> ## Documentation Index
> Fetch the complete documentation index at: https://doc.lucidworks.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Fusion Server 4.2.4 Release Notes
[localhost link]: http://localhost:3000/docs/4/fusion-server/release-notes/4.2.4-release-notes
[mintlify link]: https://doc.lucidworks.com/docs/4/fusion-server/release-notes/4.2.4-release-notes
[old doc.lw link]: https://doc.lucidworks.com/fusion-server/4.2/89
**Release date:** 3 September 2019
**Component versions:**
| | | | | |
| ---------- | ---------------- | ----------- | ---------------------- | ------------ |
| Solr 7.7.2 | ZooKeeper 3.4.13 | Spark 2.3.2 | Jetty 9.4.19.v20190610 | Ignite 2.6.0 |
**More information about support dates can be found at [Lucidworks Fusion Product Lifecycle](/docs/policies/lifecycle-policies/lw-fusion-product-lifecycle).**
## New features
#### SharePoint Optimized and SharePoint Online Optimized Connectors
Fusion 4.2.4 introduces ground-up rewrite of our SharePoint and SharePoint Online connectors. The new connectors, [SharePoint V1 Optimized](/docs/fusion-connectors/connectors/v1/sharepoint-v1-optimized) and [SharePoint Online V1 Optimized](/docs/fusion-connectors/connectors/v1/sharepoint-online-v1-optimized), offer a variety of new features and benefits, including:
* Performance of the initial crawl and incremental crawls have been significantly improved.
* Security trimming has been centralized so it can be shared between different connector configurations. This is handled by the [Active Directory Connector for ACLs](#active-directory-connector-for-acls).
 * More options are available for limiting documents.
* More options are available for limiting documents.
 * More options are available for customizing crawl performance.
* More options are available for customizing crawl performance.
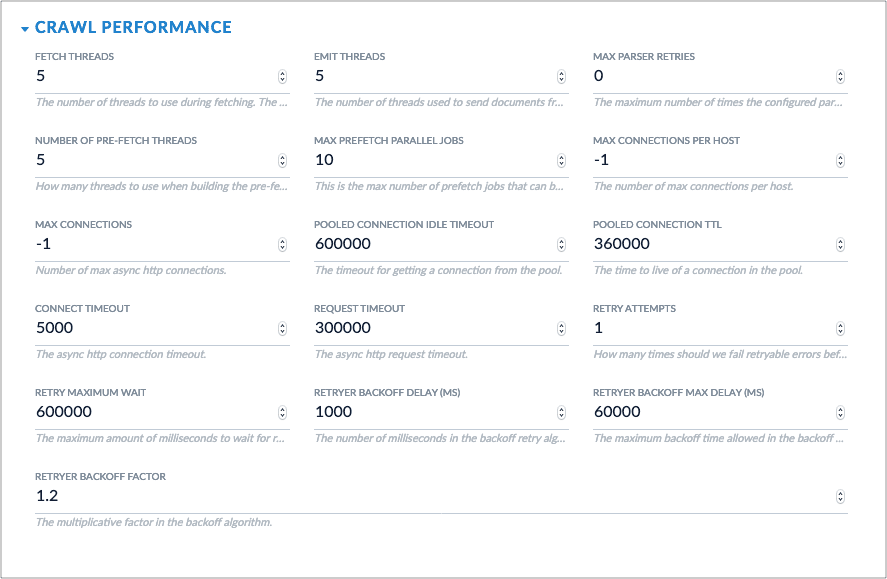 Users are encouraged to upgrade from the classic connectors to the optimized connectors.
