number of replicas after the cluster is built. But changing the size of the persistent volumes is more complicated so you should try to pick a good size initially.
### Configure storage class for Solr pods (optional)
If you wish to run with a storage class other than the default you can create a storage class for your Solr pods before you install. For example, to create regional disks in GCP you can create a file called `storageClass.yaml` with the following contents:
```yaml theme={"dark"}
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: solr-gke-storage-regional
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-standard
replication-type: regional-pd
zones: us-west1-b, us-west1-c
```
and then provision into your cluster by calling:
```bash theme={"dark"}
kubectl apply -f storageClass.yaml
```
to then have Solr use the storage class by adding the following to the custom values YAML:
```yaml theme={"dark"}
solr:
volumeClaimTemplates:
storageClassName: solr-gke-storage-regional
storageSize: 250Gi
```
We’re not advocating that you must use regional disks for Solr storage, as that would be redundant with Solr replication. We’re just using this as an example of how to configure a custom storage class for Solr disks if you see the need. For instance, you could use regional disks without Solr replication for write-heavy type collections.
## Configure multiple node pools
Lucidworks recommends isolating search workloads from analytics workloads using multiple node pools. The included scripts do not do this for you; this is a manual process.
See the example script for GKE, see [create\_gke\_cluster\_node\_pools.sh](https://github.com/lucidworks/fusion-cloud-native/blob/master/additional_environments/create_gke_cluster_node_pools.sh).
In the custom values YAML file, you can add additional Solr StatefulSets by adding their names to the list under the `nodePools` property. If any property for that statefulset needs to be changed from the default set of values, then it can be set directly on the object representing the node pool, any properties that are omitted are defaulted to the base value. See the following example (additional whitespace added for display purposes only):
```yaml expandable highlight={3,4,9,17,22,31} theme={"dark"}
solr:
nodePools:
- name: ""
- name: "analytics"
javaMem: "-Xmx6g"
replicaCount: 6
storageSize: "100Gi"
nodeSelector:
fusion_node_type: analytics
resources:
requests:
cpu: 2
memory: 12Gi
limits:
cpu: 3
memory: 12Gi
- name: "search"
javaMem: "-Xms11g -Xmx11g"
replicaCount: 12
storageSize: "50Gi"
nodeSelector:
fusion_node_type: search
resources:
limits:
cpu: "7700m"
memory: "26Gi"
requests:
cpu: "7000m"
memory: "25Gi"
nodeSelector:
cloud.google.com/gke-nodepool: default-pool
...
```
1. The empty string `""` is the suffix for the default partition.
2. Overrides the settings for the **analytics** Solr pods.
3. Assigns the **analytics** Solr pods to the node pool and attaches the label `fusion_node_type=analytics`. You can use the `fusion_node_type` property in Solr auto-scaling policies to govern replica placement during collection creation.
4. Overrides the settings for the **search** Solr pods.
5. Assigns the **search** Solr pods to the node pool and attaches the label `fusion_node_type=search`.
6. Sets the default settings for all Solr pods, if not specifically overridden in the `nodePools` section above.
Do not edit the `nodePools` value `""`.
In the example above, the **analytics** partition `replicaCount`, or number of Solr pods, is six. The **search** partition `replicaCount` is twelve.
Each nodePool is automatically be assigned the -Dfusion\_node\_type property of ``, ``, or ``. This value matches the name of the nodePool. For example, `-Dfusion_node_type=`.
The Solr pods have a `fusion_node_type` system property, as shown below:
 ## Solr auto-scaling policy
Use [replica placement plugins](https://solr.apache.org/guide/solr/latest/configuration-guide/replica-placement-plugins.html) to control how replicas are placed in Solr.
## Pod network policy
A Kubernetes network policy governs how groups of pods communicate with each other and other network endpoints. With Fusion, all incoming traffic flows through the API Gateway service. All Fusion services in the same namespace expect an internal JWT, which is supplied by the Gateway, as part of the request. As a result, Fusion services enforce a basic level of API security and don’t need an additional network policy to protect them from other pods in the cluster.
To install the network policy for Fusion services, pass `--set global.networkPolicyEnabled=true` when installing the Fusion Helm chart.
## On-premises private Docker registries
For on-premises Kubernetes deployments, your organization may not allow Kubernetes to pull [Fusion’s Docker images from DockerHub](https://hub.docker.com/u/lucidworks/). See the instructions below for details on using a private Docker registry with Fusion. These are general instructions that may need to be adapted to work within your organization’s security policies:
1. Transfer the public images from DockerHub to your private Docker registry.
2. Establish a workstation that has access to [DockerHub](https://hub.docker.com). This workstation must connect to your internal Docker registry, most likely via VPN connection. In this example, the workstation is referred to as `envoy`.
3. Install Docker on `envoy`. You need at least 100GB of free disk for Docker.
4. Pull all of the images from DockerHub to `envoy`’s local registry. For example, to pull the query pipeline image, run `docker pull lucidworks/query-pipeline:5.9.0`. See `docker pull --help` for more information about pulling Docker images.
5. Establish a connection from `envoy` to the private Docker registry, most likely via a VPN connection. In this example, the private Docker registry is referred to as ``.
6. Push the images from `envoy`’s Docker registry to the private registry. This will take a long time.
1. You’ll need to re-tag all images for the internal registry. For example, to tag the query-pipeline image, run:
```bash theme={"dark"}
docker tag lucidworks/query-pipeline:5.9.0 /query-pipeline:5.9.0
```
2. Push each image to the internal repo:
```bash theme={"dark"}
docker push /query-pipeline:5.9.0
```
7. Install the Docker registry secret in Kubernetes. Create the Docker registry secret in the Kubernetes namespace where you want to install Fusion:
```bash theme={"dark"}
SECRET_NAME=
REPO=
kubectl create secret docker-registry "${SECRET_NAME}" \
--namespace "${NAMESPACE}" \
--docker-server="${REPO}" \
--docker-username=${REPO_USER} \
--docker-password=${REPO_PASS} \
--docker-email=${REPO_USER}
```
For details, see the Kubernetes article [Pull an Image from a Private Registry](https://kubernetes.io/docs/tasks/configure-pod-container/pull-image-private-registry/).
