 See also [Best Practices](/docs/4/fusion-ai/concepts/smart-answers/best-practices).
See also [Best Practices](/docs/4/fusion-ai/concepts/smart-answers/best-practices).
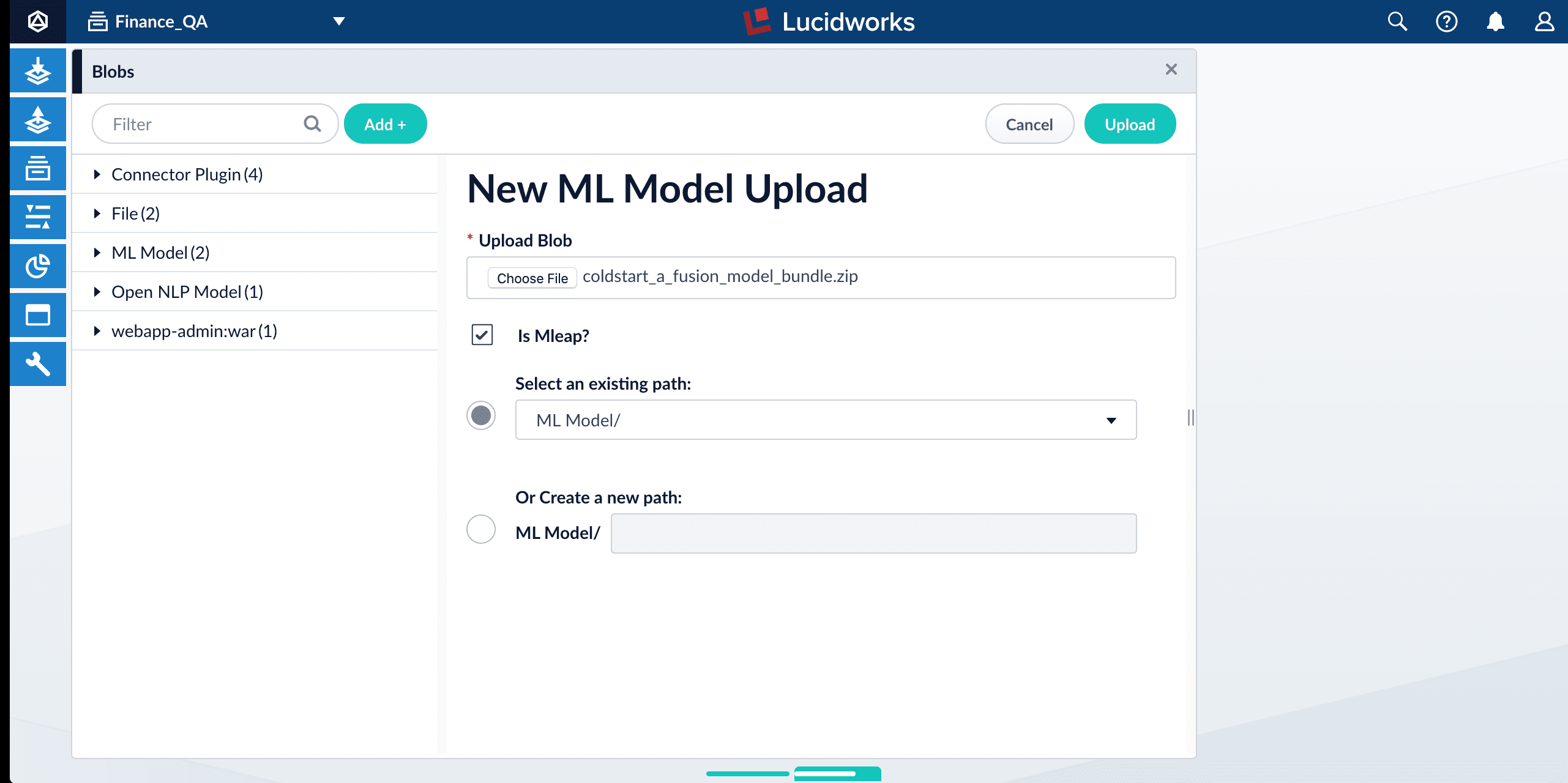 5. Click **Upload**.