#### Active Directory Connector for ACLs
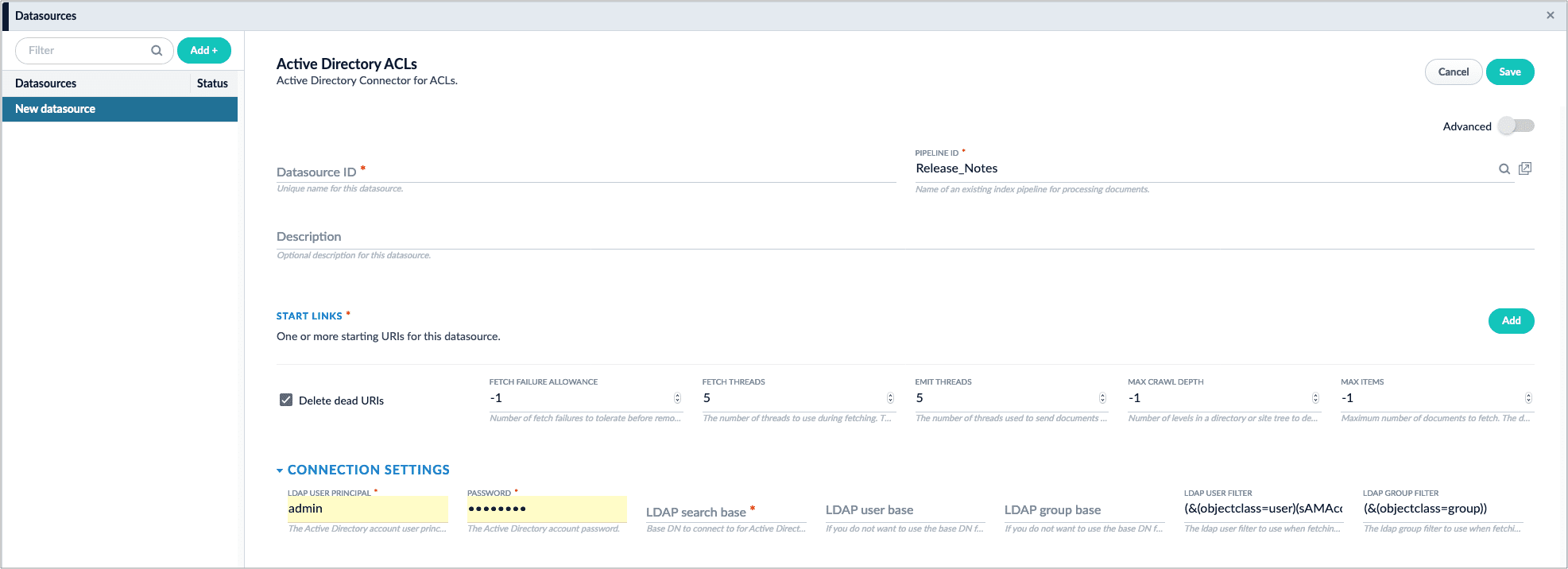
The new [Active Directory Connector for ACLs](/docs/fusion-connectors/concepts/ad-acl) indexes Access Control List (ACL) information into a configured collection so that it can be used by the SharePoint Optimized and SharePoint Online Optimized connectors.
Users are encouraged to upgrade from the classic connectors to the optimized connectors.
#### Active Directory Connector for ACLs
The new [Active Directory Connector for ACLs](/docs/fusion-connectors/concepts/ad-acl) indexes Access Control List (ACL) information into a configured collection so that it can be used by the SharePoint Optimized and SharePoint Online Optimized connectors.
