{formatDescription(description)}
} {visibleProps.map(([name, prop]) => { const isRequired = requiredProps.includes(name); const hasDefault = prop.default !== undefined; const rawDefault = prop.default; const isComplexDefault = hasDefault && (typeof rawDefault === "object" || typeof rawDefault === "string" && (rawDefault.length > 20 || rawDefault.includes('"'))); const fieldProps = { key: name, body: prop.title || name, type: prop.type, ...prop.title && ({ post: [<>API property: {name}] }), ...isRequired && ({ required: true }), ...!isComplexDefault && hasDefault ? { default: sanitize(String(rawDefault)) } : {} }; const isObject = prop.type === "object" && prop.properties; const isArrayOfObjects = prop.type === "array" && prop.items?.type === "object" && prop.items.properties; return{formatDescription(prop.description)}
} {isComplexDefault &&Default:
{JSON.stringify(rawDefault, null, 2)}
Object attributes:
{'{\n'}
{Object.entries(prop.items.properties).map(([iname, iprop]) => <>
{` ${iname}`}
{prop.items?.required?.includes(iname) && required}
{`: {\n display name: ${sanitize(iprop.title || '')}\n type: ${iprop.type}\n }\n`}
)}
{'}'}
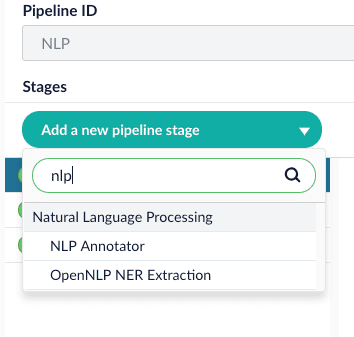 2. Choose the annotator type (OpenNLP or SparkNLP).
2. Choose the annotator type (OpenNLP or SparkNLP).
 If you select the `sparknlp` model, you need to download and install one or more models:
.. Download the models at [https://github.com/JohnSnowLabs/spark-nlp#models](https://github.com/JohnSnowLabs/spark-nlp#models).
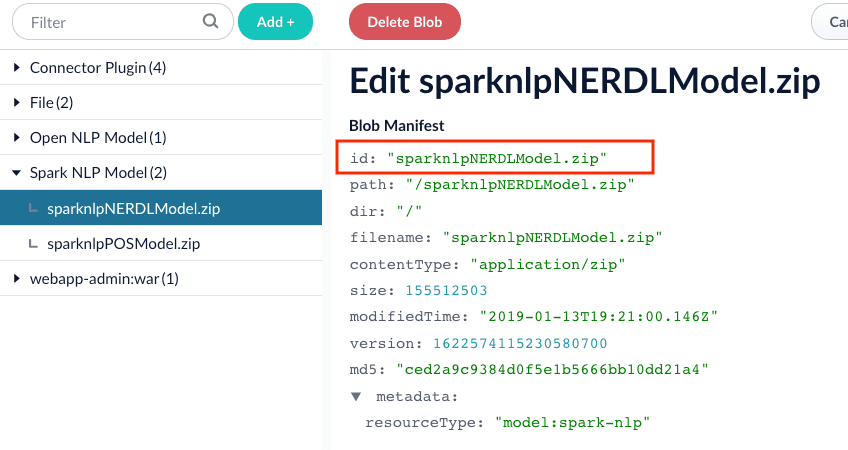
.. Rename the downloaded models to something easy to identify, then upload them to Fusion’s [blob store](/docs/4/fusion-server/concepts/indexing/blob-storage).
*
If you select the `sparknlp` model, you need to download and install one or more models:
.. Download the models at [https://github.com/JohnSnowLabs/spark-nlp#models](https://github.com/JohnSnowLabs/spark-nlp#models).
.. Rename the downloaded models to something easy to identify, then upload them to Fusion’s [blob store](/docs/4/fusion-server/concepts/indexing/blob-storage).
*
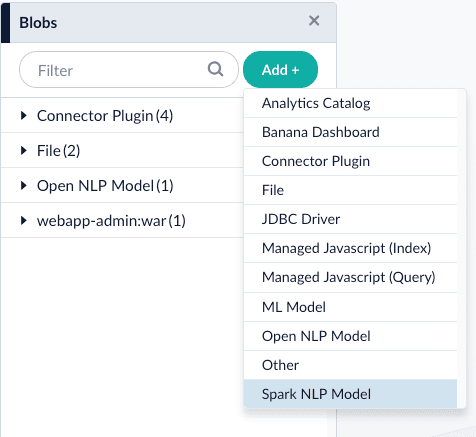 3\. Configure the index pipeline stage:
1. Specify the model to use (fill the box with `model id` in the blob store).
3\. Configure the index pipeline stage:
