> ## Documentation Index
> Fetch the complete documentation index at: https://doc.lucidworks.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Ingest and Indexing
export const LwTemplate = ({title = "Key questions to get you started", icon = "sparkles", cta = "Powered by Agent Studio", linkHref = "https://lucidworks.com/demo/?utm_source=docs&utm_medium=referral&utm_campaign=docs_cta_ai"}) => {
const [isLoaded, setIsLoaded] = useState(false);
useEffect(() => {
const timer = setTimeout(() => {
setIsLoaded(true);
}, 500);
return () => clearTimeout(timer);
}, []);
return
{isLoaded && `
}} />}
Powered by Lucidworks Agent Studio
;
};
[localhost link]: http://localhost:3000/docs/4/fusion-server/concepts/indexing/overview
[mintlify link]: https://doc.lucidworks.com/docs/4/fusion-server/concepts/indexing/overview
[old doc.lw link]: https://doc.lucidworks.com/fusion/5.9/155
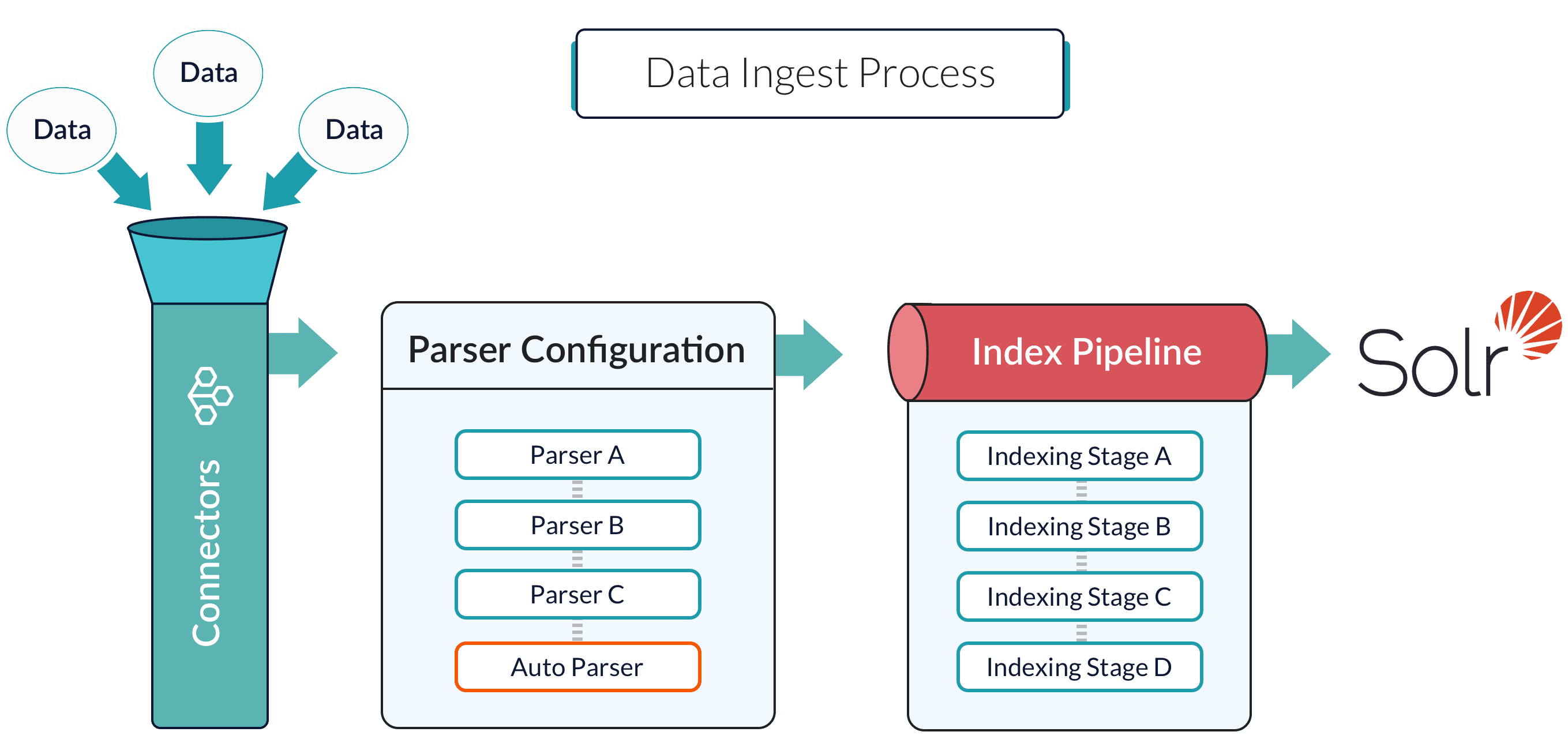
## Data Ingestion
Data ingestion gets your data into Fusion Server, and data indexing stores it in a format that is optimized for searching. These topics explain how to get your data into Fusion Server in a search-optimized format.
### Collections
*Collections* are a way of grouping data sets so that related data sets can be managed together. Every data set that you ingest belongs to a collection. Any app can contain one or more collections. See [Collection Management](/docs/4/fusion-server/concepts/indexing/collections/overview).
### Datasources
*Datasources* are configurations that determine how your data is handled during ingest by Fusion Server’s connectors, parsers, and index pipelines. When you run a fully-configured datasource, the result is an indexed data set that is optimized for search, depending on the shape of your data and how you want to search it. See [Datasource Configuration](/docs/4/fusion-server/concepts/indexing/datasources/overview).
### Connectors
*Connectors* are Fusion components that ingest and parse specific kinds of data. There is a Fusion [connector](/docs/4/fusion-server/concepts/indexing/datasources/overview) for just about any data type.
### Blob storage
[Blob storage](/docs/4/fusion-server/concepts/indexing/blob-storage) is a way to upload binary data to Fusion Server. This can be your own data, such as images or executables, or it can be plugins for Fusion Server, such as connectors, JDBC drivers, and so on.
### Other methods
In some cases, you might find that it is best to use other ingestion methods, such as
the **Import with the Bulk Loader**, **Import Data with Hive**, **Import Data with Pig**, or pushing data to a **Import Data with the REST API** endpoint.
## Create and run Parallel Bulk Loader jobs
Use the [Jobs manager](/docs/4/fusion-server/concepts/jobs/overview) to create and run Parallel Bulk Loader jobs. You can also use the [Scheduler](/docs/4/fusion-server/concepts/jobs/schedules) to schedule jobs.
In the procedures, select **Parallel Bulk Loader** as the job type and [configure the job as needed](#configuration-settings-for-the-parallel-bulk-loader-job).
## Configuration settings for the Parallel Bulk Loader job
This section provides configuration settings for the Parallel Bulk Loader job. Also see configuration properties in the [Jobs Configuration Reference](/docs/4/fusion-ai/reference/jobs/parallel-bulk-loader).
### Read settings
| Setting | Description |
| ------------------------ | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `format` | Unique identifier of the data source provider. Spark scans the job’s `classpath` for a class named `DefaultSource` in the `` package. For example, for the `solr` format, we provide the `solr.DefaultSource` class in our [`spark-solr` repository](https://github.com/lucidworks/spark-solr/blob/master/src/main/scala/solr/DefaultSource.scala): |
| `path` (optional) | Comma-delimited list of paths to load. Some data sources, such as parquet, require a path. Others, such as Solr, do not. Refer to the documentation for your data source to determine if you need to provide a path. |
| `readOptions` | Options passed to the Spark SQL data source to configure the read operation. Options differ for every data source. Refer to the specific data source documentation for more information. |
| `sparkConfig` (optional) | List of Spark configuration settings needed to run the Parallel Bulk Loader. |
| `shellOptions` | Behind the scenes, the Parallel Bulk Loader job submits a Scala script to the Fusion Spark shell. The `shellOptions` setting lets you pass any additional options needed by the Spark shell. The two most common options are `--packages` and `--repositories`: `--packages` Comma-separated list of Maven coordinates of JAR files to include on the driver and executor classpaths. Spark searches the local Maven repository, and then Maven central and any additional remote repositories given in the config. The format for the coordinates should be `groupId:artifactId:version`. The HBase example below demonstrates the use of the packages option for loading the `com.hortonworks:shc-core:1.1.1-2.1-s_2.11` package. TIP: Use the `https://spark-packages.org/` site to find interesting packages to add to your Parallel Bulk Loader jobs. `--repositories` Comma-separated list of additional remote Maven repositories to search for the Maven coordinates given in the `packages` config setting. The [Index HBase tables](#index-hbase-tables) example below demonstrates the use of the `repositories` option for loading the `com.hortonworks:shc-core:1.1.1-2.1-s_2.11` package from the [Hortonworks](https://mvnrepository.com/repos/hortonworks-releases) repository. |
| `timestampFieldName` | For datasources that support time-based filters, the Parallel Bulk Loader computes the timestamp of the last document written to Solr and the current timestamp of the Parallel Bulk Loader job. For example, the HBase data source lets you filter the read between a `MIN_STAMP` and `MAX_STAMP`, for example: `val timeRangeOpts = Map(HBaseRelation.MIN_STAMP -> minStamp.toString, HBaseRelation.MAX_STAMP -> maxStamp.toString)` lets Parallel Bulk Loader jobs run on schedules, and pull only the newest rows from the underlying datasources. To support timestamp based filtering, the Parallel Bulk Loader provides two simple macros: `$lastTimestamp(format)` `$nowTimestamp(format)` The `format` argument is optional. If not supplied, then an ISO-8601 date/time string is used. The `timestampFieldName` setting is used to determine the value of `lastTimestamp`, using a Top 1 query to Solr to get the max timestamp. You can also pass `$lastTimestamp(EPOCH)` or `$lastTimestamp(EPOCH_MS)` to get the timestamp in seconds or milliseconds. See the [Index HBase tables](#index-hbase-tables) example below for an example of using this configuration property. |
### Transformation settings
| Setting | Description |
| ---------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `transformScala` | Sometimes, you can write a small script to transform input data into the correct form for indexing. But at other times, you might need the full power of the Spark API to transform data into an indexable form. The `transformScala` option lets you filter and/or transform the input DataFrame any way you would like. You can even define UDFs to use during your transformation. For an example of using Scala to transform the input DataFrame before indexing in Solr, see the [Read from Parquet](#read-from-parquet) example. Another powerful use of the `transformScala` option is that you can pull in advanced libraries, such as Spark NLP (from John Snow Labs) to do NLP work on your content before indexing. See the [Use NLP during indexing](#use-nlp-during-indexing) example. Your Scala script can do other things but, at a minimum, it must define the function that the Parallel Bulk Loader invokes (see below this table). |
| `transformSql` | The `transformSql` option lets you write a SQL query to transform the input DataFrame. The SQL is executed after the `transformScala` script (if both are defined). The input DataFrame is exposed to your SQL as the `_input` view. See the [Clean up data with SQL transformations](#clean-up-data-with-sql-transformations) example below for an example of using SQL to transform the input before indexing in Solr. This option also lets you leverage the UDF/UDAF functions provided by Spark SQL. |
| `mlModelId` | If you have a Spark ML PipelineModel loaded into the blob store, you can supply the blob ID to the Parallel Bulk Loader and it will: 1. Load the model from the blob store. 2. Transform the input DataFrame (after the Scala transform but before the SQL transform). 3. Add the predicted output field (specified in the model metadata stored in the blob store) to the projected fields list. This lets you use Spark ML models to make predictions in a more scalable, performant manner than what can be achieved with a Machine Learning index stage. |
Function for `transformScala`:
```scala theme={"dark"}
def transform(inputDF: Dataset[Row]) : Dataset[Row] = {
{/* // do transformations and/or filter the inputDF here */}
}
Your script can rely on the following vals:
spark: SparkSession
sc: SparkContext
fusionZKConn: ZKConnection // needed to access Fusion API
solrCollection: SolrCollection // output collection
jobId: Loader job config ID
Also, the following classes have already been imported:
import org.apache.spark.SparkContext._
import spark.implicits._
import spark.sql
import org.apache.spark.sql.functions._
import com.lucidworks.spark.util.{SparkShellSupport => _lw}
import com.lucidworks.spark.job.sql.SparkSQLLoader
import com.lucidworks.spark.ml.recommenders.SolrCollection
import com.lucidworks.spark.ZKConnection
import org.apache.spark.sql.{Dataset, Row}
```
### Output settings
| Setting | Description |
| ------------------------------ | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `outputCollection` | Name of the Fusion collection to write to. The Parallel Bulk Loader uses the Collections API to resolve the underlying Solr collection at runtime. |
| `outputIndexPipeline` | Name of a Fusion index pipeline to which to send documents, instead of directly indexing to Solr. This option lets you perform additional ETL (extract, transform, and load) processing on the documents before they are indexed in Solr. If you need to write to time-partitioned indexes, then you must use an index pipeline, because writing directly to Solr is not partition aware. |
| `defineFieldsUsingInputSchema` | Flag to indicate if the Parallel Bulk Loader should use the input schema to create fields in Solr, after applying the Scala and/or SQL transformations. If `false`, then the Parallel Bulk Loader relies on the Fusion index pipeline and/or Solr field guessing to create the fields. If `true`, only fields that do not exist already in Solr are created. Consequently, if there is a type mismatch between an existing field in Solr and the input schema, you will need to use a transformation to rename the field in the input schema. |
| `clearDatasource` | If checked, the Parallel Bulk Loader deletes any existing documents in the output collection that match the query `_lw_loader_id_s:`. Consequently, the Parallel Bulk Loader adds two metadata fields to each row: `_lw_loader_id_s` and `_lw_loader_job_id_s`. |
| `atomicUpdates` | Flag to send documents directly to Solr as atomic updates instead of as new documents. This option is not supported when using an index profile. Also note that the Parallel Bulk Loader tracking fields `_lw_loader_id_s` and `_lw_loader_job_id_s` are not sent when using atomic updates, so the clear datasource option does not work with documents created using atomic updates. |
| `outputOptions` | Options used when writing directly to Solr. See Spark-Solr: [https://github.com/lucidworks/spark-solr#index-parameters](https://github.com/lucidworks/spark-solr#index-parameters) For example, if your docs are relatively small, you might want to increase the `batch_size` (2000 default) as shown below: |
| `outputPartitions` | Coalesce the DataFrame into N partitions before writing to Solr. This can help spread the indexing work out across more executors that are available in Spark, or limit the parallelism when writing to Solr. |
## Tune performance
As the name of the Parallel Bulk Loader job implies, it is designed to ingest large amounts of data into Fusion by parallelizing the work across your Spark cluster. To achieve scalability, you might need to increase the amount of memory and/or CPU resources allocated to the job.
By default, Fusion’s Spark configuration settings control the resources allocated to Parallel Bulk Loader jobs.
You can pass these properties in the job configuration to override the default Spark shell options:
| Parameter Name | Description and Default |
| ------------------------ | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `--driver-cores` | Cores for the driver Default: `1` |
| `--driver-memory` | Memory for the driver (for example, `1000M` or `2G`) Default: `1024M` |
| `--executor-cores` | Cores per executor Default: 1 in YARN mode, or all available cores on the worker in standalone mode |
| `--executor-memory` | Memory per executor (for example, `1000M` or `2G`) Default: `1G` |
| `--total-executor-cores` | Total cores for all executors Default: Without setting this parameter, the total cores for all executors is the number of executors in YARN mode, or all available cores on all workers in standalone mode. |
## Examples
Here we provide screenshots and example JSON job definitions to illustrate key points about how to load from different data sources.