 #### Forked Apache Tika Parser
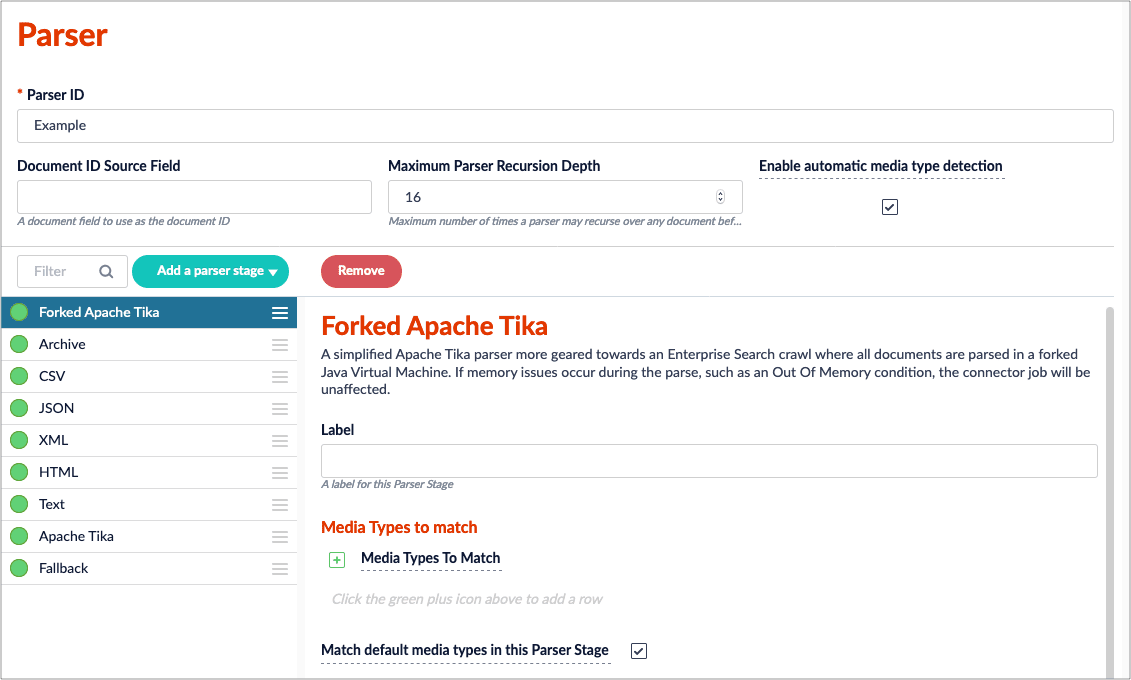
Fusion Server 4.2.4 adds a new parser, the [Forked Apache Tika parser](/docs/4/fusion-server/reference/parser-stages/forked-apache-tika-parser). This parser is a simplified Apache Tika parser geared towards an Enterprise Search crawl in which all documents are parsed in a forked Java Virtual Machine. If memory issues occur while parsing, such as an Out Of Memory condition, the connector job is unaffected.
#### Forked Apache Tika Parser
Fusion Server 4.2.4 adds a new parser, the [Forked Apache Tika parser](/docs/4/fusion-server/reference/parser-stages/forked-apache-tika-parser). This parser is a simplified Apache Tika parser geared towards an Enterprise Search crawl in which all documents are parsed in a forked Java Virtual Machine. If memory issues occur while parsing, such as an Out Of Memory condition, the connector job is unaffected.
 #### Auto-scaling Policies
Fusion now supports search, analytics, and system auto-scaling policies for application and system collections. When creating a collection in Solr, Fusion enables autoscaling by passing a policy parameter to apply an auto-scaling `policy` to the collection.
This functionality uses [Solr’s auto-scaling policies](https://lucene.apache.org/solr/guide/7_6/solrcloud-autoscaling.html).
## Improvements
* The Rules UI now supports bulk actions, including **Add Tags**, **Enable**, **Disable**, and **Delete**. test
[](/assets/images/4.2/animations/new-feature-bulk-actions.webm)
* Fields in the Rules UI now support typeahead.
[](/assets/images/4.2/animations/new-feature-typeahead.webm)
* In Rules, the Field Value filter queries, `fq`, are no longer required to be a perfect match. For example, the following filter queries return the same result:
* `fq=foo:bar`
* `fq=foo:("bar")`
* `fq={!tag=foo}foo:bar`
* When deleting a rule from a list of rules, you remain on the current page instead of being sent to page 1.
* CrawlDB operations now let MapDB store information in multiple files instead of just one. This enables a user to delete an individual table by deleting the corresponding MapDB file.\
This change affects V1 connectors that support bulk import operations. Other connectors are unaffected by this change.