8. Update the custom values YAML for your cluster to point to your private registry and secret to allow Kubernetes to pull images. For example:
```yaml theme={"dark"}
query-pipeline:
image:
imagePullSecrets:
- name:
repository:
```
Repeat the process for all Fusion services.
### Customize Helm Chart
Every Fusion service allows you to override the `imagePullSecrets` setting using custom values YAML. However, other 3rd party services--including Zookeeper, Pulsar, Prometheus, and Grafana--don’t allow you to supply the pull secret using the custom values YAML.
To patch the default service account for your namespace and add the pull secret, run the following:
```bash theme={"dark"}
kubectl patch sa default -n $NAMESPACE \
-p '"imagePullSecrets": [{"name": "" }]'
```
In Windows using PowerShell or another CLI, you might have to escape the double quotes with a backslash (`\`) or reverse the order of single and double quotes:
```bash theme={"dark"}
kubectl patch sa default -n $NAMESPACE \
-p "'imagePullSecrets': [{'name': ''}]"
```
Replace `` with the name of the secret you created in the steps above.
This allows the default service account to pull images from the private registry without specifying the pull secret on the resources directly.
## Add additional trusted certificate(s) to Fusion’s indexing and querying services *(optional)*
You can add custom trusted certificates to support Fusion’s indexing and querying services. You may want to use custom trusted certificates if, for example, you have specific security requirements for data handling or need to support an existing infrastructure and its security needs. This method involves updating your Helm chart.
If you want to add custom trusted certificates for both the indexing and querying services, follow these instructions twice: once for the indexing service, and once for the querying service. To add different certificates to the indexing and querying services, create one YAML file with the indexing service certificates and one YAML file for the querying service certificates before following these instructions.
You may use the same YAML file if you want to use the same certificates for both services.
To add custom trusted certificates:
1. Create a new YAML file for your custom trusted certificates. The `customcerts.yaml` file is the example file in these instructions.
2. Add the custom certificate(s) in the YAML file created in the previous step. For example:
```yaml theme={"dark"}
trustedCertificates:
enabled: true
files:
some.cert: |-
-----BEGIN CERTIFICATE-----
MIIDeTCCAmGgAwIBAgIJAPziuikCTox4MA0GCSqGSIb3DQEBCwUAMGIxCzAJBgNV
(...)
EVA0pmzIzgBg+JIe3PdRy27T0asgQW/F4TY61Yk=
-----END CERTIFICATE-----
other.cert: |-
-----BEGIN CERTIFICATE-----
MIIDeTCCAmGgAwIBAgIJAPziuikCTox4MA0GCSqGSIb3DQEBCwUAMGIxCzAJBgNV
(...)
EVA0pmzIzgBg+JIe3PdRy27T0asgQW/F4TY61Yk=
-----END CERTIFICATE---------
```
3. Update the indexing or querying service by running the following Helm command. Replace `EXAMPLE-VALUES-FILE.yaml` with your previous values file.
```bash theme={"dark"}
helm upgrade --install --namespace ${EXAMPLE-NAMESPACE} ${HELM-RELEASE} ${HELM-CHART-PATH} --values EXAMPLE-VALUES-FILE.yaml --values customcerts.yaml
```
4. Verify the indexing or querying pod has a new `init-container` with the name `import-certs`.
## Add additional trusted certificate(s) for connectors to allow crawling of web resources with SSL/TLS enabled *(optional)*
To crawl a datasource which for some reason is using a self-signed certificate, add arbitrary certificates to connectors. For example:
```yaml wrap expandable theme={"dark"}
classic-rest-service:
trustedCertificates:
enabled: true
files:
some.cert: |-
-----BEGIN CERTIFICATE-----
MIIDeTCCAmGgAwIBAgIJAPziuikCTox4MA0GCSqGSIb3DQEBCwUAMGIxCzAJBgNV
(...)
EVA0pmzIzgBg+JIe3PdRy27T0asgQW/F4TY61Yk=
-----END CERTIFICATE-----
other.cert: |-
-----BEGIN CERTIFICATE-----
MIIDeTCCAmGgAwIBAgIJAPziuikCTox4MA0GCSqGSIb3DQEBCwUAMGIxCzAJBgNV
(...)
EVA0pmzIzgBg+JIe3PdRy27T0asgQW/F4TY61Yk=
-----END CERTIFICATE---------
connector-plugin:
trustedCertificates:
enabled: true
files:
some.cert: |-
-----BEGIN CERTIFICATE-----
MIIDeTCCAmGgAwIBAgIJAPziuikCTox4MA0GCSqGSIb3DQEBCwUAMGIxCzAJBgNV
(...)
EVA0pmzIzgBg+JIe3PdRy27T0asgQW/F4TY61Yk=
-----END CERTIFICATE-----
other.cert: |-
-----BEGIN CERTIFICATE-----
MIIDeTCCAmGgAwIBAgIJAPziuikCTox4MA0GCSqGSIb3DQEBCwUAMGIxCzAJBgNV
(...)
EVA0pmzIzgBg+JIe3PdRy27T0asgQW/F4TY61Yk=
-----END CERTIFICATE---------
```
### Generating the certificate on linux command line
Use the following command to generate a `.crt` file in `$fusion_home/apps/jetty/connectors/etc/yourcertname.crt`:
```bash theme={"dark"}
openssl s_client -servername remote.server.net -connect remote.server.net:443 $fusion_home/apps/jetty/connectors/etc/yourcertname.crt
```
### Generating the certificate using Firefox web browser
1. Navigate to the SharePoint host.
2. Click the in the address bar, then click the icon.
3. Next, navigate to **More Information** > **View Certificate** > **Export**.\
Save the file to the following folder:
`$fusion_home/apps/jetty/connectors/etc/yourcertname.crt`
### Generating the certificate using Chrome web browser
1. Navigate to **Chrome menu** > **More Tools** > **Developer Tools** > **Security Tab**.
This will display the **Security overview**.