### Use NLP during indexing
In this example, we leverage the John Snow labs NLP library during indexing. This is just quick-and-dirty to show the concept.
Also see:
* [https://github.com/JohnSnowLabs/spark-nlp](https://github.com/JohnSnowLabs/spark-nlp)
* [https://databricks.com/blog/2017/10/19/introducing-natural-language-processing-library-apache-spark.html](https://databricks.com/blog/2017/10/19/introducing-natural-language-processing-library-apache-spark.html)
Use this transform Scala script:
```scala theme={"dark"}
import com.johnsnowlabs.nlp._
import com.johnsnowlabs.nlp.annotators._
import org.apache.spark.ml.Pipeline
import com.johnsnowlabs.nlp.annotators.sbd.pragmatic.SentenceDetector
def transform(inputDF: Dataset[Row]) : Dataset[Row] = {
val documentAssembler = new DocumentAssembler().setInputCol("plot_txt_en").setOutputCol("document")
val sentenceDetector = new SentenceDetector().setInputCols(Array("document")).setOutputCol("sentences")
val finisher = new Finisher()
.setInputCols("sentences")
.setOutputCols("sentences_ss")
.setOutputAsArray(true)
.setCleanAnnotations(false)
val pipeline = new Pipeline().setStages(Array(documentAssembler,sentenceDetector,finisher))
pipeline.fit(inputDF).transform(inputDF).drop("document").drop("sentences")
}
```
Be sure to add the `JohnSnowLabs:spark-nlp:1.4.2` package using Spark Shell Options.
### Clean up data with SQL transformations
Fusion has a Local Filesystem connector that can handle files such as CSV and JSON files. Using the Parallel Bulk Loader lets you leverage features that are not in the Local Filesystem connector, such as using SQL to clean up the input data.
Use the following SQL to clean up the input data before indexing:
```sql theme={"dark"}
SELECT _c0 as user_id,
CAST(_c1 as INT) as age,
_c2 as gender,
_c3 as occupation,
_c4 as zip_code
FROM _input
Job JSON:
{
"type" : "parallel-bulk-loader",
"id" : "csv",
"format" : "csv",
"path" : "/Users/tjp/dev/lw/projects/fusion-spark-bootcamp/labs/movielens/ml-100k/u.user",
"readOptions" : [ {
"key" : "delimiter",
"value" : "|"
}, {
"key" : "header",
"value" : "false"
} ],
"outputCollection" : "users",
"clearDatasource" : false,
"defineFieldsUsingInputSchema" : true,
"atomicUpdates" : false,
"transformSql" : "SELECT _c0 as user_id, \n CAST(_c1 as INT) as age, \n _c2 as gender,\n _c3 as occupation,\n _c4 as zip_code \n FROM _input"
}
```
### Read from S3
It is easy to read from an S3 bucket without pulling data down to your local workstation first. To avoid exposing your AWS credentials, add them to a file named `core-site.xml` in the `apps/spark-dist/conf` directory, such as:
```xml theme={"dark"}
fs.s3a.access.key???fs.s3a.secret.key???
```
Then you can load files using the S3a protocol, such as: `s3a://sstk-dev/data/u.user`. If you are running a Fusion cluster then each instance of Fusion will need a `core-site.xml` file. S3a is the preferred protocol for reading data into Spark because it uses Amazon’s libraries to read from S3 instead of the legacy Hadoop libraries. If you need other S3 protocols (for example, s3 or s3n) you will need to add the equivalent properties to `core-site.xml`.
You will need to add the `org.apache.hadoop:hadoop-aws:2.7.3` package to the job using the `--packages` Spark option. Also, you will need to exclude the `com.fasterxml.jackson.core:jackson-core,joda-time:joda-time` packages using the `--exclude-packages` option.
You can also read from Google Cloud Storage (GCS), but you will need a few more properties in your `core-site.xml`; see [Installing the Cloud Storage connector](https://cloud.google.com/dataproc/docs/concepts/connectors/install-storage-connector).
### Read from Parquet
Reading from parquet files is built into Spark using the "parquet" format. For additional read options, see
[Configuration of Parquet](https://spark.apache.org/docs/latest/sql-programming-guide.html#configuration).
Job JSON:
```json theme={"dark"}
{
"type" : "parallel-bulk-loader",
"id" : "ecomm demo parquet signals",
"format" : "parquet",
"path" : "./part-00000-c1951958-98ae-4f2a-b7b4-2e3a69fcf403-c000.snappy.parquet",
"outputCollection" : "best-buy_signals",
"clearDatasource" : false,
"defineFieldsUsingInputSchema" : true,
"atomicUpdates" : false
}
```
This example also uses the `transformScala` option to filter and transform the input DataFrame into a better form for indexing using the following Scala script:
```scala theme={"dark"}
import java.util.Calendar
import java.util.Locale
import java.util.TimeZone
def transform(inputDF: Dataset[Row]) : Dataset[Row] = {
{/* // do transformations and/or filter the inputDF here */}
val signalsDF =
inputDF.filter((unix_timestamp($"timestamp_tdt", "MM/dd/yyyy HH:mm:ss.SSS") < 1325376000))
val now = System.currentTimeMillis()
val maxDate = signalsDF.agg(max("timestamp_tdt")).take(1)(0).getAs[java.sql.Timestamp](0).getTime
val diff = now - maxDate
val add_time =
udf((t: java.sql.Timestamp, diff : Long) => new java.sql.Timestamp(t.getTime + diff))
val day_of_week = udf((t: java.sql.Timestamp) => {
val calendar = Calendar.getInstance(TimeZone.getTimeZone("UTC"))
calendar.setTimeInMillis(t.getTime)
calendar.getDisplayName(Calendar.DAY_OF_WEEK, Calendar.LONG, Locale.getDefault)
})
{/* //Remap some columns to bring the timestamps current */}
signalsDF
.withColumnRenamed("timestamp_tdt", "orig_timestamp_tdt").withColumn("timestamp_tdt", add_time($"orig_timestamp_tdt", lit(diff)))
.withColumn("date", $"timestamp_tdt")
.withColumn("tx_timestamp_txt", date_format($"timestamp_tdt", "E YYYY-MM-d HH:mm:ss.SSS Z"))
.withColumn("param.query_time_dt", $"timestamp_tdt")
.withColumn("date_day", date_format(date_sub($"date", 0), "YYYY-MM-d'T'HH:mm:ss.SSS'Z'"))
.withColumn("date_month", date_format(trunc($"date", "mm"), "YYYY-MM-d'T'HH:mm:ss.SSS'Z'"))
.withColumn("date_year", date_format(trunc($"date", "yyyy"), "YYYY-MM-d'T'HH:mm:ss.SSS'Z'"))
.withColumn("day_of_week", day_of_week($"date"))
}
```
### Read from JDBC tables
You can use the Parallel Bulk Loader to parallelize reads from JDBC tables, if the tables have numeric columns that can be partitioned into relatively equal partition sizes. In the example below, we partition the employees table into 4 partitions using the `emp_no` column (`int`). Behind the scenes, Spark sends four separate queries to the database and processes the result sets in parallel.
#### Load the JDBC driver JAR file into the Blob store
Before you ingest from a JDBC data source, you need to use the Fusion Admin UI to upload the JDBC driver JAR file into the blob store.
Alternatively, you can add the JAR file to the Fusion blob store with `resourceType=spark:jar`; for example:
```bash wrap theme={"dark"}
curl -XPUT -H "Content-type:application/octet-stream" "http:///api/blobs/mysql_jdbc_jar?resourceType=spark:jar" --data-binary @mysql-connector-java-5.1.45-bin.jar
```
At runtime, Fusion’s Spark job management framework knows how to add any JAR files with `resourceType=spark:jar` from the blob store to the appropriate classpaths before running a Parallel Bulk Loader job.
#### Read from a table
For more information on reading from JDBC-compliant databases, see:
* [http://spark.apache.org/docs/latest/sql-programming-guide.html#jdbc-to-other-databases](http://spark.apache.org/docs/latest/sql-programming-guide.html#jdbc-to-other-databases)
* [https://medium.com/@radek.strnad/tips-for-using-jdbc-in-apache-spark-sql-396ea7b2e3d3](https://medium.com/@radek.strnad/tips-for-using-jdbc-in-apache-spark-sql-396ea7b2e3d3)
```json theme={"dark"}
{
"type" : "parallel-bulk-loader",
"id" : "load dbtable",
"format" : "jdbc",
"readOptions" : [ {
"key" : "url",
"value" : "jdbc:mysql://localhost/employees?user=?&password=?"
}, {
"key" : "dbtable",
"value" : "employees"
}, {
"key" : "partitionColumn",
"value" : "emp_no"
}, {
"key" : "numPartitions",
"value" : "4"
}, {
"key" : "driver",
"value" : "com.mysql.jdbc.Driver"
}, {
"key" : "lowerBound",
"value" : "$MIN(emp_no)"
}, {
"key" : "upperBound",
"value" : "$MAX(emp_no)"
} ],
"outputCollection" : "employees",
"clearDatasource" : false,
"defineFieldsUsingInputSchema" : true,
"atomicUpdates" : false
}
```
Notice the use of the `$MIN(emp_no)` and `$MAX(emp_no)` macros in the read options. These are macros offered by the Parallel Bulk Loader to help configure parallel reads of JDBC tables. Behind the scenes, the macros are translated into SQL queries to get the MAX and MIN values of the specified field, which Spark uses to compute splits for partitioned queries. As mentioned above, the field must be numeric and must have a relatively balanced distribution of values between MAX and MIN; otherwise, you are unlikely to see much performance benefit to partitioning.
### Index HBase tables
To index an HBase table, use the [Hortonworks connector](https://github.com/hortonworks-spark/shc).
The Parallel Bulk Loader lets us replace the HBase Indexer.
You will need to add an `hbase-site.xml` (and possibly `core-site.xml`) to `apps/spark-dist/conf` in Fusion, for example:
```xml theme={"dark"}
hbase.defaults.for.version.skiptruehbase.zookeeper.quorumlocalhost:2181zookeeper.znode.parent/hbase
```
For this example, we will create a test table in HBase. If you already have a table in HBase, feel free to use that table instead.
1. Launch the HBase shell and create a table named `fusion_nums` with a single column family named `lw`:
```
create 'fusion_nums', 'lw'
```
2. Do a list command to see your table:
```
hbase(main):002:0> list
TABLE
fusion_nums
1 row(s) in 0.0250 seconds
=> ["fusion_nums"]
```
3. Fill the table with some data:
```
for i in '1'..'100' do for j in '1'..'2' do put 'fusion_nums', "row#{i}", "lw:c#{j}", "#{i}#{j}" end end
```
4. Scan the fusion\_nums table to see your data:
```
scan 'fusion_nums'
```
The HBase connector requires a catalog read option that defines the columns you want to read and how to map them into a Spark DataFrame. For our sample table, the following suffices:
```json theme={"dark"}
{
"table":{"namespace":"default", "name":"fusion_nums"},
"rowkey":"key",
"columns":{
"id":{"cf":"rowkey", "col":"key", "type":"string"},
"lw_c1_s":{"cf":"lw", "col":"c1", "type":"string"},
"lw_c2_s":{"cf":"lw", "col":"c2", "type":"string"}
}
}
```
Notice the use of the `$lastTimestamp` macro in the read options. This lets us filter rows read from HBase using the timestamp of the last document the Parallel Bulk Loader wrote to Solr, that is, to get the newest updates from HBase only (incremental updates). Most Spark data sources provide a way to filter results based on timestamp.
Job JSON:
```json theme={"dark"}
{
"type" : "parallel-bulk-loader",
"id" : "hbase",
"format" : "org.apache.spark.sql.execution.datasources.hbase",
"readOptions" : [ {
"key" : "catalog",
"value" : "{ \"table\":{\"namespace\":\"default\", \"name\":\"fusion_nums\"}, \"rowkey\":\"key\", \"columns\":{ \"id\":{\"cf\":\"rowkey\", \"col\":\"key\", \"type\":\"string\"}, \"lw_c1_s\":{\"cf\":\"lw\", \"col\":\"c1\", \"type\":\"string\"}, \"lw_c2_s\":{\"cf\":\"lw\", \"col\":\"c2\", \"type\":\"string\"} } }"
}, {
"key" : "minStamp",
"value" : "$lastTimestamp(EPOCH_MS)"
} ],
"outputCollection" : "hbase",
"timestampFieldName" : "timestamp_tdt",
"clearDatasource" : false,
"defineFieldsUsingInputSchema" : true,
"atomicUpdates" : false,
"shellOptions" : [ {
"key" : "--packages",
"value" : "com.hortonworks:shc-core:1.1.1-2.1-s_2.11"
}, {
"key" : "--repositories",
"value" : "https://mvnrepository.com/repos/hortonworks-releases"
} ]
}
```
### Index Elastic data
With Elasticsearch 6.2.2 using the `org.elasticsearch:elasticsearch-spark-20_2.11:6.2.1` package, here is a Scala script to run in `bin/spark-shell` to index some test data:
```scala theme={"dark"}
import spark.implicits._
case class SimpsonCharacter(name: String, actor: String, episodeDebut: String)
val simpsonsDF = sc.parallelize(
SimpsonCharacter("Homer", "Dan Castellaneta", "Good Night") ::
SimpsonCharacter("Marge", "Julie Kavner", "Good Night") ::
SimpsonCharacter("Bart", "Nancy Cartwright", "Good Night") ::
SimpsonCharacter("Lisa", "Yeardley Smith", "Good Night") ::
SimpsonCharacter("Maggie", "Liz Georges and more", "Good Night") ::
SimpsonCharacter("Sideshow Bob", "Kelsey Grammer", "The Telltale Head") :: Nil).toDF()
val writeOpts = Map("es.nodes" -> "127.0.0.1",
"es.port" -> "9200",
"es.index.auto.create" -> "true",
"es.resouce.auto.create" -> "shows/simpsons")
simpsonsDF.write.format("org.elasticsearch.spark.sql").mode("Overwrite").save("shows/simpsons")
```
Job JSON:
```json theme={"dark"}
{
"type" : "parallel-bulk-loader",
"id" : "elastic",
"format" : "org.elasticsearch.spark.sql",
"readOptions" : [ {
"key" : "es.nodes",
"value" : "127.0.0.1"
}, {
"key" : "es.port",
"value" : "9200"
}, {
"key" : "es.resource",
"value" : "shows/simpsons"
} ],
"outputCollection" : "hbase_signals_aggr",
"clearDatasource" : false,
"defineFieldsUsingInputSchema" : true,
"atomicUpdates" : false,
"shellOptions" : [ {
"key" : "--packages",
"value" : "org.elasticsearch:elasticsearch-spark-20_2.11:6.2.2"
} ]
}
```
### Read from Couchbase
To index a Couchbase bucket, use the official Couchbase Spark connector found [here](https://spark-packages.org/package/couchbase/couchbase-spark-connector).
For example, we will create a test bucket in Couchbase. If you already have a bucket in Couchbase, feel free to use that and skip to the test data setup section. This test was performed using Couchbase Server 6.0.0.
1. Create a bucket test in the Couchbase admin UI. Give access to a system account user to use in the Parallel Bulk Loader job config.
2. Connect to Couchbase using the command line client cbq. For example, `cbq -e=http://:8091 -u -p `. Ensure the provided user is an authorized user of the test bucket.
