> ## Documentation Index
> Fetch the complete documentation index at: https://doc.lucidworks.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Smart Answers
export const LwTemplate = ({title = "Key questions to get you started", icon = "sparkles", cta = "Powered by Agent Studio", linkHref = "https://lucidworks.com/demo/?utm_source=docs&utm_medium=referral&utm_campaign=docs_cta_ai"}) => {
const [isLoaded, setIsLoaded] = useState(false);
useEffect(() => {
const timer = setTimeout(() => {
setIsLoaded(true);
}, 500);
return () => clearTimeout(timer);
}, []);
return
{isLoaded && `
}} />}
Powered by Lucidworks Agent Studio
;
};
[localhost link]: http://localhost:3000/docs/4/fusion-ai/concepts/smart-answers/overview
[mintlify link]: https://doc.lucidworks.com/docs/4/fusion-ai/concepts/smart-answers/overview
[old doc.lw link]: https://doc.lucidworks.com/fusion/5.9/461
Fusion Smart Answers brings the benefits of a versatile, scalable enterprise search platform to virtual assistants and chatbots.
This robust Q\&A system makes use of advanced deep learning techniques to match question/answer pairs and enable self-service for employees and customers, increasing search relevance and saving cost on answering incoming queries.
These features bring traditional search relevancy development and data science together into an easy-to-use configuration framework that leverages Fusion’s indexing and querying pipelines.
Even if you do not have an existing set of recorded interactions for question/answer pairs, you can still build a robust Q\&A system using our cold start solution, which improves relevancy by using machine learning (dense-vector semantic search) based on content documents.
## Example business use cases
Call center or IT support
* Embed this system as a self-help feature on your Help page or Contact Us page to reduce the call center load.
* Make it available to your customer support team to find the answers to already-solved problems.
Questions about products for e-commerce:
E-commerce websites can use this system to search "how to" content, product user manuals, or existing product questions. For example, amazon.com provides a search function on questions about each product.
Search in Slack, email conversations, or SharePoint FAQ docs
You can achieve fast knowledge extraction by applying this solution to these types of knowledge repositories.
Improve search for long queries
The cold start solution utilizes word embedding methods to capture semantic and contextual information for long queries or natural language questions. The cold start solution doesn’t require FAQ training data. Instead, it can use word vector training combined with Solr scores using our provided query pipeline.
## Getting started
To get started, you need a trained machine learning model. There are two methods for generating a model, depending on the kind of data you already have:
| The FAQ solution | The cold start solution |
| ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| Use this solution when you already have a collection of questions that have been asked before, and their answers. • Input: A dataset of question/answer pairs. • Training module: Deep learning See [FAQ Solution](/docs/4/fusion-ai/concepts/smart-answers/faq-solution) for details. | Use this solution when you have no historical FAQ data, or fewer than 200 question/answer pairs • Input: A body of content that can be used to answer questions. • Training module: Word2vec See [Cold Start Solution](/docs/4/fusion-ai/concepts/smart-answers/cold-start) for details. |
Each method requires a different model training procedure, but the model deployment procedure is the same for both.
The system combines the power of Solr and neural dense vectors search from deep learning. Neural dense vector retrieval transfers documents into a digital vector space to incorporate semantic and contextual information into query understanding.
## "Question-answering" pipelines and stages
Once you have trained and deployed your model, you can use one of the default pipelines that are automatically created with your Fusion app. Both pipelines are called `APP_NAME-question-answering`.
You must perform some **FAQ Solution** on these pipelines. For advanced configuration tips, see [Detailed Pipeline Setup](/docs/4/fusion-ai/reference/pipeline-setup).
The Smart Answers deployment procedure for the FAQ solution and the cold start solution is the same:
1. [Upload the question and answer models](#how-to-upload-the-models-to-the-blob-store) to the blob store.
2. [Configure the `question-answering` index pipeline](#configure-the-index-pipeline) so that it uses the answer model.
3. [Configure the `question-answering` query pipeline](#configure-the-query-pipeline) so that it uses the question model.
See also [Best Practices](/docs/4/fusion-ai/concepts/smart-answers/best-practices).
## How to upload the models to the blob store
Two model files are generated by the model training Docker job:
* `x_a_fusion_model_bundle.zip` - The answer model.
* `x_q_fusion_model_bundle.zip` - The question model.
Both files must be deployed to the Fusion [blob store](/docs/4/fusion-server/concepts/indexing/blob-storage).