2. Click the **View certificate** button.
3. Save the file to the following folder:
`$fusion_home/apps/jetty/connectors/etc/yourcertname.crt`
### Generating the certificate using powershell
Use the following script to generate a `.crt`` file in `\$fusion\_home\apps\jetty\connectors\etc\yourcertname.crt\`\`:
```bash theme={"dark"}
$fusion_home = c:\your\fusion\install\directory
$webRequest = [Net.WebRequest]::Create("https://your-hostname")
try { $webRequest.GetResponse() } catch {}
$cert = $webRequest.ServicePoint.Certificate
$bytes = $cert.Export([Security.Cryptography.X509Certificates.X509ContentType]::Cert)
set-content -value $bytes -encoding byte -path "$fusion_home\apps\jetty\connectors\etc\yourcertname.binary.crt"
certutil -encode "$fusion_home\apps\jetty\connectors\etc\yourcertname.binary.crt" "$fusion_home\apps\jetty\connectors\etc\yourcertname.crt"
rm "$fusion_home\apps\jetty\connectors\etc\yourcertname.binary.crt" -f
```
## Install Fusion 5 on Kubernetes
At this point, you’re ready to install Fusion 5 using the custom values YAML files and upgrade script. If you used the `customize_fusion_values.sh` script, run it using BASH:
```bash theme={"dark"}
./gke_search_f5_upgrade_fusion.sh
```
Once the installation is complete, verify your Fusion installation is running correctly.
## Monitoring Fusion with Prometheus and Grafana
Lucidworks recommends using Prometheus and Grafana for monitoring the performance and health of your Fusion cluster. Your operations team may already have these services installed. If not, install them into the Fusion namespace.
The [Custom values YAML file shown above](#custom-values-yaml-file) activates the Solr metrics exporter service and adds pod annotations so Prometheus can scrape metrics from Fusion services.
1. Run the `customize_fusion_values.sh` script with the `--prometheus true` option. This creates an extra custom values YAML file for installing Prometheus and Grafana, `___monitoring_values.yaml`. For example: `gke_search_f5_monitoring_values.yaml`.
2. Commit the YAML file to version control.
3. Review its contents to ensure that the settings suit your needs. For example, decide how long you want to keep metrics. The default is 36 hours.\
See the [Prometheus documentation](https://github.com/helm/charts/tree/master/stable/prometheus) and [Grafana documentation](https://github.com/helm/charts/tree/master/stable/grafana) for details.
4. Run the `install_prom.sh` script to install Prometheus & Grafana in your namespace. Include the provider, cluster name, namespace, and helm release as in the example below:
```bash theme={"dark"}
./install_prom.sh --provider gke -c search -n f5 -r 5-5-1
```
Pass the `--help` parameter to see script usage details.
The Grafana dashboards from [monitoring/grafana](https://github.com/lucidworks/fusion-cloud-native/tree/master/monitoring/grafana) are installed automatically by the `install_prom.sh` script.
### Support for pre-filtering in the Chunking Neural Hybrid Query stage
For parity with the [Neural Hybrid Query stage](/docs/5/fusion/reference/config-ref/pipeline-stages/query-stages/neural-hybrid-query), the [Chunking Neural Hybrid Query Stage](/docs/5/fusion/reference/config-ref/pipeline-stages/query-stages/chunking-neural-hybrid-query) now supports pre-filtering.
Pre-filtering can improve performance by reducing the number of chunks that need to be processed.
However, in some cases it can also lead to less accurate facet counts and search results.
Pre-filtering is blocked by default.
You can enable it by unchecking the **Block pre-filtering** checkbox in the Chunking Neural Hybrid Query stage configuration.
### Default Solr data commit parameter changed to autoCommit
Solr's `commitWithin` parameter was removed as the default at the collection level. The default parameter is now `autoCommit`.
Solr offers three methods to determine when newly-indexed documents are made visible in searches. The methods are manual commits, auto commit settings, and the per-update `commitWithin` parameter.
Fusion relies on Solr's commit mechanisms, but adds a Fusion-managed `commitWithin` policy per collection. Fusion's typical commit configuration includes the following parameters:
* The `autoCommit` setting (Solr hard commit) is Fusion's default parameter for Solr data commits, is inherited from the collection's `solrconfig.xml`, and defaults to `15` seconds. This saves the data, but does not force the search results to refresh immediately. With this setting, search performance is not slowed, but the new data may not show in search results until the next refresh. This property can be used instead of the `commitWithin` property.
* The `autoSoftCommit` setting (Solr soft commit) does not save the data, but makes the data visible to searches almost immediately. If the system crashes, that new data is lost because it has not been saved. The default is false, and search visibility is managed using the `commitWithin` setting.
* Solr's `commitWithin` parameter, configured at the collection level with a default of `10000` milliseconds, ensures data is committed and available for searching within 10 seconds. The default for signals collections is `1000` milliseconds. Fusion uses `commitWithin` to avoid relying on specific Solr-side configurations. The `com.lucidworks.apollo.solr.commitWithin` global property defines the default `commitWithin` for all documents added through Fusion. When you create a new collection in Fusion, its per-collection `commitWithin` is initialized from this global default.
For more information, see [Collection configuration properties](/docs/5/fusion/getting-data-in/indexing/collections/overview#collection-configuration-properties) and [various operations in the Collections API](/api-reference/collections/list-all-collections).
## Bug fixes
* Corrected the health reporting behavior for the `job-config` service after ZooKeeper disruptions.\
Fusion now ensures the `/actuator/health` endpoint correctly reflects the actual status of the `job-config` service, even after temporary ZooKeeper unavailability.\
This prevents false `DOWN` reports that could affect monitoring or automated recovery systems.