3. Create a primary index on the test bucket: `CREATE PRIMARY INDEX 'test-primary-index' ON 'test' USING GSI;`.
4. Insert some data: `INSERT INTO 'test' ( KEY, VALUE ) VALUES ( "1", { "id": "01", "field1": "a value", "field2": "another value"} ) RETURNING META().id as docid, *;`.
5. Verify you can query the document just inserted: `select * from 'test';`.
To ingest from this bucket with the Parallel Bulk Loader, use the Couchbase Spark connector by specifying the format `com.couchbase.spark.sql.DefaultSource`. Then specify the `com.couchbase.client:spark-connector_2.11:2.2.0` package as the `spark shell --packages` option, as well as a few spark settings that direct the connector to a particular Couchbase server and bucket to connect to using the provided credentials. See [here](https://docs.couchbase.com/spark-connector/current/getting-started.html) for all of the available Spark configuration settings for the Couchbase Spark connector.
Putting it all together:
### XML setup
XML is a supported format that requires settings for `format` and `--packages`. In addition, you must specify the filepath in the `readOptions` section. For example:
```json theme={"dark"}
{
"type": "parallel-bulk-loader",
"id": "pbl",
"format": "com.databricks.spark.xml",
"path": "this-is-ignored",
"readOptions": [
{
"key": "rowTag",
"value": "tag_name_representing_record"
},
{
"key": "path",
"value": "/home/user/file.xml.gz"
}
],
"outputCollection": "output_collection_name",
"clearDatasource": true,
"defineFieldsUsingInputSchema": true,
"atomicUpdates": false,
"transformScala": "",
"shellOptions": [
{
"key": "--packages",
"value": "com.databricks:spark-xml_2.11:0.5.0"
}
],
"cacheAfterRead": false
}
```
Fusion ships with a Serializer/Deserializer (SerDe) for Hive, included in the distribution as `lucidworks-hive-serde-v2.2.6.jar` in `$FUSION_HOME/apps/connectors/resources/lucid.hadoop/jobs`.
For Fusion 4.1.x and 4.2.x, the preferred method of importing data with Hive is to use the Parallel Bulk Loader. The import procedure does not apply to Fusion 5.x.
## Prerequisites
This section covers prerequisites and background knowledge needed to help you understand the structure of this document and how the Fusion installation process works with Kubernetes.
### Release Name and Namespace
Before installing Fusion, you need to choose a [https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/Kubernetes](https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/Kubernetes) namespace to install Fusion into.
Think of a K8s namespace as a virtual cluster within a physical cluster. You can install multiple instances of Fusion in the same cluster *in separate namespaces*.
However, please *do not* install more than one Fusion release in the same namespace.
All Fusion services must run in the same namespace, i.e. you should not try to split a Fusion cluster across multiple namespaces.\_\_
Use a short name for the namespace, containing only letters, digits, or dashes (no dots or underscores). The setup scripts in this repo use the namespace for the Helm release name by default.
### Install Helm
Helm is a package manager for Kubernetes that helps you install and manage applications on your Kubernetes cluster.
Regardless of which Kubernetes platform you're using, you need to install *`helm`* as it is required to install Fusion for any K8s platform.
On MacOS, you can do:
```bash theme={"dark"}
brew install kubernetes-helm
```
If you already have helm installed, make sure you're using the latest version:
```bash theme={"dark"}
brew upgrade kubernetes-helm
```
For other OS, please refer to the Helm installation docs: [https://helm.sh/docs/using\_helm/](https://helm.sh/docs/using_helm/)
The Fusion helm chart requires that helm is greater than version `3.0.0`; check your Helm version by running `helm version --short`.
#### Helm User Permissions
If you require that fusion is installed by a user with minimal permissions, instead of an admin user, then the role and cluster role that will have to be assigned to the user within the namespace that you wish to install fusion in are documented in the `install-roles` directory.
When working with Kubernetes on the command-line, it's useful to create a shell alias for `kubectl`, e.g.:
```bash theme={"dark"}
alias k=kubectl
```
To use these role in a cluster, as an admin user first create the namespace that you wish to install fusion into:
```bash theme={"dark"}
k create namespace fusion-namespace
```
Apply the `role.yaml` and `cluster-role.yaml` files to that namespace
```bash theme={"dark"}
k apply -f cluster-role.yaml
k config set-context --current --namespace=$NAMESPACE
k apply -f role.yaml
```
Then bind the rolebinding and clusterolebinding to the install user:
```bash wrap theme={"dark"}
k create --namespace fusion-namespace rolebinding fusion-install-rolebinding --role fusion-installer --user
k create clusterrolebinding fusion-install-rolebinding --clusterrole fusion-installer --user
```
You will then be able to run the `helm install` command as the ``
### Clone fusion-cloud-native from GitHub
You should clone this repo from github as you'll need to run the scripts on your local workstation:
```bash theme={"dark"}
git clone https://github.com/lucidworks/fusion-cloud-native.git
```
You should get into the habit of pulling this repo for the latest changes before performing any maintenance operations on your Fusion cluster to ensure you have the latest updates to the scripts.
```bash theme={"dark"}
cd fusion-cloud-native
git pull
```
Cloning the github repo is preferred so that you can pull in updates to the scripts, but if you are not a git user, then you can download the project: [https://github.com/lucidworks/fusion-cloud-native/archive/master.zip](https://github.com/lucidworks/fusion-cloud-native/archive/master.zip).
Once downloaded, extract the zip and cd into the `fusion-cloud-native-master` directory.
## Prerequisites
This section covers prerequisites and background knowledge needed to help you understand the structure of this document and how the Fusion installation process works with Kubernetes.
### Release Name and Namespace
Before installing Fusion, you need to choose a [https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/Kubernetes](https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/Kubernetes) namespace to install Fusion into.
Think of a K8s namespace as a virtual cluster within a physical cluster. You can install multiple instances of Fusion in the same cluster *in separate namespaces*.
However, please *do not* install more than one Fusion release in the same namespace.
All Fusion services must run in the same namespace, i.e. you should not try to split a Fusion cluster across multiple namespaces.\_\_
Use a short name for the namespace, containing only letters, digits, or dashes (no dots or underscores). The setup scripts in this repo use the namespace for the Helm release name by default.
### Install Helm
Helm is a package manager for Kubernetes that helps you install and manage applications on your Kubernetes cluster.
Regardless of which Kubernetes platform you're using, you need to install *`helm`* as it is required to install Fusion for any K8s platform.
On MacOS, you can do:
```bash theme={"dark"}
brew install kubernetes-helm
```
If you already have helm installed, make sure you're using the latest version:
```bash theme={"dark"}
brew upgrade kubernetes-helm
```
For other OS, please refer to the Helm installation docs: [https://helm.sh/docs/using\_helm/](https://helm.sh/docs/using_helm/)
The Fusion helm chart requires that helm is greater than version `3.0.0`; check your Helm version by running `helm version --short`.
#### Helm User Permissions
If you require that fusion is installed by a user with minimal permissions, instead of an admin user, then the role and cluster role that will have to be assigned to the user within the namespace that you wish to install fusion in are documented in the `install-roles` directory.
When working with Kubernetes on the command-line, it's useful to create a shell alias for `kubectl`, e.g.:
```bash theme={"dark"}
alias k=kubectl
```
To use these role in a cluster, as an admin user first create the namespace that you wish to install fusion into:
```bash theme={"dark"}
k create namespace fusion-namespace
```
Apply the `role.yaml` and `cluster-role.yaml` files to that namespace
```bash theme={"dark"}
k apply -f cluster-role.yaml
k config set-context --current --namespace=$NAMESPACE
k apply -f role.yaml
```
Then bind the rolebinding and clusterolebinding to the install user:
```bash wrap theme={"dark"}
k create --namespace fusion-namespace rolebinding fusion-install-rolebinding --role fusion-installer --user
k create clusterrolebinding fusion-install-rolebinding --clusterrole fusion-installer --user
```
You will then be able to run the `helm install` command as the ``
### Clone fusion-cloud-native from GitHub
You should clone this repo from github as you'll need to run the scripts on your local workstation:
```bash theme={"dark"}
git clone https://github.com/lucidworks/fusion-cloud-native.git
```
You should get into the habit of pulling this repo for the latest changes before performing any maintenance operations on your Fusion cluster to ensure you have the latest updates to the scripts.
```bash theme={"dark"}
cd fusion-cloud-native
git pull
```
Cloning the github repo is preferred so that you can pull in updates to the scripts, but if you are not a git user, then you can download the project: [https://github.com/lucidworks/fusion-cloud-native/archive/master.zip](https://github.com/lucidworks/fusion-cloud-native/archive/master.zip).
Once downloaded, extract the zip and cd into the `fusion-cloud-native-master` directory.
# Hive SerDe
This project includes tools to build a Hive SerDe to index Hive tables to Solr.
## Features
* Index Hive table data to Solr.
* Read Solr index data to a Hive table.
* Kerberos support for securing communication between Hive and Solr.
* As of v2.2.4 of the SerDe, integration with [http://lucidworks.com/products](http://lucidworks.com/products) is supported.
\*Fusion's index pipelines can be used to index data to Fusion.
\*Fusion's query pipelines can be used to query Fusion's Solr instance for data to insert into a Hive table.
This version of `hive-solr` supports Hive 3.0.0. For support for Hive 1.x, see the `hive_1x` branch.
`hive-solr` should only be used with Solr 5.0 and higher.
## Build the SerDe Jar
This project has a dependency on the `solr-hadoop-common` submodule (contained in a separate GitHub repository, [https://github.com/lucidworks/solr-hadoop-common](https://github.com/lucidworks/solr-hadoop-common)). This submodule must be initialized before building the SerDe .jar.
You must use Java 8 or higher to build the .jar.
To initialize the submodule, pull this repo, then:
```bash theme={"dark"}
git submodule init
```
Once the submodule has been initialized, the command `git submodule update` will fetch all the data from that project and check out the appropriate commit listed in the superproject. You must initialize and update the submodule before attempting to build the SerDe jar.
* If a build is happening from a branch, make sure that `solr-hadoop-common` is pointing to the correct SHA.
(See [https://github.com/blog/2104-working-with-submodules](https://github.com/blog/2104-working-with-submodules) for more details.)
```bash theme={"dark"}
hive-solr $ git checkout
hive-solr $ cd solr-hadoop-common
hive-solr/solr-hadoop-common $ git checkout
hive-solr/solr-hadoop-common $ cd ..
```
The build uses Gradle. However, you do not need to have Gradle already installed before attempting to build.
To build the jar files, run this command:
```bash theme={"dark"}
./gradlew clean shadowJar --info
```
This will build a single .jar file, `solr-hive-serde/build/libs/{packageUser}-hive-serde-{connectorVersion}.jar`, which can be used with Hive v3.0. Other Hive versions (such as v2.x) may work with this jar, but have not been tested.
### Troubleshooting Clone Issues
If GitHub and SSH are not configured the following exception will be thrown:
```bash theme={"dark"}
Cloning into 'solr-hadoop-common'...
Permission denied (publickey).
fatal: Could not read from remote repository.
Please make sure you have the correct access rights
and the repository exists.
fatal: clone of 'git@github.com:LucidWorks/solr-hadoop-common.git' into submodule path 'solr-hadoop-common' failed
```
To fix this error, use the [https://help.github.com/articles/generating-an-ssh-key/](https://help.github.com/articles/generating-an-ssh-key/) tutorial.
## Add the SerDe Jar to Hive Classpath
In order for the Hive SerDe to work with Solr, the SerDe jar must be added to Hive's classpath using the `hive.aux.jars.path` capability. There are several options for this, described below.
It's considered a best practice to use a single directory for all auxiliary jars you may want to add to Hive so you only need to define a single path. However, you must then copy any jars you want to use to that path.
The following options all assume you have created such a directory at `/usr/hive/auxlib`; if you use another path, update the path in the examples accordingly.
If you use Hive with Ambari (as with the Hortonworks HDP distribution), go to menu:Hive\[Configs > Advanced], and scroll down to menu:Advanced hive-env\[hive-env template]. Find the section where the `HIVE_AUX_JARS_PATH` is defined, and add the path to each line which starts with `export`. What you want will end up looking like:
```java wrap theme={"dark"}
# Folder containing extra libraries required for hive compilation/execution can be controlled by:
if [ "${HIVE_AUX_JARS_PATH}" != "" ]; then
if [ -f "${HIVE_AUX_JARS_PATH}" ]; then
export HIVE_AUX_JARS_PATH=${HIVE_AUX_JARS_PATH},/usr/hive/auxlib
elif [ -d "/usr/hdp/current/hive-webhcat/share/hcatalog" ]; then
export HIVE_AUX_JARS_PATH=/usr/hdp/current/hive-webhcat/share/hcatalog/hive-hcatalog-core.jar,/usr/hive/auxlib
fi
elif [ -d "/usr/hdp/current/hive-webhcat/share/hcatalog" ]; then
export HIVE_AUX_JARS_PATH=/usr/hdp/current/hive-webhcat/share/hcatalog/hive-hcatalog-core.jar,/usr/hive/auxlib
fi
```
If not using Ambari or similar cluster management tool, you can add the jar location to `hive/conf/hive-site.xml`:
```xml theme={"dark"}
hive.aux.jars.path/usr/hive/auxlib
```
Another option is to launch Hive with the path defined with the `auxpath` variable:
hive --auxpath /usr/hive/auxlib
There are also other approaches that could be used. Keep in mind, though, that the jar *must* be loaded into the classpath, adding it with the `ADD JAR` function is not sufficient.
## Indexing Data with a Hive External Table
Indexing data to Solr or Fusion requires creating a Hive external table. An external table allows the data in the table to be used (read or write) by another system or application outside of Hive.
### Indexing Data to Solr
For integration with Solr, the external table allows you to have Solr read from and write to Hive.
To create an external table for Solr, you can use a command similar to below. The properties available are described after the example.
```bash wrap theme={"dark"}
hive> CREATE EXTERNAL TABLE solr (id string, field1_s string, field2_i int) <1>
STORED BY 'com.lucidworks.hadoop.hive.LWStorageHandler' <2>
LOCATION '/tmp/solr' <3>
TBLPROPERTIES('solr.server.url' = 'http://localhost:8888/solr', <4>
'solr.collection' = 'collection1',
'solr.query' = '*:*');
```
* `<1>` In this example, we have created an external table named "solr", and defined a set of fields and types for the data we will store in the table. See the section `<>` below for best practices when naming fields.
* `<2>` This defines a custom storage handler (`STORED BY 'com.lucidworks.hadoop.hive.LWStorageHandler'`), which is one of the classes included with the Hive SerDe jar.
* `<3>` The LOCATION indicates the location in HDFS where the table data will be stored. In this example, we have chosen to use `/tmp/solr`.
* `<4>` In the section TBLPROPERTIES, we define several parameters for Solr so the data can be indexed to the right Solr installation and collection. See the section `<
>` below for details about these parameters.
If the table needs to be dropped at a later time, you can use the DROP TABLE command in Hive. This will remove the metadata stored in the table in Hive, but will not modify the underlying data (in this case, the Solr index).
#### Defining Fields for Solr
When defining the field names for the Hive table, keep in mind that the field types used to define the table in Hive are *not* sent to Solr when indexing data from a Hive table. The field names are sent, but not the field types. The field types must match or be compatible, however, for queries to complete properly.
The reason why this might be a problem is due to a Solr feature called *schema guessing*. This is Solr's default mode, and when it is enabled Solr looks at incoming data and makes a best guess at the field type.
It can happen that Solr's guess at the correct type may be different from the type defined in Hive, and if this happens you will get a `ClassCastException` in response to queries.