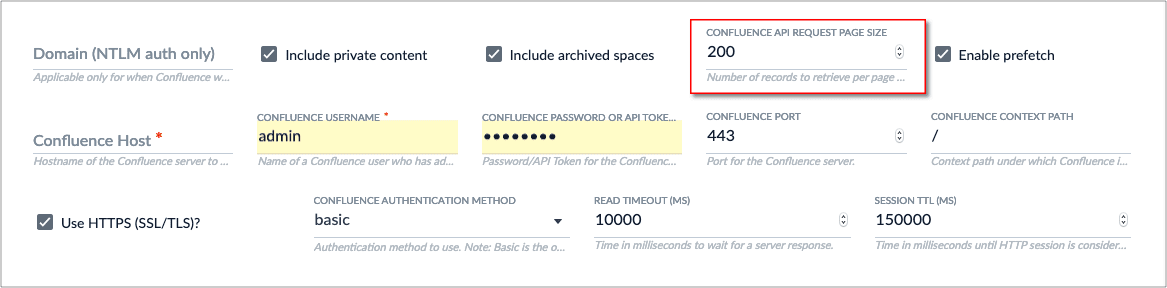
* The Confluence connector now uses prefetch logic to significantly improve crawl performance.
#### Auto-scaling Policies
Fusion now supports search, analytics, and system auto-scaling policies for application and system collections. When creating a collection in Solr, Fusion enables autoscaling by passing a policy parameter to apply an auto-scaling `policy` to the collection.
This functionality uses [Solr’s auto-scaling policies](https://lucene.apache.org/solr/guide/7_6/solrcloud-autoscaling.html).
## Improvements
* The Rules UI now supports bulk actions, including **Add Tags**, **Enable**, **Disable**, and **Delete**. test
[](/assets/images/4.2/animations/new-feature-bulk-actions.webm)
* Fields in the Rules UI now support typeahead.
[](/assets/images/4.2/animations/new-feature-typeahead.webm)
* In Rules, the Field Value filter queries, `fq`, are no longer required to be a perfect match. For example, the following filter queries return the same result:
* `fq=foo:bar`
* `fq=foo:("bar")`
* `fq={!tag=foo}foo:bar`
* When deleting a rule from a list of rules, you remain on the current page instead of being sent to page 1.
* CrawlDB operations now let MapDB store information in multiple files instead of just one. This enables a user to delete an individual table by deleting the corresponding MapDB file.\
This change affects V1 connectors that support bulk import operations. Other connectors are unaffected by this change.
* The Confluence connector now uses prefetch logic to significantly improve crawl performance.
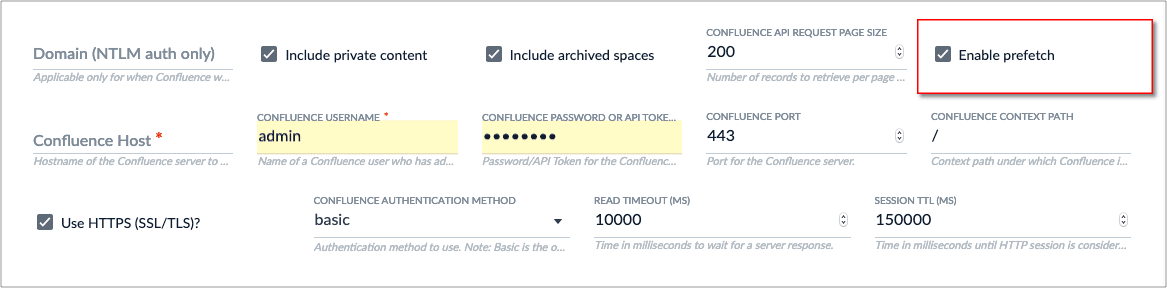 * The Confluence connector has a new property, `CONFLUENCE API REQUEST PAGE SIZE`, which specifies the number of records per response page for REST API calls to Confluence.
* The Confluence connector has a new property, `CONFLUENCE API REQUEST PAGE SIZE`, which specifies the number of records per response page for REST API calls to Confluence.
 * Minor improvements are made to the Jobs panel.
* Minor improvements are made to the Scheduler panel.
## Other changes
* Fixed an issue introduced in Fusion 4.2.0 that occasionally caused the Fusion proxy service to become stuck while under load and resulted in user authentication to fail.
* [Jersey](https://jersey.github.io) has been updated to version 2.29.
* Fusion now saves the facet rule `minCount` value as expected.
* The facet fields in **Rules > Business Rules** now display correctly.
* Aggregation jobs can now run incrementally as documents are [updated incrementally](https://solr.apache.org/guide/solr/latest/indexing-guide/partial-document-updates.html).
* Fixed a bug that stopped recommender jobs from detecting associated recommendation collections.