1. Specify the model to use (fill the box with `model id` in the blob store).
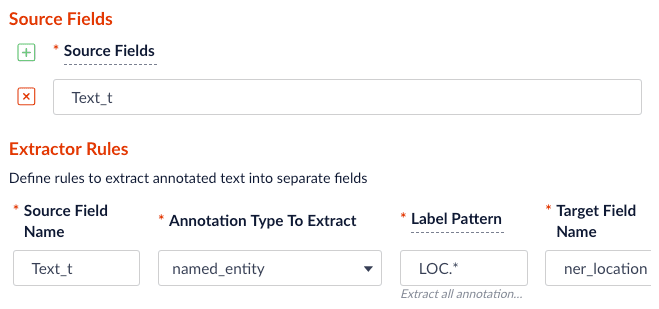
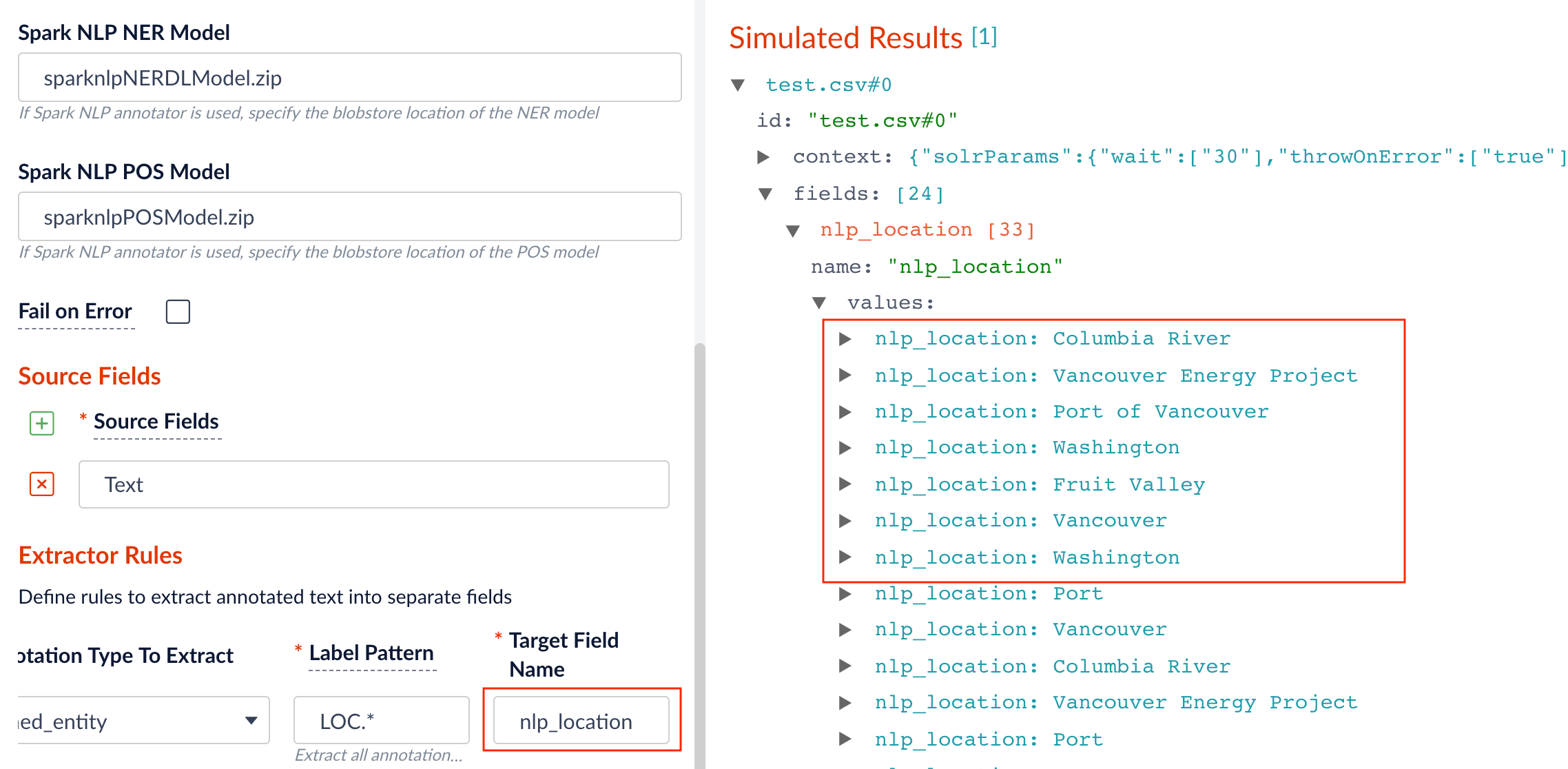
 2. Specify the source, label pattern, and target (destination) fields:
* source field: the raw text with name entities to be extracted.
* label pattern: regex pattern that matches the NER/POS labels: for example, `PER.` will match extracted name entities with label `PERSON`, while `NN.` will match tagged nouns.
* target field: the outcome extraction/tagging and so on.
2. Specify the source, label pattern, and target (destination) fields:
* source field: the raw text with name entities to be extracted.
* label pattern: regex pattern that matches the NER/POS labels: for example, `PER.` will match extracted name entities with label `PERSON`, while `NN.` will match tagged nouns.
* target field: the outcome extraction/tagging and so on.