To avoid this problem, you can use a Solr feature called *dynamic fields*. These direct Solr to use specific field types based on a prefix or suffix found on an incoming field name, which overrides Solr guessing at the type. Solr includes by default dynamic field rules for nearly all types it supports, so you only need to use the same suffix on your field names in your Hive tables for the correct type to be defined.
To illustrate this, note the field names in the table example above:
CREATE EXTERNAL TABLE solr (id string, field1\_s string, field2\_i int)
In this example, we have defined the `id` field as a string, `field1_s` as a string, and `field2_i` as an integer. In Solr's default schema, there is a dynamic field rule that any field with a `_s` suffix should be a string. Similarly, there is another rule that any field with `_i` as a suffix should be an integer. This allows us to make sure the field types match.
An alternative to this is to disable Solr's field guessing altogether, but this would require you to create all of your fields in Solr *before* indexing any content from Hive.
For more information about these features and options, please see the following sections of the Apache Solr Reference Guide:
* [https://lucene.apache.org/solr/guide/\{refGuideVersion}/schemaless-mode.html](https://lucene.apache.org/solr/guide/\{refGuideVersion}/schemaless-mode.html)
* [https://lucene.apache.org/solr/guide/\{refGuideVersion}/dynamic-fields.html](https://lucene.apache.org/solr/guide/\{refGuideVersion}/dynamic-fields.html)
* [https://lucene.apache.org/solr/guide/\{refGuideVersion}/field-types-included-with-solr.html](https://lucene.apache.org/solr/guide/\{refGuideVersion}/field-types-included-with-solr.html)
#### Table Properties
The following parameters can be set when defining the table properties:
`solr.zkhost`:
The location of the ZooKeeper quorum if using LucidWorks in SolrCloud mode. If this property is set along with the `solr.server.url` property, the `solr.server.url` property will take precedence.
`solr.server.url`:
The location of the Solr instance if not using LucidWorks in SolrCloud mode. If this property is set along with the `solr.zkhost` property, this property will take precedence.
`solr.collection`:
The Solr collection for this table. If not defined, an exception will be thrown.
`solr.query`:
The specific Solr query to execute to read this table. If not defined, a default of `\*:*` will be used. This property is not needed when loading data to a table, but is needed when defining the table so Hive can later read the table.
`lww.commit.on.close`:
If true, inserts will be automatically committed when the connection is closed. True is the default.
`lww.jaas.file`:
Used only when indexing to or reading from a Solr cluster secured with Kerberos.
This property defines the path to a JAAS file that contains a service principal and keytab location for a user who is authorized to read from and write to Solr and Hive.
The JAAS configuration file *must* be copied to the same path on every node where a Node Manager is running (i.e., every node where map/reduce tasks are executed). Here is a sample section of a JAAS file:
```bash theme={"dark"}
Client { --<1>
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
keyTab="/data/solr-indexer.keytab" --<2>
storeKey=true
useTicketCache=true
debug=true
principal="solr-indexer@SOLRSERVER.COM"; --<3>
};
```
* `<1>` The name of this section of the JAAS file. This name will be used with the `lww.jaas.appname` parameter.
* `<2>` The location of the keytab file.
* `<3>` The service principal name. This should be a different principal than the one used for Solr, but must have access to both Solr and Hive.
`lww.jaas.appname`:
Used only when indexing to or reading from a Solr cluster secured with Kerberos.
This property provides the name of the section in the JAAS file that includes the correct service principal and keytab path.
### Indexing Data to Fusion
If you use Lucidworks Fusion, you can index data from Hive to Solr via Fusion's index pipelines. These pipelines allow you several options for further transforming your data.
If you are using Fusion v3.0.x, you already have the Hive SerDe in Fusion's `./apps/connectors/resources/lucid.hadoop/jobs` directory. The SerDe jar that supports Fusion is v2.2.4 or higher. This was released with Fusion 3.0.
If you are using Fusion 3.1.x and higher, you will need to download the Hive SerDe from [http://lucidworks.com/connectors/](http://lucidworks.com/connectors/). Choose the proper Hadoop distribution and the resulting .zip file will include the Hive SerDe.
A 2.2.4 or higher jar built from this repository will also work with Fusion 2.4.x releases.
This is an example Hive command to create an external table to index documents in Fusion and to query the table later.
```bash wrap theme={"dark"}
hive> CREATE EXTERNAL TABLE fusion (id string, field1_s string, field2_i int)
STORED BY 'com.lucidworks.hadoop.hive.FusionStorageHandler'
LOCATION '/tmp/fusion'
TBLPROPERTIES('fusion.endpoints' = 'http://localhost:8764/api/apollo/index-pipelines//collections//index',
'fusion.fail.on.error' = 'false',
'fusion.buffer.timeoutms' = '1000',
'fusion.batchSize' = '500',
'fusion.realm' = 'KERBEROS',
'fusion.user' = 'fusion-indexer@FUSIONSERVER.COM',
'java.security.auth.login.config' = '/path/to/JAAS/file',
'fusion.jaas.appname' = 'FusionClient',
'fusion.query.endpoints' = 'http://localhost:8764/api/apollo/query-pipelines/pipeline-id/collections/collection-id',
'fusion.query' = '*:*');
```
In this example, we have created an external table named "fusion", and defined a custom storage handler (`STORED BY 'com.lucidworks.hadoop.hive.FusionStorageHandler'`) that a class included with the Hive SerDe jar designed for use with Fusion.
Note that all of the same caveats about field types discussed in the section `<>` apply to Fusion as well. In Fusion, however, you have the option of using an index pipeline to perform specific field mapping instead of using dynamic fields.
The LOCATION indicates the location in HDFS where the table data will be stored. In this example, we have chosen to use `/tmp/fusion`.
In the section TBLPROPERTIES, we define several properties for Fusion so the data can be indexed to the right Fusion installation and collection:
`fusion.endpoints`:
The full URL to the index pipeline in Fusion. The URL should include the pipeline name and the collection data will be indexed to.
`fusion.fail.on.error`:
If `true`, when an error is encountered, such as if a row could not be parsed, indexing will stop. This is `false` by default.
`fusion.buffer.timeoutms`:
The amount of time, in milliseconds, to buffer documents before sending them to Fusion. The default is 1000. Documents will be sent to Fusion when either this value or `fusion.batchSize` is met.
`fusion.batchSize`:
The number of documents to batch before sending the batch to Fusion. The default is 500. Documents will be sent to Fusion when either this value or `fusion.buffer.timeoutms` is met.
`fusion.realm`:
This is used with `fusion.user` and `fusion.password` to authenticate to Fusion for indexing data. Two options are supported, `KERBEROS` or `NATIVE`.
Kerberos authentication is supported with the additional definition of a JAAS file. The properties `java.security.auth.login.config` and `fusion.jaas.appname` are used to define the location of the JAAS file and the section of the file to use.
Native authentication uses a Fusion-defined username and password. This user must exist in Fusion, and have the proper permissions to index documents.
`fusion.user`:
The Fusion username or Kerberos principal to use for authentication to Fusion. If a Fusion username is used (`'fusion.realm' = 'NATIVE'`), the `fusion.password` must also be supplied.
`fusion.password`:
This property is not shown in the example above. The password for the `fusion.user` when the `fusion.realm` is `NATIVE`.
`java.security.auth.login.config`:
This property defines the path to a JAAS file that contains a service principal and keytab location for a user who is authorized to read from and write to Fusion and Hive.
The JAAS configuration file *must* be copied to the same path on every node where a Node Manager is running (i.e., every node where map/reduce tasks are executed). Here is a sample section of a JAAS file:
```bash theme={"dark"}
Client { --<1>
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
keyTab="/data/fusion-indexer.keytab" --<2>
storeKey=true
useTicketCache=true
debug=true
principal="fusion-indexer@FUSIONSERVER.COM"; --<3>
};
```
* `<1>` The name of this section of the JAAS file. This name will be used with the `fusion.jaas.appname` parameter.
* `<2>` The location of the keytab file.
* `<3>` The service principal name. This should be a different principal than the one used for Fusion, but must have access to both Fusion and Hive. This name is used with the `fusion.user` parameter described above.
`fusion.jaas.appname`:
Used only when indexing to or reading from Fusion when it is secured with Kerberos.
This property provides the name of the section in the JAAS file that includes the correct service principal and keytab path.
`fusion.query.endpoints`:
The full URL to a query pipeline in Fusion. The URL should include the pipeline name and the collection data will be read from. You should also specify the request handler to be used.
If you do not intend to query your Fusion data from Hive, you can skip this parameter.
`fusion.query`:
The query to run in Fusion to select records to be read into Hive. This is `\*:*` by default, which selects all records in the index.
If you do not intend to query your Fusion data from Hive, you can skip this parameter.
## Query and Insert Data to Hive
Once the table is configured, any syntactically correct Hive query will be able to query the index.
For example, to select three fields named "id", "field1\_s", and "field2\_i" from the "solr" table, you would use a query such as:
```bash theme={"dark"}
hive> SELECT id, field1_s, field2_i FROM solr;
```
Replace the table name as appropriate to use this example with your data.
To join data from tables, you can make a request such as:
```bash theme={"dark"}
hive> SELECT id, field1_s, field2_i FROM solr left
JOIN sometable right
WHERE left.id = right.id;
```
And finally, to insert data to a table, simply use the Solr table as the target for the Hive INSERT statement, such as:
```bash theme={"dark"}
hive> INSERT INTO solr
SELECT id, field1_s, field2_i FROM sometable;
```
## Example Indexing Hive to Solr
Solr includes a small number of sample documents for use when getting started. One of these is a CSV file containing book metadata. This file is found in your Solr installation, at `$SOLR_HOME/example/exampledocs/books.csv`.
Using the sample `books.csv` file, we can see a detailed example of creating a table, loading data to it, and indexing that data to Solr.
```bash wrap theme={"dark"}
CREATE TABLE books (id STRING, cat STRING, title STRING, price FLOAT, in_stock BOOLEAN, author STRING, series STRING, seq INT, genre STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ','; --<1>
LOAD DATA LOCAL INPATH '/solr/example/exampledocs/books.csv' OVERWRITE INTO TABLE books; --<2>
CREATE EXTERNAL TABLE solr (id STRING, cat_s STRING, title_s STRING, price_f FLOAT, in_stock_b BOOLEAN, author_s STRING, series_s STRING, seq_i INT, genre_s STRING) --<3>
STORED BY 'com.lucidworks.hadoop.hive.LWStorageHandler' --<4>
LOCATION '/tmp/solr' --<5>
TBLPROPERTIES('solr.zkhost' = 'zknode1:2181,zknode2:2181,zknode3:2181/solr',
'solr.collection' = 'gettingstarted',
'solr.query' = '*:*', --<6>
'lww.jaas.file' = '/data/jaas-client.conf'); --<7>
INSERT OVERWRITE TABLE solr SELECT b.* FROM books b;
```
* `<1>` Define the table `books`, and provide the field names and field types that will make up the table.
* `<2>` Load the data from the `books.csv` file.
* `<3>` Create an external table named `solr`, and provide the field names and field types that will make up the table. These will be the same field names as in your local Hive table, so we can index all of the same data to Solr.
* `<4>` Define the custom storage handler provided by the `{packageUser}-hive-serde-{connectorVersion}.jar`.
* `<5>` Define storage location in HDFS.
* `<6>` The query to run in Solr to read records from Solr for use in Hive.
* `<7>` Define the location of Solr (or ZooKeeper if using SolrCloud), the collection in Solr to index the data to, and the query to use when reading the table. This example also refers to a JAAS configuration file that will be used to authenticate to the Kerberized Solr cluster.
You can use Pig to import data into Fusion, using the `lucidworks-pig-functions-v2.2.6.jar` file found in `$FUSION_HOME/apps/connectors/resources/lucid.hadoop/jobs`.
## Features
* Functions to allow Pig scripts to index data to Solr or Fusion.
* Supports Kerberos for authentication.
* As of v2.2.4, integration with [http://lucidworks.com/products](http://lucidworks.com/products) is supported, allowing use of Fusion pipelines for further data transformation prior to indexing.
Supported versions are:
* Solr 5.x and higher
* Pig versions 0.12 through 0.16
* Hadoop 3.x
* Fusion 2.4.x and higher
## Build the Functions Jar
You must use Java 8 or higher to build the .jar.
This project has a dependency on the `solr-hadoop-common` submodule (contained in a separate GitHub repository, [https://github.com/lucidworks/solr-hadoop-common](https://github.com/lucidworks/solr-hadoop-common)). This submodule must be initialized before building the Functions jar.
To initialize the submodule, pull this repo, then:
```bash theme={"dark"}
git submodule init
```
Once the submodule has been initialized, the command `git submodule update` will fetch all the data from that project and check out the appropriate commit listed in the superproject. You must initialize and update the submodule before attempting to build the Functions jar.
* If a build is happening from a branch, please make sure that `solr-hadoop-common` is pointing to the correct SHA.
(See [https://github.com/blog/2104-working-with-submodules](https://github.com/blog/2104-working-with-submodules) for more details.)
```
pig-solr $ git checkout
pig-solr $ cd solr-hadoop-common
pig-solr/solr-hadoop-common $ git checkout
pig-solr/solr-hadoop-common $ cd ..
```
The build uses Gradle. However, you do not need Gradle installed before attempting to build.
To build the .jar file, run this command:
`./gradlew clean shadowJar --info`
This will make a .jar file:
solr-pig-functions/build/libs/{packageUser}-pig-functions-{connectorVersion}.jar
The .jar is required to use the Pig functions.
### Troubleshooting Clone Issues
If GitHub + SSH is not configured the following exception will be thrown:
```bash theme={"dark"}
Cloning into 'solr-hadoop-common'...
Permission denied (publickey).
fatal: Could not read from remote repository.
Please make sure you have the correct access rights
and the repository exists.
fatal: clone of 'git@github.com:LucidWorks/solr-hadoop-common.git' into submodule path 'solr-hadoop-common' failed
```
To fix this error, use the [https://help.github.com/articles/generating-an-ssh-key/](https://help.github.com/articles/generating-an-ssh-key/) tutorial.
## Available Functions
The Pig functions included in the `{packageUser}-pig-functions-{connectorVersion}.jar` are three UserDefined Functions (UDF) and two Store functions. These functions are:
* `com/lucidworks/hadoop/pig/SolrStoreFunc.class`
* `com/lucidworks/hadoop/pig/FusionIndexPipelinesStoreFunc.class`
* `com/lucidworks/hadoop/pig/EpochToCalendar.class`
* `com/lucidworks/hadoop/pig/Extract.class`
* `com/lucidworks/hadoop/pig/Histogram.class`
## Using the Functions
### Register the Functions
There are two approaches to using functions in Pig: `REGISTER` them in the script, or load them with your Pig command line request.
If using `REGISTER`, the Pig function jars must be put in HDFS in order to be used by your Pig script. It can be located anywhere in HDFS; you can either supply the path in your script or use a variable and define the variable with `-p` property definition.
The example below uses the second approach, loading the jars with the `-Dpig.additional.jars` system property when launching the script. With this approach, the jars can be located anywhere on the machine where the script will be run.
### Indexing Data to Solr
There are a few required parameters for your script to output data to Solr for indexing.
These parameters can be defined in the script itself, or turned into variables that are defined each time the script runs. The example Pig script below shows an example of using these parameters with variables.
`solr.zkhost`:
The ZooKeeper connection string if using Solr in SolrCloud mode. This should be in the form of `server:port,server:port,server:port/chroot`.