5. Click **Upload**.
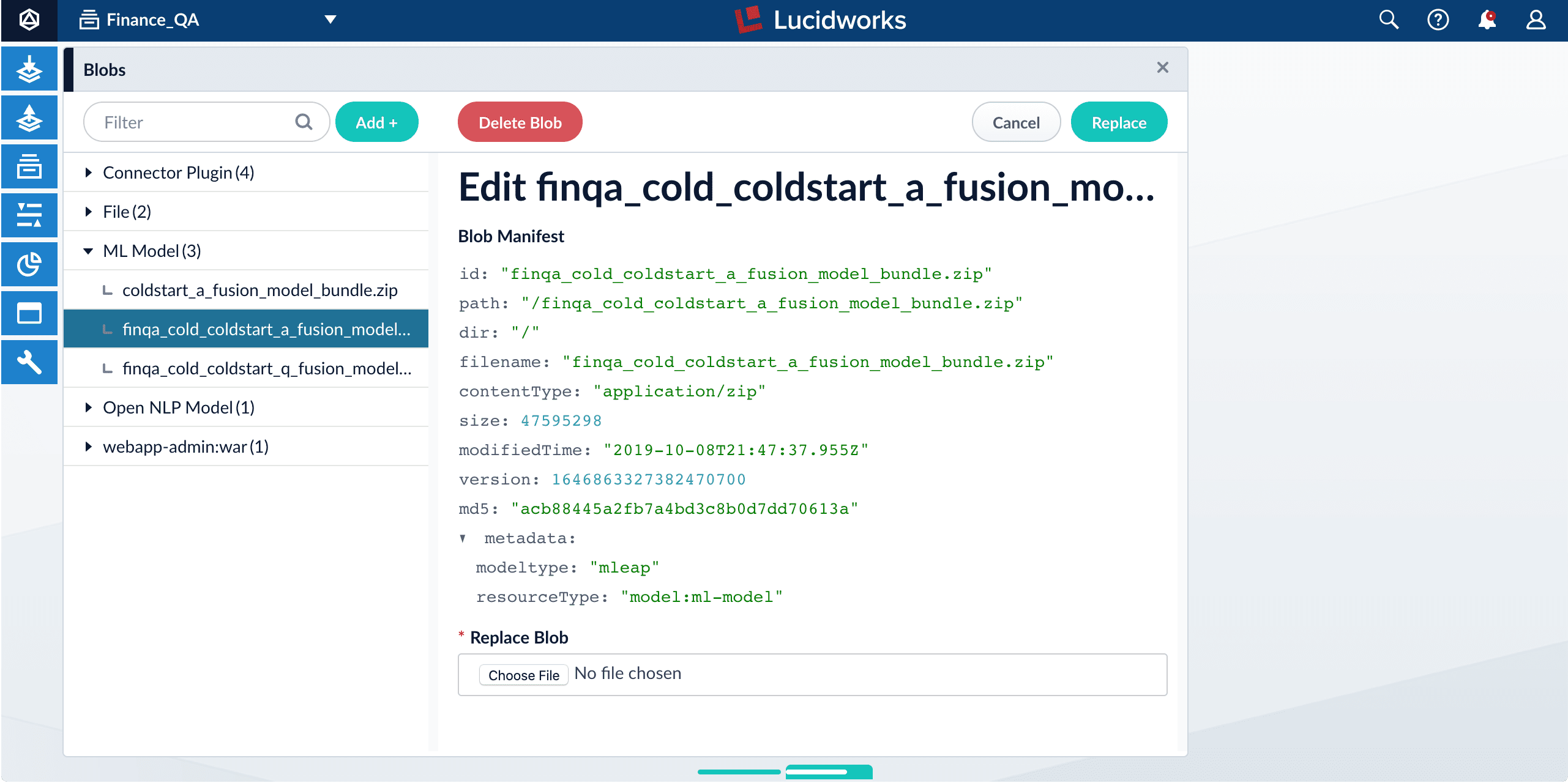 6. Repeat steps 2-5 for the other model file.