* Updated the `fusion-spark-3.2.2` image to resolve a Fabric8 token refresh bug.\
The Fabric8 Kubernetes client in this Spark image has been patched to fix a bug that prevented token refresh under OIDC authentication.\
This ensures that Spark jobs using `fusion-spark-3.2.2` run reliably in Kubernetes environments that require token-based authentication.
* Fixed a bug that prevented Web V2 connector jobs from restarting after failure.\
In previous versions, if a job was interrupted (such as by scaling down the connector pod), the connectors-backend service could enter a corrupted state, preventing future runs of the same job with errors like `The state should never be null`.\
Fusion now properly resets internal job state, ensuring that failed jobs can be restarted reliably.
* Fixed Web connector indexing failure caused by corrupted job state.\
Fusion 5.9.13 restores indexing functionality for the Webv2 connector (v2.0.1) by resolving an issue that caused a corrupted job state in the `connectors-backend` service.
Jobs that previously failed with `The state should never be null` can now complete successfully.
* Fixed an issue that prevented schedule changes from persisting for some datasources.\
In Fusion 5.9.12, clicking **Save** after configuring a new schedule for a datasource in the “Run” dialog could fail silently in certain apps, leaving the schedule unsaved with no warning to the user.\
This was due to a `job-config` handling issue that affected pre-existing app configurations.\
Fusion 5.9.13 resolves this issue so that new schedules are reliably saved and acknowledged as expected.
* Fixed permission handling in the `job-config` service to ensure scheduled jobs run as expected.\
Fusion now correctly handles permission checks when creating or modifying scheduled jobs, preventing failures caused by mismatches between user and service account permissions.\
This resolves issues where job could not be scheduled or executed following upgrades.
* Helm charts now support Kubernetes secrets for TLS keystore passwords.\
Fusion 5.9.13 updates the Helm charts to eliminate the use of plaintext passwords for TLS keystores. You can now securely manage the keystorePassword using a Kubernetes secret, aligning with hardened OpenShift and enterprise security policies.
* Upgraded the Spring framework in the `web-apps` service to improve security and ensure compatibility with token authentication behavior on modern Kubernetes platforms.
## Known issues
* Job-config service may appear “down” in UI even when running correctly\
In Fusion 5.9.13, the job-config service may falsely report as “down” in the Fusion UI, particularly during startup or in TLS-enabled deployments.\
This issue is fixed in Fusion 5.9.14.
For the `job-config` service, the **Next Run** value is updated *only after the current job completes*. Because the same job cannot run multiple times simultaneously, if another run is scheduled before the current job completes, that run is not executed.
* Jobs and V2 datasources may fail when Fusion collections are remapped to different Solr collections.\
In Fusion 5.9.13, strict validation in the `job-config` service causes “Collection not found” errors when jobs or V2 datasources target Fusion collections that point to differently named Solr collections.
This issue is fixed in Fusion 5.9.14.
As a workaround, use V1 datasources or avoid using REST call jobs on remapped collections.
* Saving large query pipelines may cause OOM failures under high load.\
In Fusion 5.9.13, saving a large query pipeline during high query volume can result in thread lock, excessive memory use, and eventual OOM errors in the Query service.\
This issue is fixed in Fusion 5.9.14.
* Some S3 and Web datasource jobs cannot be stopped in Fusion 5.9.13.\
Clicking the Stop button has no effect in some cases where the backend job is no longer being tracked. This causes the `job-config` service to ignore the job and prevents the system from updating the job status. A workaround is to issue a `POST {"action": "start"}` to the appropriate job actions endpoint, which aborts the stuck job.\
This issue is fixed in Fusion 5.9.14.
* Spark jobs may disappear from the job list after pod deletion\
In Fusion 5.9.12 and 5.9.13, Spark jobs may vanish from the job list if a Spark driver pod is deleted. This behavior can cause confusion and require a job-launcher restart to restore job visibility.\
This issue is fixed in Fusion 5.9.13.
## Deprecations and removals
For full details, see [Deprecations and Removals](/docs/5/fusion/deprecations-and-removals).
### Bitnami removal
Fusion 5.9.13 will be re-released with the same functionality but updated image references.
In the meantime, Lucidworks will self-host the required images while we work to replace Bitnami images with internally built open-source alternatives.
If you are a self-hosted Fusion customer, *you must upgrade before August 28* to ensure continued access to container images and prevent deployment issues.
You can reinstall your current version of Fusion or upgrade to Fusion 5.9.14, which includes the updated Helm chart and prepares your environment for long-term compatibility.
See [Prevent image pull failures due to Bitnami deprecation in Fusion 5.9.5 to 5.9.13](https://support.lucidworks.com/hc/en-us/articles/33966125467799-Prevent-image-pull-failures-due-to-Bitnami-deprecation-in-Fusion-5-9-5-to-5-9-13) for more information on how to prevent image pull failures.
### Hybrid Query pipeline stage
The [Hybrid Query pipeline stage](/docs/5/fusion/reference/config-ref/pipeline-stages/query-stages/hybrid-search-query) is now deprecated.
Instead, use the [Neural Hybrid Query stage](/docs/5/fusion/reference/config-ref/pipeline-stages/query-stages/neural-hybrid-query), which combines lexical and vector search and includes improvements such as K-Nearest Neighbors (KNN), chunking, and more.
### Container image for `kafka-exporter`
Bitnami stopped supporting `kafka-exporter` and renamed the [docker repository](https://hub.docker.com/r/bitnamilegacy/kafka-exporter-archived) from `bitnami/kafka-exporter` to `bitnami/kafka-exporter-archived`.
If you were using `kafka-exporter`, then you need to update the repository name in your `values.yaml` file:
```yaml theme={"dark"}
kafka.metrics.kafka.image.repository=bitnami/kafka-exporter-archived
```
Changing the repository name will allow you to continue using Kafka metrics evaluation with Prometheus/Grafana.