If you are not using SolrCloud, use the `solr.server.url` parameter instead.
`solr.server.url`:
The location of the Solr instance when Solr is running in standalone mode. This should be in the form of `\http://server:port/solr`.
`solr.collection`:
The name of the Solr collection where documents will be indexed.
#### Indexing to a Kerberos-Secured Solr Cluster
When a Solr cluster is secured with Kerberos for internode communication, Pig scripts must include the full path to a JAAS file that includes the service principal and the path to a keytab file that will be used to index the output of the script to Solr.
Two parameters provide the information the script needs to access the JAAS file:
`lww.jaas.file`:
The path to the JAAS file that includes a section for the service principal who will write to the Solr indexes. For example, to use this property in a Pig script:
set lww\.jaas.file '/path/to/login.conf';
The JAAS configuration file *must* be copied to the same path on every node where a Node Manager is running (i.e., every node where map/reduce tasks are executed).
`lww.jaas.appname`:
The name of the section in the JAAS file that includes the correct service principal and keytab path. For example, to use this property in a Pig script:
set lww\.jaas.appname 'Client';
Here is a sample section of a JAAS file:
```bash theme={"dark"}
Client { --<1>
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
keyTab="/data/solr-indexer.keytab" --<2>
storeKey=true
useTicketCache=true
debug=true
principal="solr-indexer@SOLRSERVER.COM"; --<3>
};
```
* `<1>` The name of this section of the JAAS file. This name will be used with the `lww.jaas.appname` parameter.
* `<2>` The location of the keytab file.
* `<3>` The service principal name. This should be a different principal than the one used for Solr, but must have access to both Solr and Pig.
#### Indexing to a SSL-Enabled Solr Cluster
When SSL is enabled in a Solr cluster, Pig scripts must include the full paths to the `keystore` and `truststore` with their respective passwords.
set lww\.keystore '/path/to/solr-ssl.keystore.jks'
set lww\.keystore.password 'secret'
set lww\.truststore '/path/to/solr-ssl.truststore.jks'
set lww\.truststore.password 'secret'
The paths (and secret configurations) should be the same in all YARN/MapReduce hosts.
### Indexing Data to Fusion
When indexing data to Fusion, there are several parameters to pass with your script in order to output data to Fusion for indexing.
These parameters can be made into variables in the script, with the proper values passed on the command line when the script is initiated. The example script below shows how to do this for Solr. The theory is the same for Fusion, only the parameter names would change as appropriate:
`fusion.endpoints`:
The full URL to the index pipeline in Fusion. The URL should include the pipeline name and the collection data will be indexed to.
`fusion.fail.on.error`:
If `true`, when an error is encountered, such as if a row could not be parsed, indexing will stop. This is `false` by default.
`fusion.buffer.timeoutms`:
The amount of time, in milliseconds, to buffer documents before sending them to Fusion. The default is 1000. Documents will be sent to Fusion when either this value or `fusion.batchSize` is met.
`fusion.batchSize`:
The number of documents to batch before sending the batch to Fusion. The default is 500. Documents will be sent to Fusion when either this value or `fusion.buffer.timeoutms` is met.
`fusion.realm`:
This is used with `fusion.user` and `fusion.password` to authenticate to Fusion for indexing data. Two options are supported, `KERBEROS` or `NATIVE`.
Kerberos authentication is supported with the additional definition of a JAAS file. The properties `java.security.auth.login.config` and `fusion.jaas.appname` are used to define the location of the JAAS file and the section of the file to use. These are described in more detail below.
Native authentication uses a Fusion-defined username and password. This user must exist in Fusion, and have the proper permissions to index documents.
`fusion.user`:
The Fusion username or Kerberos principal to use for authentication to Fusion.
If a Fusion username is used (`'fusion.realm' = 'NATIVE'`), the `fusion.password` must also be supplied.
`fusion.pass`:
This property is not shown in the example above. The password for the `fusion.user` when the `fusion.realm` is `NATIVE`.
#### Indexing to a Kerberized Fusion Installation
When Fusion is secured with Kerberos, Pig scripts must include the full path to a JAAS file that includes the service principal and the path to a keytab file that will be used to index the output of the script to Fusion.
Additionally, a Kerberos ticket must be obtained on the server for the principal using `kinit`.
`java.security.auth.login.config`:
This property defines the path to a JAAS file that contains a service principal and keytab location for a user who is authorized to write to Fusion.
The JAAS configuration file *must* be copied to the same path on every node where a Node Manager is running (i.e., every node where map/reduce tasks are executed). Here is a sample section of a JAAS file:
```bash theme={"dark"}
Client { --<1>
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
keyTab="/data/fusion-indexer.keytab" --<2>
storeKey=true
useTicketCache=true
debug=true
principal="fusion-indexer@FUSIONSERVER.COM"; --<3>
};
```
* `<1>` The name of this section of the JAAS file. This name will be used with the `fusion.jaas.appname` parameter.
* `<2>` The location of the keytab file.
* `<3>` The service principal name. This should be a different principal than the one used for Fusion, but must have access to both Fusion and Pig. This name is used with the `fusion.user` parameter described above.
`fusion.jaas.appname`:
Used only when indexing to or reading from Fusion when it is secured with Kerberos.
This property provides the name of the section in the JAAS file that includes the correct service principal and keytab path.
### Sample CSV Script
The following Pig script will take a simple CSV file and index it to Solr.
```bash theme={"dark"}
set solr.zkhost '$zkHost';
set solr.collection '$collection'; -- <1>
A = load '$csv' using PigStorage(',') as (id_s:chararray,city_s:chararray,country_s:chararray,code_s:chararray,code2_s:chararray,latitude_s:chararray,longitude_s:chararray,flag_s:chararray); -- <2>
--dump A;
B = FOREACH A GENERATE $0 as id, 'city_s', $1, 'country_s', $2, 'code_s', $3, 'code2_s', $4, 'latitude_s', $5, 'longitude_s', $6, 'flag_s', $7; -- <3>
ok = store B into 'SOLR' using com.lucidworks.hadoop.pig.SolrStoreFunc(); -- <4>
```
This relatively simple script is doing several things that help to understand how the Solr Pig functions work.
* `<1>` This and the line above define parameters that are needed by `SolrStoreFunc` to know where Solr is. `SolrStoreFunc` needs the properties `solr.zkhost` and `solr.collection`, and these lines are mapping the `zkhost` and `collection` parameters we will pass when invoking Pig to the required properties.
* `<2>` Load the CSV file, the path and name we will pass with the `csv` parameter. We also define the field names for each column in CSV file, and their types.
* `<3>` For each item in the CSV file, generate a document id from the first field (`$0`) and then define each field name and value in `name, value` pairs.
* `<4>` Load the documents into Solr, using the `SolrStoreFunc`. While we don't need to define the location of Solr here, the function will use the `zkhost` and `collection` properties that we will pass when we invoke our Pig script.
When using `SolrStoreFunc`, the document ID *must* be the first field.
When we want to run this script, we invoke Pig and define several parameters we have referenced in the script with the `-p` option, such as in this command:
```bash wrap theme={"dark"}
./bin/pig -Dpig.additional.jars=/path/to/{packageUser}-pig-functions-{connectorVersion}.jar -p csv=/path/to/my/csv/airports.dat -p zkHost=zknode1:2181,zknode2:2181,zknode3:2181/solr -p collection=myCollection ~/myScripts/index-csv.pig
```
The parameters to pass are:
`csv`:
The path and name of the CSV file we want to process.
`zkhost`:
The ZooKeeper connection string for a SolrCloud cluster, in the form of `zkhost1:port,zkhost2:port,zkhost3:port/chroot`. In the script, we mapped this to the `solr.zkhost` property, which is required by the `SolrStoreFunc` to know where to send the output documents.
`collection`:
The Solr collection to index into. In the script, we mapped this to the `solr.collection` property, which is required by the `SolrStoreFunc` to know the Solr collection the documents should be indexed to.
The `zkhost` parameter above is only used if you are indexing to a SolrCloud cluster, which uses ZooKeeper to route indexing and query requests.
If, however, you are not using SolrCloud, you can use the `solrUrl` parameter, which takes the location of a standalone Solr instance, in the form of `\http://host:port/solr`.
In the script, you would change the line that maps `solr.zkhost` to the `zkhost` property to map `solr.server.url` to the `solrUrl` property. For example:
`set solr.server.url '$solrUrl';`
It is often possible to get documents into Fusion Server by configuring a datasource with the appropriate connector.
* [Fusion 4.x Connectors](/docs/4/fusion-server/concepts/indexing/connectors/overview)
* [Fusion 5.x Connectors](/docs/5/fusion/getting-data-in/indexing/connectors)
But if there are obstacles to using connectors, it can be simpler to index documents with a REST API call to an index profile or pipeline.
## Push documents to Fusion using index profiles
Index profiles allow you to send documents to a consistent endpoint (the profile alias) and change the backend index pipeline as needed. The profile is also a simple way to use one pipeline for multiple collections without any one collection "owning" the pipeline.
* [Fusion 4.x Index Profiles](/docs/4/fusion-server/concepts/indexing/datasources/index-profiles)
* [Fusion 5.x Index Profiles](/docs/5/fusion/getting-data-in/indexing/index-pipelines/index-profiles)
### Send data to an index profile that is part of an app
Accessing an index profile through an app lets a Fusion admin secure and manage all objects on a per-app basis. Security is then determined by whether a user can access an app. This is the recommended way to manage permissions in Fusion.
The syntax for sending documents to an index profile that is part of an app is as follows:
```bash wrap theme={"dark"}
curl -u USERNAME:PASSWORD -X POST -H 'content-type: application/json' https://FUSION_HOST:FUSION_PORT/api/apps/APP_NAME/index/INDEX_PROFILE --data-binary @my-json-data.json
```
Spaces in an app name become underscores. Spaces in an index profile name become hyphens.
To prevent the terminal from displaying all the data and metadata it indexes--useful if you are indexing a large file--you can optionally append `?echo=false` to the URL.
Be sure to set the content type header properly for the content being sent. Some frequently used content types are:
* Text: `application/json`, `application/xml`
* PDF documents: `application/pdf`
* MS Office:
* DOCX: `application/vnd.openxmlformats-officedocument.wordprocessingml.document`
* XLSX: `application/vnd.openxmlformats-officedocument.spreadsheetml.sheet`
* PPTX: `application/vnd.vnd.openxmlformats-officedocument.presentationml.presentation`
* More types: [http://filext.com/faq/office\_mime\_types.php](http://filext.com/faq/office_mime_types.php)
### Example: Send JSON data to an index profile under an app
In `$FUSION_HOME/apps/solr-dist/example/exampledocs` you can find a few sample documents. This example uses one of these, `books.json`.
To push JSON data to an index profile under an app:
1. Create an index profile. In the Fusion UI, click **Indexing > Index Profiles** and follow the prompts.
2. From the directory containing `books.json`, enter the following, substituting your values for username, password, and index profile name:
```bash wrap theme={"dark"}
curl -u USERNAME:PASSWORD -X POST -H 'content-type: application/json' https://FUSION_HOST:FUSION_PORT/api/apps/APP_NAME/index/INDEX_PROFILE?echo=false --data-binary @books.json
```
3. Test that your data has made it into Fusion:
1. Log into the Fusion UI.
2. Navigate to the app where you sent your data.
3. Navigate to the Query Workbench.
4. Search for `\*:*`.
5. Select relevant Display Fields, for example `author` and `name`.
### Example: Send JSON data without defining an app
In most cases it is best to delegate permissions on a per-app basis. But if your use case requires it, you can push data to Fusion without defining an app.
To send JSON data without app security, issue the following curl command:
```bash wrap theme={"dark"}
curl -u USERNAME:PASSWORD -X POST -H 'content-type: application/json' https://FUSION_HOST:FUSION_PORT/api/index/INDEX_PROFILE --data-binary @my-json-data.json
```
### Example: Send XML data to an index profile with an app
To send XML data to an app, use the following:
```bash wrap theme={"dark"}
curl -u USERNAME:PASSWORD -X POST -H 'content-type: application/xml' https://FUSION_HOST:FUSION_PORT/api/apps/APP_NAME/index/INDEX_PROFILE --data-binary @my-xml-file.xml
```
In Fusion 5, documents can be created on the fly using the [PipelineDocument](https://javadoc.lucidworks.com/fusion-pipeline-javadocs/5.3/com/lucidworks/apollo/common/pipeline/PipelineDocument.html) JSON notation.
## Remove documents
### Example 1
The following example removes content:
```bash wrap theme={"dark"}
curl -u USERNAME:PASSWORD -X POST -H 'content-type: application/vnd.lucidworks-document' https://FUSION_HOST:FUSION_PORT/api/apps/APP_NAME/index/INDEX_PROFILE --data-binary @del-json-data.json
```
### Example 2
A more specific example removes data from `books.json`. To delete "The Lightning Thief" and "The Sea of Monsters" from the index, use their id values in the JSON file.
The `del-json-data.json` file to delete the two books:
```json wrap theme={"dark"}
[{ "id": "978-0641723445","commands": [{"name": "delete","params": {}}]},{ "id": "978-1423103349","commands": [{"name": "delete","params": {}}, {"name": "commit","params": {}}]}]
```
The `?echo=false` can be used to turn off the response to the terminal.
### Example 3
Another example to delete items using the Push API is:
```bash wrap theme={"dark"}
curl -u admin:XXX -X POST 'http://FUSION_HOST:FUSION_PORT/api/apps/APP/index/INDEX' -H 'Content-Type: application/vnd.lucidworks-document' -d '[
{
"id": "1663838589-44",
"commands":
[
{
"name": "delete",
"params":
{}
},
{
"name": "commit",
"params":
{}
}
]
}, ...
]'
```
## Send documents to an index pipeline
Although sending documents to an index profile is recommended, if your use case requires it, you can send documents directly to an index pipeline.
For more information about index pipeline REST API reference documentation, select the link for your Fusion release:
* [Fusion 4.x Index Pipelines API](/docs/4/fusion-server/reference/api/indexing/index-pipelines-api)
* [Fusion 5.x Index Pipelines API](/api-reference/index-pipelines-api/get-the-service-status)
### Specify a parser
When you push data to a pipeline, you can specify the name of the parser by adding a parserId querystring parameter to the URL.
For example: `https://FUSION_HOST:FUSION_PORT/api/index-pipelines/INDEX_PIPELINE/collections/COLLECTION_NAME/index?parserId=PARSER`.
If you do not specify a parser, and you are indexing outside of an app (`https://FUSION_HOST:FUSION_PORT/api/index-pipelines/...`), then the `_system` parser is used.
If you do not specify a parser, and you are indexing in an app context (`https://FUSION_HOST:FUSION_PORT/api/apps/APP_NAME/index-pipelines/...`), then the parser with the same name as the app is used.
## Indexing CSV Files
In the usual case, to index a CSV or TSV file, the file is split into records, one per row, and each row is indexed as a separate document.
**Import Signals** is also available with a [Fusion AI license](/docs/4/fusion-ai/reference/licensing).
Normally, signals are indexed as streaming data during the natural activity of users. This topic describes how to load historical signals data in batches, in Parquet format, using Spark shell.
Fusion’s performance may be affected during this resource-intensive operation. Be sure to allocate sufficient memory for the Spark, Solr, and connectors services.
1. Customize the code below by replacing the following strings:
* `path_of_folder`. The absolute path to the folder containing your Parquet files.
* `collection_name_signals`. The name of the signals collection where you want to load these signals.