## Fusion configuration overview
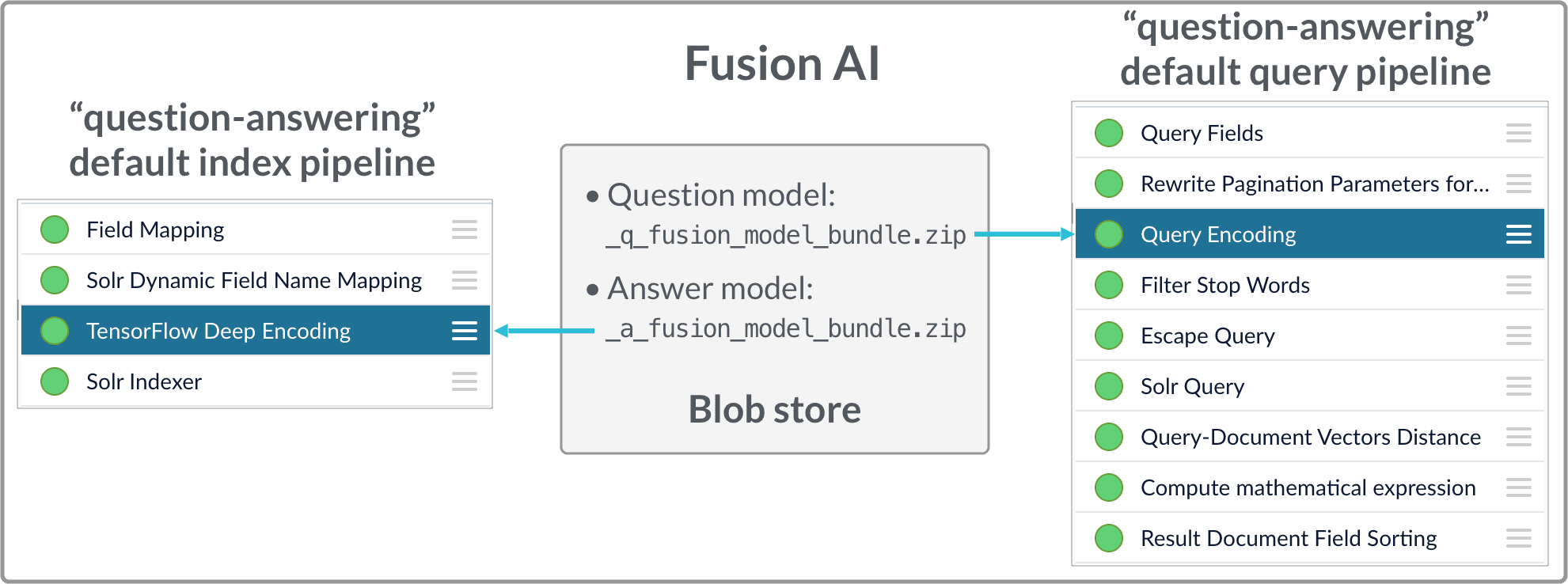
* Fusion index pipeline
The index pipeline uses the trained model in `x_a_fusion_model_bundle.zip` to generate dense vectors for the documents to be indexed.
* Fusion query pipeline
The query pipeline uses the trained model in `x_q_fusion_model_bundle.zip` to generate dense vectors for incoming questions on the fly, then compare those with the indexed dense vectors for answers to find answers, or with the indexed dense vectors for historical questions to find similar questions.
Another option is to have two separate index stages, one for questions and another for answers. Then, at query time, two query stages compute query-to-question distance and query-to-answer distance. Both scores are ensembled into a final similarity score. The two options are illustrated in [Pipeline setup examples](#pipeline-setup-examples).
## How to configure the default pipelines
If you have an AI license, then the following default index and query pipelines are included in any newly-created Fusion app:
| Default index pipelines | Default query pipelines |
| ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `question-answering`: For encoding one field. | `question-answering`: Calculates vectors distances between an encoded query and one document vector field. Should be used together with `question-answering` index pipeline. |
| `question-answering-dual-fields`: For encoding two fields (question and answer pairs, for example). See [Configure the index pipeline](#configure-the-index-pipeline) below. | `question-answering-dual-fields`: Calculates vectors distances between an encoded query and two document vector fields. After that, scores are ensembled. Should be used together with the `question-answering-dual-fields` index pipeline. See [Configure the query pipeline](#configure-the-query-pipeline) below. |
### Configure the index pipeline
6. Repeat steps 2-5 for the other model file.
## Fusion configuration overview
* Fusion index pipeline
The index pipeline uses the trained model in `x_a_fusion_model_bundle.zip` to generate dense vectors for the documents to be indexed.
* Fusion query pipeline
The query pipeline uses the trained model in `x_q_fusion_model_bundle.zip` to generate dense vectors for incoming questions on the fly, then compare those with the indexed dense vectors for answers to find answers, or with the indexed dense vectors for historical questions to find similar questions.
Another option is to have two separate index stages, one for questions and another for answers. Then, at query time, two query stages compute query-to-question distance and query-to-answer distance. Both scores are ensembled into a final similarity score. The two options are illustrated in [Pipeline setup examples](#pipeline-setup-examples).