### Removed deprecated `X-XSS-Protection` header from session API responses
Fusion 5.9.13 removes the deprecated `X-XSS-Protection` HTTP response header from the session API.
This header is no longer supported by modern browsers and has no effect on security behavior.
Its removal helps avoid confusion during security audits and aligns with current web security standards.
## Platform support and component versions
### Kubernetes platform support
Lucidworks has tested and validated support for the following Kubernetes platforms and versions:
* **Google Kubernetes Engine (GKE):** 1.29, 1.30, 1.31, 1.32
* **Microsoft Azure Kubernetes Service (AKS):** 1.29, 1.30, 1.31, 1.32
* **Amazon Elastic Kubernetes Service (EKS):** 1.29, 1.30, 1.31, 1.32
Support is also offered for Rancher Kubernetes Engine (RKE and RKE2) and OpenShift 4 versions that are based on Kubernetes 1.29, 1.30, 1.31, 1.32; note that RKE2 may require some Helm chart modification. OpenStack and customized Kubernetes installations are *not* supported.
For more information on Kubernetes version support, see the [Kubernetes support policy](/docs/policies/lifecycle-policies/lw-version-support-lifecycle#kubernetes-support).
### Component versions
The following table details the versions of key components that may be critical to deployments and upgrades.
| Component | Version |
| ------------------- | ------------------------------------------------- |
| Solr | fusion-solr 5.9.13 *(based on Solr 9.6.1)* |
| ZooKeeper | 3.9.1 |
| Spark | 3.4.1 |
| Ingress Controllers | Nginx, Ambassador (Envoy), GKE Ingress Controller |
| Ray | ray\[serve] 2.42.1 |
More information about support dates can be found at [Lucidworks Fusion Product Lifecycle](/docs/policies/lifecycle-policies/lw-version-support-lifecycle).
## Solr auto-scaling policy
Use [replica placement plugins](https://solr.apache.org/guide/solr/latest/configuration-guide/replica-placement-plugins.html) to control how replicas are placed in Solr.
## Pod network policy
A Kubernetes network policy governs how groups of pods communicate with each other and other network endpoints. With Fusion, all incoming traffic flows through the API Gateway service. All Fusion services in the same namespace expect an internal JWT, which is supplied by the Gateway, as part of the request. As a result, Fusion services enforce a basic level of API security and don’t need an additional network policy to protect them from other pods in the cluster.
To install the network policy for Fusion services, pass `--set global.networkPolicyEnabled=true` when installing the Fusion Helm chart.
## On-premises private Docker registries
For on-premises Kubernetes deployments, your organization may not allow Kubernetes to pull [Fusion’s Docker images from DockerHub](https://hub.docker.com/u/lucidworks/). See the instructions below for details on using a private Docker registry with Fusion. These are general instructions that may need to be adapted to work within your organization’s security policies:
1. Transfer the public images from DockerHub to your private Docker registry.
2. Establish a workstation that has access to [DockerHub](https://hub.docker.com). This workstation must connect to your internal Docker registry, most likely via VPN connection. In this example, the workstation is referred to as `envoy`.
3. Install Docker on `envoy`. You need at least 100GB of free disk for Docker.
4. Pull all of the images from DockerHub to `envoy`’s local registry. For example, to pull the query pipeline image, run `docker pull lucidworks/query-pipeline:5.9.0`. See `docker pull --help` for more information about pulling Docker images.
5. Establish a connection from `envoy` to the private Docker registry, most likely via a VPN connection. In this example, the private Docker registry is referred to as ``.
6. Push the images from `envoy`’s Docker registry to the private registry. This will take a long time.
1. You’ll need to re-tag all images for the internal registry. For example, to tag the query-pipeline image, run:
```bash theme={"dark"}
docker tag lucidworks/query-pipeline:5.9.0 /query-pipeline:5.9.0
```
2. Push each image to the internal repo:
```bash theme={"dark"}
docker push /query-pipeline:5.9.0
```
7. Install the Docker registry secret in Kubernetes. Create the Docker registry secret in the Kubernetes namespace where you want to install Fusion:
```bash theme={"dark"}
SECRET_NAME=
REPO=
kubectl create secret docker-registry "${SECRET_NAME}" \
--namespace "${NAMESPACE}" \
--docker-server="${REPO}" \
--docker-username=${REPO_USER} \
--docker-password=${REPO_PASS} \
--docker-email=${REPO_USER}
```
For details, see the Kubernetes article [Pull an Image from a Private Registry](https://kubernetes.io/docs/tasks/configure-pod-container/pull-image-private-registry/).
8. Update the custom values YAML for your cluster to point to your private registry and secret to allow Kubernetes to pull images. For example:
```yaml theme={"dark"}
query-pipeline:
image:
imagePullSecrets:
- name:
repository:
```
Repeat the process for all Fusion services.
### Customize Helm Chart
Every Fusion service allows you to override the `imagePullSecrets` setting using custom values YAML. However, other 3rd party services--including Zookeeper, Pulsar, Prometheus, and Grafana--don’t allow you to supply the pull secret using the custom values YAML.
To patch the default service account for your namespace and add the pull secret, run the following:
```bash theme={"dark"}
kubectl patch sa default -n $NAMESPACE \
-p '"imagePullSecrets": [{"name": "" }]'
```
In Windows using PowerShell or another CLI, you might have to escape the double quotes with a backslash (`\`) or reverse the order of single and double quotes:
```bash theme={"dark"}
kubectl patch sa default -n $NAMESPACE \
-p "'imagePullSecrets': [{'name': ''}]"
```
Replace `` with the name of the secret you created in the steps above.
This allows the default service account to pull images from the private registry without specifying the pull secret on the resources directly.
## Add additional trusted certificate(s) to Fusion’s indexing and querying services *(optional)*
You can add custom trusted certificates to support Fusion’s indexing and querying services. You may want to use custom trusted certificates if, for example, you have specific security requirements for data handling or need to support an existing infrastructure and its security needs. This method involves updating your Helm chart.