* `localhost:9983/lwfusion/4.2.2/solr` - You can verify the correct path by going to the Solr console at `http://fusion_host:8983/solr/#/` and looking for the value of `DzkHost`.
```
val parquetFilePath = "path_of_folder"
val signals = spark.read.parquet(parquetFilePath)
val collectionName = "collection_name_signals"
val zkhostName = "localhost:9983/lwfusion/4.2.1/solr"
var connectionMap = Map("collection" -> collectionName, "zkhost" -> zkhostName, "commit_within" -> "5000", "batch_size" -> "10000")
signals.write.format("solr").options(connectionMap).save()
```
For information about `commit_within` and `batch_size`, see [https://github.com/lucidworks/spark-solr#commit\_within](https://github.com/lucidworks/spark-solr#commit_within).
2. Launch the Spark shell:
```bash theme={"dark"}
https://FUSION_HOST:FUSION_PORT/bin/spark-shell
```
3. At the `scala>` prompt, enter paste mode:
```scala theme={"dark"}
:paste
```
4. Paste your modified code from step 1.
5. Exit paste mode by pressing `CTRL-d`.
6. When the operation is finished, navigate to **Collections** > **Collections Manager** to verify that the number of documents in the specified signals collection has increased as expected.
## Indexing
*Indexing* converts your data into an indexed collection in Fusion’s Solr core. It is critical for ensuring that your data is stored in a format that is ideal for your search application.
* [Index pipelines](/docs/4/fusion-server/concepts/indexing/datasources/index-pipelines) determine the details of the conversion.
* [Index pipeline stages](/docs/4/fusion-server/concepts/indexing/datasources/index-pipeline-stages) are the building blocks of index pipelines.
* The [Index Workbench](/docs/4/fusion-server/concepts/indexing/datasources/index-workbench) is Fusion’s index pipeline development tool.
 This lets you use Spark ML models to make predictions in a more scalable, performant manner than what can be achieved with a Machine Learning index stage. |
Function for `transformScala`:
```scala theme={"dark"}
def transform(inputDF: Dataset[Row]) : Dataset[Row] = {
{/* // do transformations and/or filter the inputDF here */}
}
Your script can rely on the following vals:
spark: SparkSession
sc: SparkContext
fusionZKConn: ZKConnection // needed to access Fusion API
solrCollection: SolrCollection // output collection
jobId: Loader job config ID
Also, the following classes have already been imported:
import org.apache.spark.SparkContext._
import spark.implicits._
import spark.sql
import org.apache.spark.sql.functions._
import com.lucidworks.spark.util.{SparkShellSupport => _lw}
import com.lucidworks.spark.job.sql.SparkSQLLoader
import com.lucidworks.spark.ml.recommenders.SolrCollection
import com.lucidworks.spark.ZKConnection
import org.apache.spark.sql.{Dataset, Row}
```
### Output settings
| Setting | Description |
| ------------------------------ | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `outputCollection` | Name of the Fusion collection to write to. The Parallel Bulk Loader uses the Collections API to resolve the underlying Solr collection at runtime. |
| `outputIndexPipeline` | Name of a Fusion index pipeline to which to send documents, instead of directly indexing to Solr. This option lets you perform additional ETL (extract, transform, and load) processing on the documents before they are indexed in Solr. If you need to write to time-partitioned indexes, then you must use an index pipeline, because writing directly to Solr is not partition aware. |
| `defineFieldsUsingInputSchema` | Flag to indicate if the Parallel Bulk Loader should use the input schema to create fields in Solr, after applying the Scala and/or SQL transformations. If `false`, then the Parallel Bulk Loader relies on the Fusion index pipeline and/or Solr field guessing to create the fields. If `true`, only fields that do not exist already in Solr are created. Consequently, if there is a type mismatch between an existing field in Solr and the input schema, you will need to use a transformation to rename the field in the input schema. |
| `clearDatasource` | If checked, the Parallel Bulk Loader deletes any existing documents in the output collection that match the query `_lw_loader_id_s:
This lets you use Spark ML models to make predictions in a more scalable, performant manner than what can be achieved with a Machine Learning index stage. |
Function for `transformScala`:
```scala theme={"dark"}
def transform(inputDF: Dataset[Row]) : Dataset[Row] = {
{/* // do transformations and/or filter the inputDF here */}
}
Your script can rely on the following vals:
spark: SparkSession
sc: SparkContext
fusionZKConn: ZKConnection // needed to access Fusion API
solrCollection: SolrCollection // output collection
jobId: Loader job config ID
Also, the following classes have already been imported:
import org.apache.spark.SparkContext._
import spark.implicits._
import spark.sql
import org.apache.spark.sql.functions._
import com.lucidworks.spark.util.{SparkShellSupport => _lw}
import com.lucidworks.spark.job.sql.SparkSQLLoader
import com.lucidworks.spark.ml.recommenders.SolrCollection
import com.lucidworks.spark.ZKConnection
import org.apache.spark.sql.{Dataset, Row}
```
### Output settings
| Setting | Description |
| ------------------------------ | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `outputCollection` | Name of the Fusion collection to write to. The Parallel Bulk Loader uses the Collections API to resolve the underlying Solr collection at runtime. |
| `outputIndexPipeline` | Name of a Fusion index pipeline to which to send documents, instead of directly indexing to Solr. This option lets you perform additional ETL (extract, transform, and load) processing on the documents before they are indexed in Solr. If you need to write to time-partitioned indexes, then you must use an index pipeline, because writing directly to Solr is not partition aware. |
| `defineFieldsUsingInputSchema` | Flag to indicate if the Parallel Bulk Loader should use the input schema to create fields in Solr, after applying the Scala and/or SQL transformations. If `false`, then the Parallel Bulk Loader relies on the Fusion index pipeline and/or Solr field guessing to create the fields. If `true`, only fields that do not exist already in Solr are created. Consequently, if there is a type mismatch between an existing field in Solr and the input schema, you will need to use a transformation to rename the field in the input schema. |
| `clearDatasource` | If checked, the Parallel Bulk Loader deletes any existing documents in the output collection that match the query `_lw_loader_id_s: |
| `outputPartitions` | Coalesce the DataFrame into N partitions before writing to Solr. This can help spread the indexing work out across more executors that are available in Spark, or limit the parallelism when writing to Solr. |
## Tune performance
As the name of the Parallel Bulk Loader job implies, it is designed to ingest large amounts of data into Fusion by parallelizing the work across your Spark cluster. To achieve scalability, you might need to increase the amount of memory and/or CPU resources allocated to the job.
By default, Fusion’s Spark configuration settings control the resources allocated to Parallel Bulk Loader jobs.
You can pass these properties in the job configuration to override the default Spark shell options:
| Parameter Name | Description and Default |
| ------------------------ | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `--driver-cores` | Cores for the driver Default: `1` |
| `--driver-memory` | Memory for the driver (for example, `1000M` or `2G`) Default: `1024M` |
| `--executor-cores` | Cores per executor Default: 1 in YARN mode, or all available cores on the worker in standalone mode |
| `--executor-memory` | Memory per executor (for example, `1000M` or `2G`) Default: `1G` |
| `--total-executor-cores` | Total cores for all executors Default: Without setting this parameter, the total cores for all executors is the number of executors in YARN mode, or all available cores on all workers in standalone mode. |
|
| `outputPartitions` | Coalesce the DataFrame into N partitions before writing to Solr. This can help spread the indexing work out across more executors that are available in Spark, or limit the parallelism when writing to Solr. |
## Tune performance
As the name of the Parallel Bulk Loader job implies, it is designed to ingest large amounts of data into Fusion by parallelizing the work across your Spark cluster. To achieve scalability, you might need to increase the amount of memory and/or CPU resources allocated to the job.
By default, Fusion’s Spark configuration settings control the resources allocated to Parallel Bulk Loader jobs.
You can pass these properties in the job configuration to override the default Spark shell options:
| Parameter Name | Description and Default |
| ------------------------ | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `--driver-cores` | Cores for the driver Default: `1` |
| `--driver-memory` | Memory for the driver (for example, `1000M` or `2G`) Default: `1024M` |
| `--executor-cores` | Cores per executor Default: 1 in YARN mode, or all available cores on the worker in standalone mode |
| `--executor-memory` | Memory per executor (for example, `1000M` or `2G`) Default: `1G` |
| `--total-executor-cores` | Total cores for all executors Default: Without setting this parameter, the total cores for all executors is the number of executors in YARN mode, or all available cores on all workers in standalone mode. |
 ## Examples
Here we provide screenshots and example JSON job definitions to illustrate key points about how to load from different data sources.
### Use NLP during indexing
In this example, we leverage the John Snow labs NLP library during indexing. This is just quick-and-dirty to show the concept.
Also see:
* [https://github.com/JohnSnowLabs/spark-nlp](https://github.com/JohnSnowLabs/spark-nlp)
* [https://databricks.com/blog/2017/10/19/introducing-natural-language-processing-library-apache-spark.html](https://databricks.com/blog/2017/10/19/introducing-natural-language-processing-library-apache-spark.html)
## Examples
Here we provide screenshots and example JSON job definitions to illustrate key points about how to load from different data sources.
### Use NLP during indexing
In this example, we leverage the John Snow labs NLP library during indexing. This is just quick-and-dirty to show the concept.
Also see:
* [https://github.com/JohnSnowLabs/spark-nlp](https://github.com/JohnSnowLabs/spark-nlp)
* [https://databricks.com/blog/2017/10/19/introducing-natural-language-processing-library-apache-spark.html](https://databricks.com/blog/2017/10/19/introducing-natural-language-processing-library-apache-spark.html)
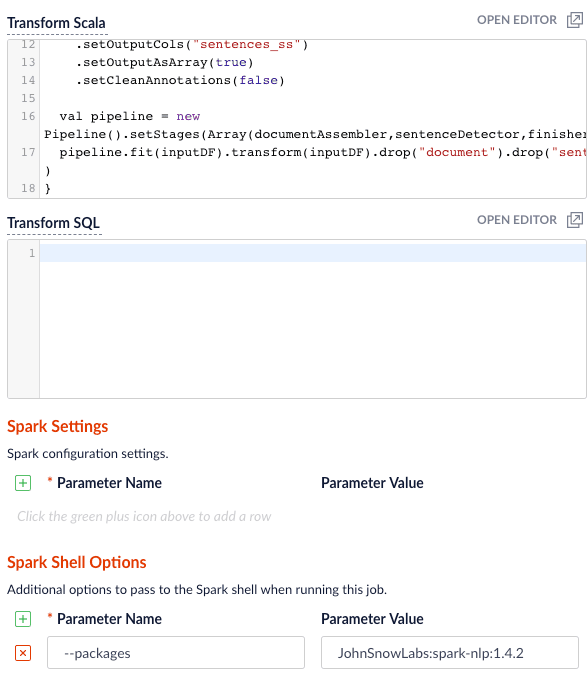 Use this transform Scala script:
```scala theme={"dark"}
import com.johnsnowlabs.nlp._
import com.johnsnowlabs.nlp.annotators._
import org.apache.spark.ml.Pipeline
import com.johnsnowlabs.nlp.annotators.sbd.pragmatic.SentenceDetector
def transform(inputDF: Dataset[Row]) : Dataset[Row] = {
val documentAssembler = new DocumentAssembler().setInputCol("plot_txt_en").setOutputCol("document")
val sentenceDetector = new SentenceDetector().setInputCols(Array("document")).setOutputCol("sentences")
val finisher = new Finisher()
.setInputCols("sentences")
.setOutputCols("sentences_ss")
.setOutputAsArray(true)
.setCleanAnnotations(false)
val pipeline = new Pipeline().setStages(Array(documentAssembler,sentenceDetector,finisher))
pipeline.fit(inputDF).transform(inputDF).drop("document").drop("sentences")
}
```
Be sure to add the `JohnSnowLabs:spark-nlp:1.4.2` package using Spark Shell Options.
### Clean up data with SQL transformations
Fusion has a Local Filesystem connector that can handle files such as CSV and JSON files. Using the Parallel Bulk Loader lets you leverage features that are not in the Local Filesystem connector, such as using SQL to clean up the input data.
Use this transform Scala script:
```scala theme={"dark"}
import com.johnsnowlabs.nlp._
import com.johnsnowlabs.nlp.annotators._
import org.apache.spark.ml.Pipeline
import com.johnsnowlabs.nlp.annotators.sbd.pragmatic.SentenceDetector
def transform(inputDF: Dataset[Row]) : Dataset[Row] = {
val documentAssembler = new DocumentAssembler().setInputCol("plot_txt_en").setOutputCol("document")
val sentenceDetector = new SentenceDetector().setInputCols(Array("document")).setOutputCol("sentences")
val finisher = new Finisher()
.setInputCols("sentences")
.setOutputCols("sentences_ss")
.setOutputAsArray(true)
.setCleanAnnotations(false)
val pipeline = new Pipeline().setStages(Array(documentAssembler,sentenceDetector,finisher))
pipeline.fit(inputDF).transform(inputDF).drop("document").drop("sentences")
}
```
Be sure to add the `JohnSnowLabs:spark-nlp:1.4.2` package using Spark Shell Options.
### Clean up data with SQL transformations
Fusion has a Local Filesystem connector that can handle files such as CSV and JSON files. Using the Parallel Bulk Loader lets you leverage features that are not in the Local Filesystem connector, such as using SQL to clean up the input data.