## How to configure the default pipelines
If you have an AI license, then the following default index and query pipelines are included in any newly-created Fusion app:
| Default index pipelines | Default query pipelines |
| ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `question-answering`: For encoding one field. | `question-answering`: Calculates vectors distances between an encoded query and one document vector field. Should be used together with `question-answering` index pipeline. |
| `question-answering-dual-fields`: For encoding two fields (question and answer pairs, for example). See [Configure the index pipeline](#configure-the-index-pipeline) below. | `question-answering-dual-fields`: Calculates vectors distances between an encoded query and two document vector fields. After that, scores are ensembled. Should be used together with the `question-answering-dual-fields` index pipeline. See [Configure the query pipeline](#configure-the-query-pipeline) below. |
### Configure the index pipeline
 1. Open the Index Workbench.
2. Load or create your datasource using the default question-answering index pipeline.
3. In the [TensorFlow Deep Encoding stage](/docs/4/fusion-ai/reference/index-pipeline-stages/tensorflow-deep-encoding-index-stage), change the value of **TensorFlow Deep Learning Encoder Model ID** to the model ID of the `x_a_fusion_model_bundle.zip` model that was uploaded to the blob store.
1. Open the Index Workbench.
2. Load or create your datasource using the default question-answering index pipeline.
3. In the [TensorFlow Deep Encoding stage](/docs/4/fusion-ai/reference/index-pipeline-stages/tensorflow-deep-encoding-index-stage), change the value of **TensorFlow Deep Learning Encoder Model ID** to the model ID of the `x_a_fusion_model_bundle.zip` model that was uploaded to the blob store.
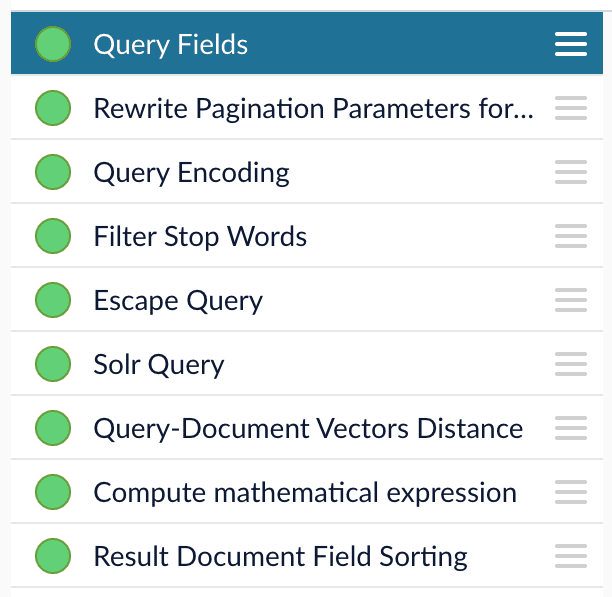 1. Open the Query Workbench.
2. Load or create your datasource using one of the default question-answering query pipelines.
3. In the [Query Fields stage](/docs/4/fusion-server/reference/pipeline-stages/query/search-fields-query-stage), update **Return Fields** to return additional fields that should be displayed with each answer, such as fields corresponding to title, text, or ID.\
It is recommended that you remove the asterisk (`*`) field and specify each individual field you want to return, as returning too many fields will affect runtime performance.\
Do not remove `compressed_document_vector_s`, `document_clusters_ss`, and `score` as these fields are necessary for later stages
4. In the [TensorFlow Deep Encoding stage](/docs/4/fusion-ai/reference/query-pipeline-stages/tensorflow-deep-encoding-query-stage), change **TensorFlow Deep Learning Encoder Model ID** value to the model ID of the `x_q_fusion_model_bundle.zip` model that was uploaded to the blob store.
1. Open the Query Workbench.
2. Load or create your datasource using one of the default question-answering query pipelines.
3. In the [Query Fields stage](/docs/4/fusion-server/reference/pipeline-stages/query/search-fields-query-stage), update **Return Fields** to return additional fields that should be displayed with each answer, such as fields corresponding to title, text, or ID.\
It is recommended that you remove the asterisk (`*`) field and specify each individual field you want to return, as returning too many fields will affect runtime performance.\
Do not remove `compressed_document_vector_s`, `document_clusters_ss`, and `score` as these fields are necessary for later stages
4. In the [TensorFlow Deep Encoding stage](/docs/4/fusion-ai/reference/query-pipeline-stages/tensorflow-deep-encoding-query-stage), change **TensorFlow Deep Learning Encoder Model ID** value to the model ID of the `x_q_fusion_model_bundle.zip` model that was uploaded to the blob store.