If you want to add custom trusted certificates for both the indexing and querying services, follow these instructions twice: once for the indexing service, and once for the querying service. To add different certificates to the indexing and querying services, create one YAML file with the indexing service certificates and one YAML file for the querying service certificates before following these instructions.
You may use the same YAML file if you want to use the same certificates for both services.
To add custom trusted certificates:
1. Create a new YAML file for your custom trusted certificates. The `customcerts.yaml` file is the example file in these instructions.
2. Add the custom certificate(s) in the YAML file created in the previous step. For example:
```yaml theme={"dark"}
trustedCertificates:
enabled: true
files:
some.cert: |-
-----BEGIN CERTIFICATE-----
MIIDeTCCAmGgAwIBAgIJAPziuikCTox4MA0GCSqGSIb3DQEBCwUAMGIxCzAJBgNV
(...)
EVA0pmzIzgBg+JIe3PdRy27T0asgQW/F4TY61Yk=
-----END CERTIFICATE-----
other.cert: |-
-----BEGIN CERTIFICATE-----
MIIDeTCCAmGgAwIBAgIJAPziuikCTox4MA0GCSqGSIb3DQEBCwUAMGIxCzAJBgNV
(...)
EVA0pmzIzgBg+JIe3PdRy27T0asgQW/F4TY61Yk=
-----END CERTIFICATE---------
```
3. Update the indexing or querying service by running the following Helm command. Replace `EXAMPLE-VALUES-FILE.yaml` with your previous values file.
```bash theme={"dark"}
helm upgrade --install --namespace ${EXAMPLE-NAMESPACE} ${HELM-RELEASE} ${HELM-CHART-PATH} --values EXAMPLE-VALUES-FILE.yaml --values customcerts.yaml
```
4. Verify the indexing or querying pod has a new `init-container` with the name `import-certs`.
## Add additional trusted certificate(s) for connectors to allow crawling of web resources with SSL/TLS enabled *(optional)*
To crawl a datasource which for some reason is using a self-signed certificate, add arbitrary certificates to connectors. For example:
```yaml wrap expandable theme={"dark"}
classic-rest-service:
trustedCertificates:
enabled: true
files:
some.cert: |-
-----BEGIN CERTIFICATE-----
MIIDeTCCAmGgAwIBAgIJAPziuikCTox4MA0GCSqGSIb3DQEBCwUAMGIxCzAJBgNV
(...)
EVA0pmzIzgBg+JIe3PdRy27T0asgQW/F4TY61Yk=
-----END CERTIFICATE-----
other.cert: |-
-----BEGIN CERTIFICATE-----
MIIDeTCCAmGgAwIBAgIJAPziuikCTox4MA0GCSqGSIb3DQEBCwUAMGIxCzAJBgNV
(...)
EVA0pmzIzgBg+JIe3PdRy27T0asgQW/F4TY61Yk=
-----END CERTIFICATE---------
connector-plugin:
trustedCertificates:
enabled: true
files:
some.cert: |-
-----BEGIN CERTIFICATE-----
MIIDeTCCAmGgAwIBAgIJAPziuikCTox4MA0GCSqGSIb3DQEBCwUAMGIxCzAJBgNV
(...)
EVA0pmzIzgBg+JIe3PdRy27T0asgQW/F4TY61Yk=
-----END CERTIFICATE-----
other.cert: |-
-----BEGIN CERTIFICATE-----
MIIDeTCCAmGgAwIBAgIJAPziuikCTox4MA0GCSqGSIb3DQEBCwUAMGIxCzAJBgNV
(...)
EVA0pmzIzgBg+JIe3PdRy27T0asgQW/F4TY61Yk=
-----END CERTIFICATE---------
```
### Generating the certificate on linux command line
Use the following command to generate a `.crt` file in `$fusion_home/apps/jetty/connectors/etc/yourcertname.crt`:
```bash theme={"dark"}
openssl s_client -servername remote.server.net -connect remote.server.net:443 $fusion_home/apps/jetty/connectors/etc/yourcertname.crt
```
### Generating the certificate using Firefox web browser
1. Navigate to the SharePoint host.
2. Click the in the address bar, then click the icon.
3. Next, navigate to **More Information** > **View Certificate** > **Export**.\
Save the file to the following folder:
`$fusion_home/apps/jetty/connectors/etc/yourcertname.crt`
### Generating the certificate using Chrome web browser
1. Navigate to **Chrome menu** > **More Tools** > **Developer Tools** > **Security Tab**.
This will display the **Security overview**.
2. Click the **View certificate** button.
3. Save the file to the following folder:
`$fusion_home/apps/jetty/connectors/etc/yourcertname.crt`
### Generating the certificate using powershell
Use the following script to generate a `.crt`` file in `\$fusion\_home\apps\jetty\connectors\etc\yourcertname.crt\`\`:
```bash theme={"dark"}
$fusion_home = c:\your\fusion\install\directory
$webRequest = [Net.WebRequest]::Create("https://your-hostname")
try { $webRequest.GetResponse() } catch {}
$cert = $webRequest.ServicePoint.Certificate
$bytes = $cert.Export([Security.Cryptography.X509Certificates.X509ContentType]::Cert)
set-content -value $bytes -encoding byte -path "$fusion_home\apps\jetty\connectors\etc\yourcertname.binary.crt"
certutil -encode "$fusion_home\apps\jetty\connectors\etc\yourcertname.binary.crt" "$fusion_home\apps\jetty\connectors\etc\yourcertname.crt"
rm "$fusion_home\apps\jetty\connectors\etc\yourcertname.binary.crt" -f
```
## Install Fusion 5 on Kubernetes
At this point, you’re ready to install Fusion 5 using the custom values YAML files and upgrade script. If you used the `customize_fusion_values.sh` script, run it using BASH:
```bash theme={"dark"}
./gke_search_f5_upgrade_fusion.sh
```
Once the installation is complete, verify your Fusion installation is running correctly.