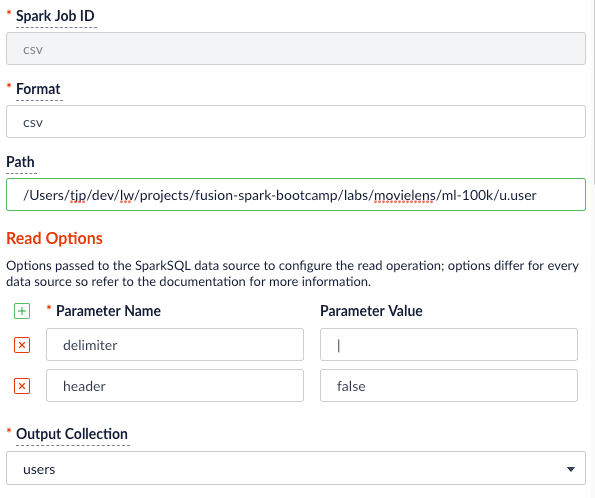 Use the following SQL to clean up the input data before indexing:
```sql theme={"dark"}
SELECT _c0 as user_id,
CAST(_c1 as INT) as age,
_c2 as gender,
_c3 as occupation,
_c4 as zip_code
FROM _input
Job JSON:
{
"type" : "parallel-bulk-loader",
"id" : "csv",
"format" : "csv",
"path" : "/Users/tjp/dev/lw/projects/fusion-spark-bootcamp/labs/movielens/ml-100k/u.user",
"readOptions" : [ {
"key" : "delimiter",
"value" : "|"
}, {
"key" : "header",
"value" : "false"
} ],
"outputCollection" : "users",
"clearDatasource" : false,
"defineFieldsUsingInputSchema" : true,
"atomicUpdates" : false,
"transformSql" : "SELECT _c0 as user_id, \n CAST(_c1 as INT) as age, \n _c2 as gender,\n _c3 as occupation,\n _c4 as zip_code \n FROM _input"
}
```
### Read from S3
It is easy to read from an S3 bucket without pulling data down to your local workstation first. To avoid exposing your AWS credentials, add them to a file named `core-site.xml` in the `apps/spark-dist/conf` directory, such as:
```xml theme={"dark"}
Use the following SQL to clean up the input data before indexing:
```sql theme={"dark"}
SELECT _c0 as user_id,
CAST(_c1 as INT) as age,
_c2 as gender,
_c3 as occupation,
_c4 as zip_code
FROM _input
Job JSON:
{
"type" : "parallel-bulk-loader",
"id" : "csv",
"format" : "csv",
"path" : "/Users/tjp/dev/lw/projects/fusion-spark-bootcamp/labs/movielens/ml-100k/u.user",
"readOptions" : [ {
"key" : "delimiter",
"value" : "|"
}, {
"key" : "header",
"value" : "false"
} ],
"outputCollection" : "users",
"clearDatasource" : false,
"defineFieldsUsingInputSchema" : true,
"atomicUpdates" : false,
"transformSql" : "SELECT _c0 as user_id, \n CAST(_c1 as INT) as age, \n _c2 as gender,\n _c3 as occupation,\n _c4 as zip_code \n FROM _input"
}
```
### Read from S3
It is easy to read from an S3 bucket without pulling data down to your local workstation first. To avoid exposing your AWS credentials, add them to a file named `core-site.xml` in the `apps/spark-dist/conf` directory, such as:
```xml theme={"dark"}
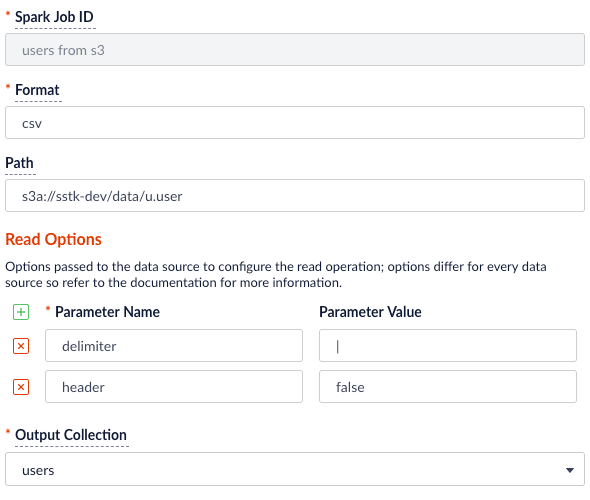 You will need to add the `org.apache.hadoop:hadoop-aws:2.7.3` package to the job using the `--packages` Spark option. Also, you will need to exclude the `com.fasterxml.jackson.core:jackson-core,joda-time:joda-time` packages using the `--exclude-packages` option.
You will need to add the `org.apache.hadoop:hadoop-aws:2.7.3` package to the job using the `--packages` Spark option. Also, you will need to exclude the `com.fasterxml.jackson.core:jackson-core,joda-time:joda-time` packages using the `--exclude-packages` option.
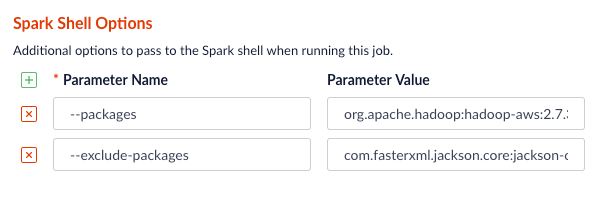 You can also read from Google Cloud Storage (GCS), but you will need a few more properties in your `core-site.xml`; see [Installing the Cloud Storage connector](https://cloud.google.com/dataproc/docs/concepts/connectors/install-storage-connector).
### Read from Parquet
Reading from parquet files is built into Spark using the "parquet" format. For additional read options, see
[Configuration of Parquet](https://spark.apache.org/docs/latest/sql-programming-guide.html#configuration).
You can also read from Google Cloud Storage (GCS), but you will need a few more properties in your `core-site.xml`; see [Installing the Cloud Storage connector](https://cloud.google.com/dataproc/docs/concepts/connectors/install-storage-connector).
### Read from Parquet
Reading from parquet files is built into Spark using the "parquet" format. For additional read options, see
[Configuration of Parquet](https://spark.apache.org/docs/latest/sql-programming-guide.html#configuration).
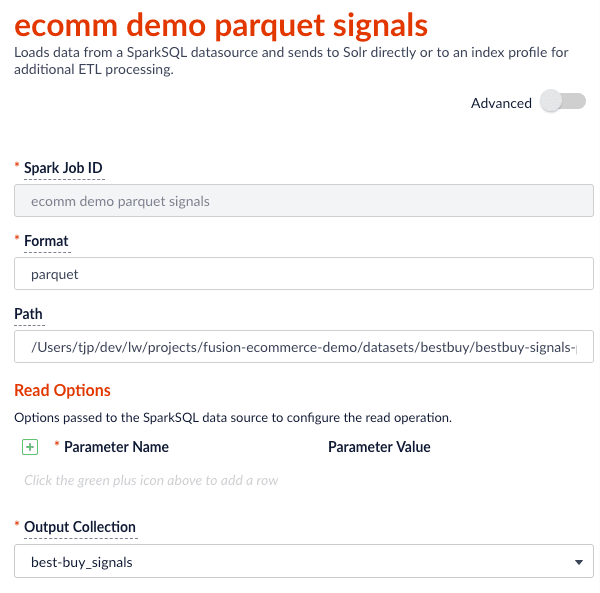 Job JSON:
```json theme={"dark"}
{
"type" : "parallel-bulk-loader",
"id" : "ecomm demo parquet signals",
"format" : "parquet",
"path" : "./part-00000-c1951958-98ae-4f2a-b7b4-2e3a69fcf403-c000.snappy.parquet",
"outputCollection" : "best-buy_signals",
"clearDatasource" : false,
"defineFieldsUsingInputSchema" : true,
"atomicUpdates" : false
}
```
This example also uses the `transformScala` option to filter and transform the input DataFrame into a better form for indexing using the following Scala script:
```scala theme={"dark"}
import java.util.Calendar
import java.util.Locale
import java.util.TimeZone
def transform(inputDF: Dataset[Row]) : Dataset[Row] = {
{/* // do transformations and/or filter the inputDF here */}
val signalsDF =
inputDF.filter((unix_timestamp($"timestamp_tdt", "MM/dd/yyyy HH:mm:ss.SSS") < 1325376000))
val now = System.currentTimeMillis()
val maxDate = signalsDF.agg(max("timestamp_tdt")).take(1)(0).getAs[java.sql.Timestamp](0).getTime
val diff = now - maxDate
val add_time =
udf((t: java.sql.Timestamp, diff : Long) => new java.sql.Timestamp(t.getTime + diff))
val day_of_week = udf((t: java.sql.Timestamp) => {
val calendar = Calendar.getInstance(TimeZone.getTimeZone("UTC"))
calendar.setTimeInMillis(t.getTime)
calendar.getDisplayName(Calendar.DAY_OF_WEEK, Calendar.LONG, Locale.getDefault)
})
{/* //Remap some columns to bring the timestamps current */}
signalsDF
.withColumnRenamed("timestamp_tdt", "orig_timestamp_tdt").withColumn("timestamp_tdt", add_time($"orig_timestamp_tdt", lit(diff)))
.withColumn("date", $"timestamp_tdt")
.withColumn("tx_timestamp_txt", date_format($"timestamp_tdt", "E YYYY-MM-d HH:mm:ss.SSS Z"))
.withColumn("param.query_time_dt", $"timestamp_tdt")
.withColumn("date_day", date_format(date_sub($"date", 0), "YYYY-MM-d'T'HH:mm:ss.SSS'Z'"))
.withColumn("date_month", date_format(trunc($"date", "mm"), "YYYY-MM-d'T'HH:mm:ss.SSS'Z'"))
.withColumn("date_year", date_format(trunc($"date", "yyyy"), "YYYY-MM-d'T'HH:mm:ss.SSS'Z'"))
.withColumn("day_of_week", day_of_week($"date"))
}
```
### Read from JDBC tables
You can use the Parallel Bulk Loader to parallelize reads from JDBC tables, if the tables have numeric columns that can be partitioned into relatively equal partition sizes. In the example below, we partition the employees table into 4 partitions using the `emp_no` column (`int`). Behind the scenes, Spark sends four separate queries to the database and processes the result sets in parallel.
#### Load the JDBC driver JAR file into the Blob store
Before you ingest from a JDBC data source, you need to use the Fusion Admin UI to upload the JDBC driver JAR file into the blob store.
Alternatively, you can add the JAR file to the Fusion blob store with `resourceType=spark:jar`; for example:
```bash wrap theme={"dark"}
curl -XPUT -H "Content-type:application/octet-stream" "http://
Job JSON:
```json theme={"dark"}
{
"type" : "parallel-bulk-loader",
"id" : "ecomm demo parquet signals",
"format" : "parquet",
"path" : "./part-00000-c1951958-98ae-4f2a-b7b4-2e3a69fcf403-c000.snappy.parquet",
"outputCollection" : "best-buy_signals",
"clearDatasource" : false,
"defineFieldsUsingInputSchema" : true,
"atomicUpdates" : false
}
```
This example also uses the `transformScala` option to filter and transform the input DataFrame into a better form for indexing using the following Scala script:
```scala theme={"dark"}
import java.util.Calendar
import java.util.Locale
import java.util.TimeZone
def transform(inputDF: Dataset[Row]) : Dataset[Row] = {
{/* // do transformations and/or filter the inputDF here */}
val signalsDF =
inputDF.filter((unix_timestamp($"timestamp_tdt", "MM/dd/yyyy HH:mm:ss.SSS") < 1325376000))
val now = System.currentTimeMillis()
val maxDate = signalsDF.agg(max("timestamp_tdt")).take(1)(0).getAs[java.sql.Timestamp](0).getTime
val diff = now - maxDate
val add_time =
udf((t: java.sql.Timestamp, diff : Long) => new java.sql.Timestamp(t.getTime + diff))
val day_of_week = udf((t: java.sql.Timestamp) => {
val calendar = Calendar.getInstance(TimeZone.getTimeZone("UTC"))
calendar.setTimeInMillis(t.getTime)
calendar.getDisplayName(Calendar.DAY_OF_WEEK, Calendar.LONG, Locale.getDefault)
})
{/* //Remap some columns to bring the timestamps current */}
signalsDF
.withColumnRenamed("timestamp_tdt", "orig_timestamp_tdt").withColumn("timestamp_tdt", add_time($"orig_timestamp_tdt", lit(diff)))
.withColumn("date", $"timestamp_tdt")
.withColumn("tx_timestamp_txt", date_format($"timestamp_tdt", "E YYYY-MM-d HH:mm:ss.SSS Z"))
.withColumn("param.query_time_dt", $"timestamp_tdt")
.withColumn("date_day", date_format(date_sub($"date", 0), "YYYY-MM-d'T'HH:mm:ss.SSS'Z'"))
.withColumn("date_month", date_format(trunc($"date", "mm"), "YYYY-MM-d'T'HH:mm:ss.SSS'Z'"))
.withColumn("date_year", date_format(trunc($"date", "yyyy"), "YYYY-MM-d'T'HH:mm:ss.SSS'Z'"))
.withColumn("day_of_week", day_of_week($"date"))
}
```
### Read from JDBC tables
You can use the Parallel Bulk Loader to parallelize reads from JDBC tables, if the tables have numeric columns that can be partitioned into relatively equal partition sizes. In the example below, we partition the employees table into 4 partitions using the `emp_no` column (`int`). Behind the scenes, Spark sends four separate queries to the database and processes the result sets in parallel.
#### Load the JDBC driver JAR file into the Blob store
Before you ingest from a JDBC data source, you need to use the Fusion Admin UI to upload the JDBC driver JAR file into the blob store.
Alternatively, you can add the JAR file to the Fusion blob store with `resourceType=spark:jar`; for example:
```bash wrap theme={"dark"}
curl -XPUT -H "Content-type:application/octet-stream" "http://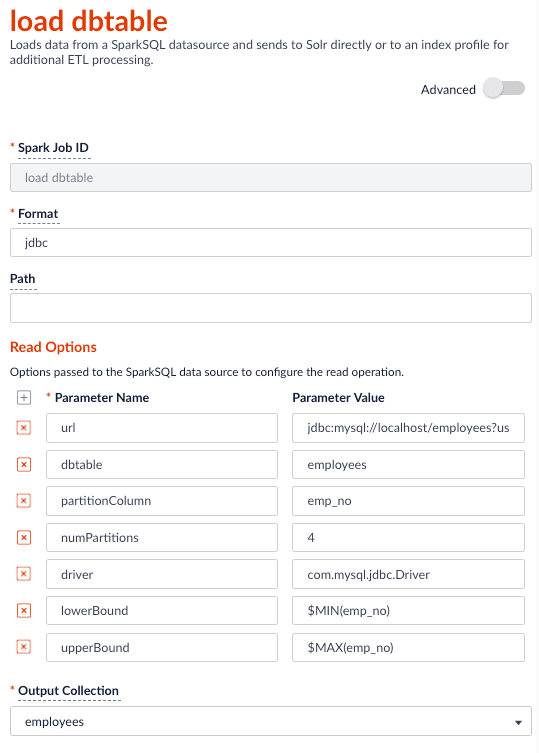 For more information on reading from JDBC-compliant databases, see:
* [http://spark.apache.org/docs/latest/sql-programming-guide.html#jdbc-to-other-databases](http://spark.apache.org/docs/latest/sql-programming-guide.html#jdbc-to-other-databases)
* [https://medium.com/@radek.strnad/tips-for-using-jdbc-in-apache-spark-sql-396ea7b2e3d3](https://medium.com/@radek.strnad/tips-for-using-jdbc-in-apache-spark-sql-396ea7b2e3d3)
```json theme={"dark"}
{
"type" : "parallel-bulk-loader",
"id" : "load dbtable",
"format" : "jdbc",
"readOptions" : [ {
"key" : "url",
"value" : "jdbc:mysql://localhost/employees?user=?&password=?"
}, {
"key" : "dbtable",
"value" : "employees"
}, {
"key" : "partitionColumn",
"value" : "emp_no"
}, {
"key" : "numPartitions",
"value" : "4"
}, {
"key" : "driver",
"value" : "com.mysql.jdbc.Driver"
}, {
"key" : "lowerBound",
"value" : "$MIN(emp_no)"
}, {
"key" : "upperBound",
"value" : "$MAX(emp_no)"
} ],
"outputCollection" : "employees",
"clearDatasource" : false,
"defineFieldsUsingInputSchema" : true,
"atomicUpdates" : false
}
```
Notice the use of the `$MIN(emp_no)` and `$MAX(emp_no)` macros in the read options. These are macros offered by the Parallel Bulk Loader to help configure parallel reads of JDBC tables. Behind the scenes, the macros are translated into SQL queries to get the MAX and MIN values of the specified field, which Spark uses to compute splits for partitioned queries. As mentioned above, the field must be numeric and must have a relatively balanced distribution of values between MAX and MIN; otherwise, you are unlikely to see much performance benefit to partitioning.
### Index HBase tables
To index an HBase table, use the [Hortonworks connector](https://github.com/hortonworks-spark/shc).
For more information on reading from JDBC-compliant databases, see:
* [http://spark.apache.org/docs/latest/sql-programming-guide.html#jdbc-to-other-databases](http://spark.apache.org/docs/latest/sql-programming-guide.html#jdbc-to-other-databases)
* [https://medium.com/@radek.strnad/tips-for-using-jdbc-in-apache-spark-sql-396ea7b2e3d3](https://medium.com/@radek.strnad/tips-for-using-jdbc-in-apache-spark-sql-396ea7b2e3d3)
```json theme={"dark"}
{
"type" : "parallel-bulk-loader",
"id" : "load dbtable",
"format" : "jdbc",
"readOptions" : [ {
"key" : "url",
"value" : "jdbc:mysql://localhost/employees?user=?&password=?"