* Fixed a memory leak in the Security Trimming stage of the Alfresco connector.
* Updated the `Boost List` and `Bury List` rules so they do not conflict if both are triggered for the same query.
* Fixed a Head/Tail Analysis Job UI bug that prevented a job from being saved if the `KEYWORD BLOB NAME` was modified before being cleared.
* Fixed a UI bug in Rules that left the Publish process active after changes were made to a deactivated rule.
* Fixed an empty dialog box which appeared while importing an app after starting over.
* Fixed a bug that prevents App Insights and App Studio from accessing authentication tokens or session tokens if Fusion is running with Trusted HTTP enabled.
* Fixed a bug in **Rules > Business Rules** that prevented users from sorting rules by date if only rules with future dates were present.
* Fixed a bug that prevented machine learning models from being recreated after being deleted from the blob store.
* Unnecessary items are now deleted from the CrawlDB database as expected after the crawl is completed. This change affects V2 connectors only.
* Each connector job now remains dedicated to the node on which it originally ran.
* Access control items are now indexed in batches instead of one at a time in V2 connectors.
* The HTML parser can now parse more media types, including plain text.
## Known issues
* Security trimming on the Alfresco connector may result in a Solr error. This is fixed in [Fusion 4.2.5](/docs/4/fusion-server/release-notes/4.2.5-release-notes).
* If a document moves, the Alfresco connector will attempt to index the document at the previous *and* current location.
This is fixed in Fusion 4.2.6.
* The Alfresco connector will attempt to index old and new versions of a document.
This is fixed in Fusion 4.2.6.
* The Alfresco connector will not update the `acls_ss` field unless **Force Recrawl** is selected.
This is fixed in Fusion 4.2.6.
* Minor improvements are made to the Jobs panel.
* Minor improvements are made to the Scheduler panel.
## Other changes
* Fixed an issue introduced in Fusion 4.2.0 that occasionally caused the Fusion proxy service to become stuck while under load and resulted in user authentication to fail.
* [Jersey](https://jersey.github.io) has been updated to version 2.29.
* Fusion now saves the facet rule `minCount` value as expected.
* The facet fields in **Rules > Business Rules** now display correctly.
* Aggregation jobs can now run incrementally as documents are [updated incrementally](https://solr.apache.org/guide/solr/latest/indexing-guide/partial-document-updates.html).
* Fixed a bug that stopped recommender jobs from detecting associated recommendation collections.
* Fixed a memory leak in the Security Trimming stage of the Alfresco connector.
* Updated the `Boost List` and `Bury List` rules so they do not conflict if both are triggered for the same query.
* Fixed a Head/Tail Analysis Job UI bug that prevented a job from being saved if the `KEYWORD BLOB NAME` was modified before being cleared.
* Fixed a UI bug in Rules that left the Publish process active after changes were made to a deactivated rule.
* Fixed an empty dialog box which appeared while importing an app after starting over.
* Fixed a bug that prevents App Insights and App Studio from accessing authentication tokens or session tokens if Fusion is running with Trusted HTTP enabled.
* Fixed a bug in **Rules > Business Rules** that prevented users from sorting rules by date if only rules with future dates were present.
* Fixed a bug that prevented machine learning models from being recreated after being deleted from the blob store.
* Unnecessary items are now deleted from the CrawlDB database as expected after the crawl is completed. This change affects V2 connectors only.
* Each connector job now remains dedicated to the node on which it originally ran.
* Access control items are now indexed in batches instead of one at a time in V2 connectors.
* The HTML parser can now parse more media types, including plain text.
## Known issues
* Security trimming on the Alfresco connector may result in a Solr error. This is fixed in [Fusion 4.2.5](/docs/4/fusion-server/release-notes/4.2.5-release-notes).
* If a document moves, the Alfresco connector will attempt to index the document at the previous *and* current location.
This is fixed in Fusion 4.2.6.
* The Alfresco connector will attempt to index old and new versions of a document.
This is fixed in Fusion 4.2.6.
* The Alfresco connector will not update the `acls_ss` field unless **Force Recrawl** is selected.
This is fixed in Fusion 4.2.6.