## Monitoring Fusion with Prometheus and Grafana
Lucidworks recommends using Prometheus and Grafana for monitoring the performance and health of your Fusion cluster. Your operations team may already have these services installed. If not, install them into the Fusion namespace.
The [Custom values YAML file shown above](#custom-values-yaml-file) activates the Solr metrics exporter service and adds pod annotations so Prometheus can scrape metrics from Fusion services.
1. Run the `customize_fusion_values.sh` script with the `--prometheus true` option. This creates an extra custom values YAML file for installing Prometheus and Grafana, `___monitoring_values.yaml`. For example: `gke_search_f5_monitoring_values.yaml`.
2. Commit the YAML file to version control.
3. Review its contents to ensure that the settings suit your needs. For example, decide how long you want to keep metrics. The default is 36 hours.\
See the [Prometheus documentation](https://github.com/helm/charts/tree/master/stable/prometheus) and [Grafana documentation](https://github.com/helm/charts/tree/master/stable/grafana) for details.
4. Run the `install_prom.sh` script to install Prometheus & Grafana in your namespace. Include the provider, cluster name, namespace, and helm release as in the example below:
```bash theme={"dark"}
./install_prom.sh --provider gke -c search -n f5 -r 5-5-1
```
Pass the `--help` parameter to see script usage details.
The Grafana dashboards from [monitoring/grafana](https://github.com/lucidworks/fusion-cloud-native/tree/master/monitoring/grafana) are installed automatically by the `install_prom.sh` script.
### Support for pre-filtering in the Chunking Neural Hybrid Query stage
For parity with the [Neural Hybrid Query stage](/docs/5/fusion/reference/config-ref/pipeline-stages/query-stages/neural-hybrid-query), the [Chunking Neural Hybrid Query Stage](/docs/5/fusion/reference/config-ref/pipeline-stages/query-stages/chunking-neural-hybrid-query) now supports pre-filtering.
Pre-filtering can improve performance by reducing the number of chunks that need to be processed.
However, in some cases it can also lead to less accurate facet counts and search results.
Pre-filtering is blocked by default.
You can enable it by unchecking the **Block pre-filtering** checkbox in the Chunking Neural Hybrid Query stage configuration.
### Default Solr data commit parameter changed to autoCommit
Solr's `commitWithin` parameter was removed as the default at the collection level. The default parameter is now `autoCommit`.
Solr offers three methods to determine when newly-indexed documents are made visible in searches. The methods are manual commits, auto commit settings, and the per-update `commitWithin` parameter.
Fusion relies on Solr's commit mechanisms, but adds a Fusion-managed `commitWithin` policy per collection. Fusion's typical commit configuration includes the following parameters:
* The `autoCommit` setting (Solr hard commit) is Fusion's default parameter for Solr data commits, is inherited from the collection's `solrconfig.xml`, and defaults to `15` seconds. This saves the data, but does not force the search results to refresh immediately. With this setting, search performance is not slowed, but the new data may not show in search results until the next refresh. This property can be used instead of the `commitWithin` property.
* The `autoSoftCommit` setting (Solr soft commit) does not save the data, but makes the data visible to searches almost immediately. If the system crashes, that new data is lost because it has not been saved. The default is false, and search visibility is managed using the `commitWithin` setting.
* Solr's `commitWithin` parameter, configured at the collection level with a default of `10000` milliseconds, ensures data is committed and available for searching within 10 seconds. The default for signals collections is `1000` milliseconds. Fusion uses `commitWithin` to avoid relying on specific Solr-side configurations. The `com.lucidworks.apollo.solr.commitWithin` global property defines the default `commitWithin` for all documents added through Fusion. When you create a new collection in Fusion, its per-collection `commitWithin` is initialized from this global default.
For more information, see [Collection configuration properties](/docs/5/fusion/getting-data-in/indexing/collections/overview#collection-configuration-properties) and [various operations in the Collections API](/api-reference/collections/list-all-collections).
## Bug fixes
* Corrected the health reporting behavior for the `job-config` service after ZooKeeper disruptions.\
Fusion now ensures the `/actuator/health` endpoint correctly reflects the actual status of the `job-config` service, even after temporary ZooKeeper unavailability.\
This prevents false `DOWN` reports that could affect monitoring or automated recovery systems.
* Updated the `fusion-spark-3.2.2` image to resolve a Fabric8 token refresh bug.\
The Fabric8 Kubernetes client in this Spark image has been patched to fix a bug that prevented token refresh under OIDC authentication.\
This ensures that Spark jobs using `fusion-spark-3.2.2` run reliably in Kubernetes environments that require token-based authentication.
* Fixed a bug that prevented Web V2 connector jobs from restarting after failure.\
In previous versions, if a job was interrupted (such as by scaling down the connector pod), the connectors-backend service could enter a corrupted state, preventing future runs of the same job with errors like `The state should never be null`.\
Fusion now properly resets internal job state, ensuring that failed jobs can be restarted reliably.
* Fixed Web connector indexing failure caused by corrupted job state.\
Fusion 5.9.13 restores indexing functionality for the Webv2 connector (v2.0.1) by resolving an issue that caused a corrupted job state in the `connectors-backend` service.
Jobs that previously failed with `The state should never be null` can now complete successfully.
* Fixed an issue that prevented schedule changes from persisting for some datasources.\
In Fusion 5.9.12, clicking **Save** after configuring a new schedule for a datasource in the “Run” dialog could fail silently in certain apps, leaving the schedule unsaved with no warning to the user.\
This was due to a `job-config` handling issue that affected pre-existing app configurations.\
Fusion 5.9.13 resolves this issue so that new schedules are reliably saved and acknowledged as expected.
* Fixed permission handling in the `job-config` service to ensure scheduled jobs run as expected.\
Fusion now correctly handles permission checks when creating or modifying scheduled jobs, preventing failures caused by mismatches between user and service account permissions.\
This resolves issues where job could not be scheduled or executed following upgrades.