}, {
"key" : "dbtable",
"value" : "employees"
}, {
"key" : "partitionColumn",
"value" : "emp_no"
}, {
"key" : "numPartitions",
"value" : "4"
}, {
"key" : "driver",
"value" : "com.mysql.jdbc.Driver"
}, {
"key" : "lowerBound",
"value" : "$MIN(emp_no)"
}, {
"key" : "upperBound",
"value" : "$MAX(emp_no)"
} ],
"outputCollection" : "employees",
"clearDatasource" : false,
"defineFieldsUsingInputSchema" : true,
"atomicUpdates" : false
}
```
Notice the use of the `$MIN(emp_no)` and `$MAX(emp_no)` macros in the read options. These are macros offered by the Parallel Bulk Loader to help configure parallel reads of JDBC tables. Behind the scenes, the macros are translated into SQL queries to get the MAX and MIN values of the specified field, which Spark uses to compute splits for partitioned queries. As mentioned above, the field must be numeric and must have a relatively balanced distribution of values between MAX and MIN; otherwise, you are unlikely to see much performance benefit to partitioning.
### Index HBase tables
To index an HBase table, use the [Hortonworks connector](https://github.com/hortonworks-spark/shc).
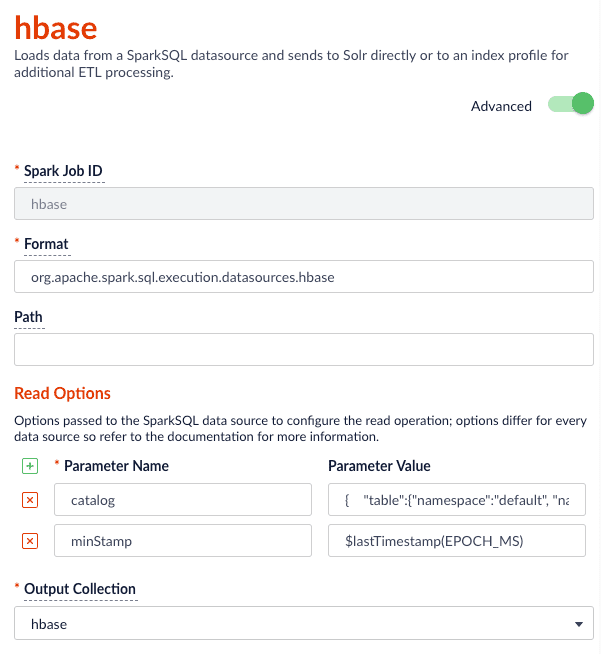 Notice the use of the `$lastTimestamp` macro in the read options. This lets us filter rows read from HBase using the timestamp of the last document the Parallel Bulk Loader wrote to Solr, that is, to get the newest updates from HBase only (incremental updates). Most Spark data sources provide a way to filter results based on timestamp.
Job JSON:
```json theme={"dark"}
{
"type" : "parallel-bulk-loader",
"id" : "hbase",
"format" : "org.apache.spark.sql.execution.datasources.hbase",
"readOptions" : [ {
"key" : "catalog",
"value" : "{ \"table\":{\"namespace\":\"default\", \"name\":\"fusion_nums\"}, \"rowkey\":\"key\", \"columns\":{ \"id\":{\"cf\":\"rowkey\", \"col\":\"key\", \"type\":\"string\"}, \"lw_c1_s\":{\"cf\":\"lw\", \"col\":\"c1\", \"type\":\"string\"}, \"lw_c2_s\":{\"cf\":\"lw\", \"col\":\"c2\", \"type\":\"string\"} } }"
}, {
"key" : "minStamp",
"value" : "$lastTimestamp(EPOCH_MS)"
} ],
"outputCollection" : "hbase",
"timestampFieldName" : "timestamp_tdt",
"clearDatasource" : false,
"defineFieldsUsingInputSchema" : true,
"atomicUpdates" : false,
"shellOptions" : [ {
"key" : "--packages",
"value" : "com.hortonworks:shc-core:1.1.1-2.1-s_2.11"
}, {
"key" : "--repositories",
"value" : "https://mvnrepository.com/repos/hortonworks-releases"
} ]
}
```
### Index Elastic data
With Elasticsearch 6.2.2 using the `org.elasticsearch:elasticsearch-spark-20_2.11:6.2.1` package, here is a Scala script to run in `bin/spark-shell` to index some test data:
```scala theme={"dark"}
import spark.implicits._
case class SimpsonCharacter(name: String, actor: String, episodeDebut: String)
val simpsonsDF = sc.parallelize(
SimpsonCharacter("Homer", "Dan Castellaneta", "Good Night") ::
SimpsonCharacter("Marge", "Julie Kavner", "Good Night") ::
SimpsonCharacter("Bart", "Nancy Cartwright", "Good Night") ::
SimpsonCharacter("Lisa", "Yeardley Smith", "Good Night") ::
SimpsonCharacter("Maggie", "Liz Georges and more", "Good Night") ::
SimpsonCharacter("Sideshow Bob", "Kelsey Grammer", "The Telltale Head") :: Nil).toDF()
val writeOpts = Map("es.nodes" -> "127.0.0.1",
"es.port" -> "9200",
"es.index.auto.create" -> "true",
"es.resouce.auto.create" -> "shows/simpsons")
simpsonsDF.write.format("org.elasticsearch.spark.sql").mode("Overwrite").save("shows/simpsons")
```
Notice the use of the `$lastTimestamp` macro in the read options. This lets us filter rows read from HBase using the timestamp of the last document the Parallel Bulk Loader wrote to Solr, that is, to get the newest updates from HBase only (incremental updates). Most Spark data sources provide a way to filter results based on timestamp.
Job JSON:
```json theme={"dark"}
{
"type" : "parallel-bulk-loader",
"id" : "hbase",
"format" : "org.apache.spark.sql.execution.datasources.hbase",
"readOptions" : [ {
"key" : "catalog",
"value" : "{ \"table\":{\"namespace\":\"default\", \"name\":\"fusion_nums\"}, \"rowkey\":\"key\", \"columns\":{ \"id\":{\"cf\":\"rowkey\", \"col\":\"key\", \"type\":\"string\"}, \"lw_c1_s\":{\"cf\":\"lw\", \"col\":\"c1\", \"type\":\"string\"}, \"lw_c2_s\":{\"cf\":\"lw\", \"col\":\"c2\", \"type\":\"string\"} } }"
}, {
"key" : "minStamp",
"value" : "$lastTimestamp(EPOCH_MS)"
} ],
"outputCollection" : "hbase",
"timestampFieldName" : "timestamp_tdt",
"clearDatasource" : false,
"defineFieldsUsingInputSchema" : true,
"atomicUpdates" : false,
"shellOptions" : [ {
"key" : "--packages",
"value" : "com.hortonworks:shc-core:1.1.1-2.1-s_2.11"
}, {
"key" : "--repositories",
"value" : "https://mvnrepository.com/repos/hortonworks-releases"
} ]
}
```
### Index Elastic data
With Elasticsearch 6.2.2 using the `org.elasticsearch:elasticsearch-spark-20_2.11:6.2.1` package, here is a Scala script to run in `bin/spark-shell` to index some test data:
```scala theme={"dark"}
import spark.implicits._
case class SimpsonCharacter(name: String, actor: String, episodeDebut: String)
val simpsonsDF = sc.parallelize(
SimpsonCharacter("Homer", "Dan Castellaneta", "Good Night") ::
SimpsonCharacter("Marge", "Julie Kavner", "Good Night") ::
SimpsonCharacter("Bart", "Nancy Cartwright", "Good Night") ::
SimpsonCharacter("Lisa", "Yeardley Smith", "Good Night") ::
SimpsonCharacter("Maggie", "Liz Georges and more", "Good Night") ::
SimpsonCharacter("Sideshow Bob", "Kelsey Grammer", "The Telltale Head") :: Nil).toDF()
val writeOpts = Map("es.nodes" -> "127.0.0.1",
"es.port" -> "9200",
"es.index.auto.create" -> "true",
"es.resouce.auto.create" -> "shows/simpsons")
simpsonsDF.write.format("org.elasticsearch.spark.sql").mode("Overwrite").save("shows/simpsons")
```
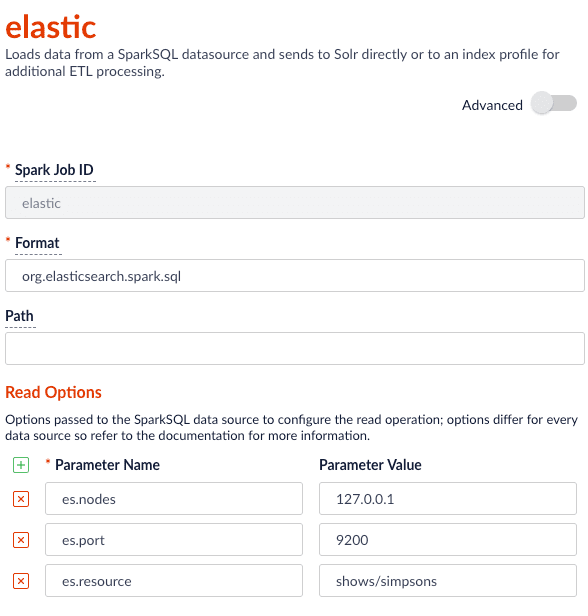 Job JSON:
```json theme={"dark"}
{
"type" : "parallel-bulk-loader",
"id" : "elastic",
"format" : "org.elasticsearch.spark.sql",
"readOptions" : [ {
"key" : "es.nodes",
"value" : "127.0.0.1"
}, {
"key" : "es.port",
"value" : "9200"
}, {
"key" : "es.resource",
"value" : "shows/simpsons"
} ],
"outputCollection" : "hbase_signals_aggr",
"clearDatasource" : false,
"defineFieldsUsingInputSchema" : true,
"atomicUpdates" : false,
"shellOptions" : [ {
"key" : "--packages",
"value" : "org.elasticsearch:elasticsearch-spark-20_2.11:6.2.2"
} ]
}
```
### Read from Couchbase
To index a Couchbase bucket, use the official Couchbase Spark connector found [here](https://spark-packages.org/package/couchbase/couchbase-spark-connector).
For example, we will create a test bucket in Couchbase. If you already have a bucket in Couchbase, feel free to use that and skip to the test data setup section. This test was performed using Couchbase Server 6.0.0.
1. Create a bucket test in the Couchbase admin UI. Give access to a system account user to use in the Parallel Bulk Loader job config.
2. Connect to Couchbase using the command line client cbq. For example, `cbq -e=http://
Job JSON:
```json theme={"dark"}
{
"type" : "parallel-bulk-loader",
"id" : "elastic",
"format" : "org.elasticsearch.spark.sql",
"readOptions" : [ {
"key" : "es.nodes",
"value" : "127.0.0.1"
}, {
"key" : "es.port",
"value" : "9200"
}, {
"key" : "es.resource",
"value" : "shows/simpsons"
} ],
"outputCollection" : "hbase_signals_aggr",
"clearDatasource" : false,
"defineFieldsUsingInputSchema" : true,
"atomicUpdates" : false,
"shellOptions" : [ {
"key" : "--packages",
"value" : "org.elasticsearch:elasticsearch-spark-20_2.11:6.2.2"
} ]
}
```
### Read from Couchbase
To index a Couchbase bucket, use the official Couchbase Spark connector found [here](https://spark-packages.org/package/couchbase/couchbase-spark-connector).
For example, we will create a test bucket in Couchbase. If you already have a bucket in Couchbase, feel free to use that and skip to the test data setup section. This test was performed using Couchbase Server 6.0.0.
1. Create a bucket test in the Couchbase admin UI. Give access to a system account user to use in the Parallel Bulk Loader job config.
2. Connect to Couchbase using the command line client cbq. For example, `cbq -e=http://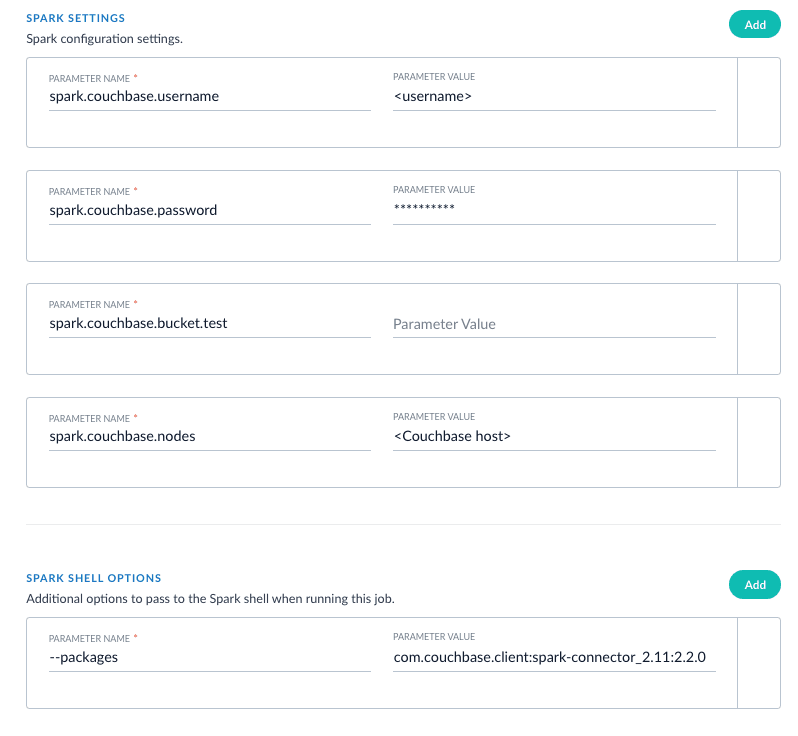 ### XML setup
XML is a supported format that requires settings for `format` and `--packages`. In addition, you must specify the filepath in the `readOptions` section. For example:
```json theme={"dark"}
{
"type": "parallel-bulk-loader",
"id": "pbl",
"format": "com.databricks.spark.xml",
"path": "this-is-ignored",
"readOptions": [
{
"key": "rowTag",
"value": "tag_name_representing_record"
},
{
"key": "path",
"value": "/home/user/file.xml.gz"
}
],
"outputCollection": "output_collection_name",
"clearDatasource": true,
"defineFieldsUsingInputSchema": true,
"atomicUpdates": false,
"transformScala": "",
"shellOptions": [
{
"key": "--packages",
"value": "com.databricks:spark-xml_2.11:0.5.0"
}
],
"cacheAfterRead": false
}
```
### XML setup
XML is a supported format that requires settings for `format` and `--packages`. In addition, you must specify the filepath in the `readOptions` section. For example:
```json theme={"dark"}
{
"type": "parallel-bulk-loader",
"id": "pbl",
"format": "com.databricks.spark.xml",
"path": "this-is-ignored",
"readOptions": [
{
"key": "rowTag",
"value": "tag_name_representing_record"
},
{
"key": "path",
"value": "/home/user/file.xml.gz"
}
],
"outputCollection": "output_collection_name",
"clearDatasource": true,
"defineFieldsUsingInputSchema": true,
"atomicUpdates": false,
"transformScala": "",
"shellOptions": [
{
"key": "--packages",
"value": "com.databricks:spark-xml_2.11:0.5.0"
}
],
"cacheAfterRead": false
}
```