* Helm charts now support Kubernetes secrets for TLS keystore passwords.\
Fusion 5.9.13 updates the Helm charts to eliminate the use of plaintext passwords for TLS keystores. You can now securely manage the keystorePassword using a Kubernetes secret, aligning with hardened OpenShift and enterprise security policies.
* Upgraded the Spring framework in the `web-apps` service to improve security and ensure compatibility with token authentication behavior on modern Kubernetes platforms.
## Known issues
* Job-config service may appear “down” in UI even when running correctly\
In Fusion 5.9.13, the job-config service may falsely report as “down” in the Fusion UI, particularly during startup or in TLS-enabled deployments.\
This issue is fixed in Fusion 5.9.14.
For the `job-config` service, the **Next Run** value is updated *only after the current job completes*. Because the same job cannot run multiple times simultaneously, if another run is scheduled before the current job completes, that run is not executed.
* Jobs and V2 datasources may fail when Fusion collections are remapped to different Solr collections.\
In Fusion 5.9.13, strict validation in the `job-config` service causes “Collection not found” errors when jobs or V2 datasources target Fusion collections that point to differently named Solr collections.
This issue is fixed in Fusion 5.9.14.
As a workaround, use V1 datasources or avoid using REST call jobs on remapped collections.
* Saving large query pipelines may cause OOM failures under high load.\
In Fusion 5.9.13, saving a large query pipeline during high query volume can result in thread lock, excessive memory use, and eventual OOM errors in the Query service.\
This issue is fixed in Fusion 5.9.14.
* Some S3 and Web datasource jobs cannot be stopped in Fusion 5.9.13.\
Clicking the Stop button has no effect in some cases where the backend job is no longer being tracked. This causes the `job-config` service to ignore the job and prevents the system from updating the job status. A workaround is to issue a `POST {"action": "start"}` to the appropriate job actions endpoint, which aborts the stuck job.\
This issue is fixed in Fusion 5.9.14.
* Spark jobs may disappear from the job list after pod deletion\
In Fusion 5.9.12 and 5.9.13, Spark jobs may vanish from the job list if a Spark driver pod is deleted. This behavior can cause confusion and require a job-launcher restart to restore job visibility.\
This issue is fixed in Fusion 5.9.13.
## Deprecations and removals
For full details, see [Deprecations and Removals](/docs/5/fusion/deprecations-and-removals).
### Bitnami removal
Fusion 5.9.13 will be re-released with the same functionality but updated image references.
In the meantime, Lucidworks will self-host the required images while we work to replace Bitnami images with internally built open-source alternatives.
If you are a self-hosted Fusion customer, *you must upgrade before August 28* to ensure continued access to container images and prevent deployment issues.
You can reinstall your current version of Fusion or upgrade to Fusion 5.9.14, which includes the updated Helm chart and prepares your environment for long-term compatibility.
See [Prevent image pull failures due to Bitnami deprecation in Fusion 5.9.5 to 5.9.13](https://support.lucidworks.com/hc/en-us/articles/33966125467799-Prevent-image-pull-failures-due-to-Bitnami-deprecation-in-Fusion-5-9-5-to-5-9-13) for more information on how to prevent image pull failures.
### Hybrid Query pipeline stage
The [Hybrid Query pipeline stage](/docs/5/fusion/reference/config-ref/pipeline-stages/query-stages/hybrid-search-query) is now deprecated.
Instead, use the [Neural Hybrid Query stage](/docs/5/fusion/reference/config-ref/pipeline-stages/query-stages/neural-hybrid-query), which combines lexical and vector search and includes improvements such as K-Nearest Neighbors (KNN), chunking, and more.
### Container image for `kafka-exporter`
Bitnami stopped supporting `kafka-exporter` and renamed the [docker repository](https://hub.docker.com/r/bitnamilegacy/kafka-exporter-archived) from `bitnami/kafka-exporter` to `bitnami/kafka-exporter-archived`.
If you were using `kafka-exporter`, then you need to update the repository name in your `values.yaml` file:
```yaml theme={"dark"}
kafka.metrics.kafka.image.repository=bitnami/kafka-exporter-archived
```
Changing the repository name will allow you to continue using Kafka metrics evaluation with Prometheus/Grafana.
### Removed deprecated `X-XSS-Protection` header from session API responses
Fusion 5.9.13 removes the deprecated `X-XSS-Protection` HTTP response header from the session API.
This header is no longer supported by modern browsers and has no effect on security behavior.
Its removal helps avoid confusion during security audits and aligns with current web security standards.
## Platform support and component versions
### Kubernetes platform support
Lucidworks has tested and validated support for the following Kubernetes platforms and versions:
* **Google Kubernetes Engine (GKE):** 1.29, 1.30, 1.31, 1.32
* **Microsoft Azure Kubernetes Service (AKS):** 1.29, 1.30, 1.31, 1.32
* **Amazon Elastic Kubernetes Service (EKS):** 1.29, 1.30, 1.31, 1.32
Support is also offered for Rancher Kubernetes Engine (RKE and RKE2) and OpenShift 4 versions that are based on Kubernetes 1.29, 1.30, 1.31, 1.32; note that RKE2 may require some Helm chart modification. OpenStack and customized Kubernetes installations are *not* supported.
For more information on Kubernetes version support, see the [Kubernetes support policy](/docs/policies/lifecycle-policies/lw-version-support-lifecycle#kubernetes-support).
### Component versions
The following table details the versions of key components that may be critical to deployments and upgrades.
| Component | Version |
| ------------------- | ------------------------------------------------- |
| Solr | fusion-solr 5.9.13 *(based on Solr 9.6.1)* |
| ZooKeeper | 3.9.1 |
| Spark | 3.4.1 |
| Ingress Controllers | Nginx, Ambassador (Envoy), GKE Ingress Controller |
| Ray | ray\[serve] 2.42.1 |
More information about support dates can be found at [Lucidworks Fusion Product Lifecycle](/docs/policies/lifecycle-policies/lw-version-support-lifecycle).