**How to upload the deep-learning models to the blob store**
1. In the Fusion UI, navigate to **System** > **Blobs**.
2. Click **Add** > **ML Model**.
3. Click **Choose File** and select one of the model files.
4. Make sure the **Is Mleap?** checkbox is selected.
5. Click **Upload**.
6. Repeat steps 2-5 for the other model file.
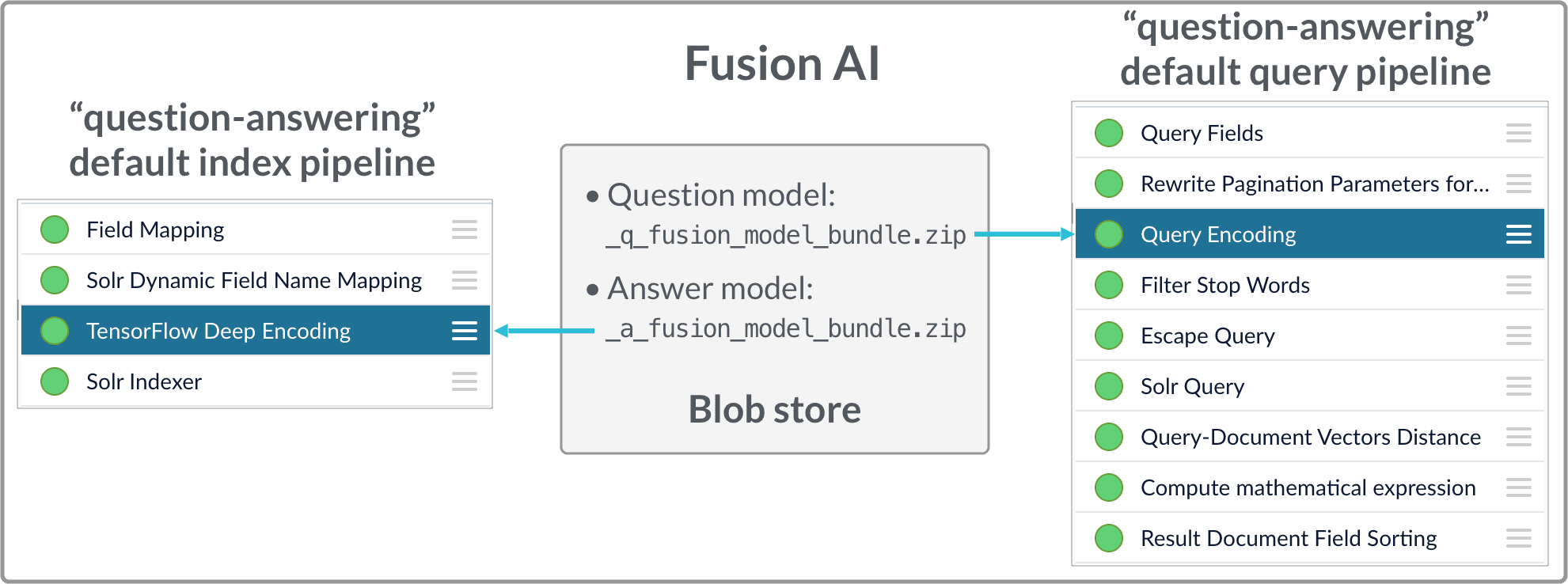
## Fusion configuration overview
* Fusion index pipeline
The index pipeline uses the trained model in `x_a_fusion_model_bundle.zip` to generate dense vectors for the documents to be indexed.
* Fusion query pipeline
The query pipeline uses the trained model in `x_q_fusion_model_bundle.zip` to generate dense vectors for incoming questions on the fly, then compare those with the indexed dense vectors for answers to find answers, or with the indexed dense vectors for historical questions to find similar questions.
Another option is to have two separate index stages, one for questions and another for answers. Then, at query time, two query stages compute query-to-question distance and query-to-answer distance. Both scores are ensembled into a final similarity score. The two options are illustrated in [Pipeline setup examples](#pipeline-setup-examples).
## How to configure the default pipelines
If you have an AI license, then the following default index and query pipelines are included in any newly-created Fusion app:
| Default index pipelines | Default query pipelines |
| ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `question-answering`: For encoding one field. | `question-answering`: Calculates vectors distances between an encoded query and one document vector field. Should be used together with `question-answering` index pipeline. |
| `question-answering-dual-fields`: For encoding two fields (question and answer pairs, for example). See [Configure the index pipeline](#configure-the-index-pipeline) below. | `question-answering-dual-fields`: Calculates vectors distances between an encoded query and two document vector fields. After that, scores are ensembled. Should be used together with the `question-answering-dual-fields` index pipeline. See [Configure the query pipeline](#configure-the-query-pipeline) below. |
### Configure the index pipeline
1. Open the Index Workbench.
2. Load or create your datasource using the default question-answering index pipeline.
3. In the [TensorFlow Deep Encoding stage](/docs/4/fusion-ai/reference/index-pipeline-stages/tensorflow-deep-encoding-index-stage), change the value of **TensorFlow Deep Learning Encoder Model ID** to the model ID of the `x_a_fusion_model_bundle.zip` model that was uploaded to the blob store.
The `_a_` (answer) model allows you to encode longer text.
4. Change **Document Feature Field** to the document field name to be processed and encoded into dense vectors.
5. Save the datasource.
6. Index your data.
### Configure the query pipeline
1. Open the Query Workbench.
2. Load or create your datasource using one of the default question-answering query pipelines.
3. In the [Query Fields stage](/docs/4/fusion-server/reference/pipeline-stages/query/search-fields-query-stage), update **Return Fields** to return additional fields that should be displayed with each answer, such as fields corresponding to title, text, or ID.\
It is recommended that you remove the asterisk (`*`) field and specify each individual field you want to return, as returning too many fields will affect runtime performance.\
Do not remove `compressed_document_vector_s`, `document_clusters_ss`, and `score` as these fields are necessary for later stages
4. In the [TensorFlow Deep Encoding stage](/docs/4/fusion-ai/reference/query-pipeline-stages/tensorflow-deep-encoding-query-stage), change **TensorFlow Deep Learning Encoder Model ID** value to the model ID of the `x_q_fusion_model_bundle.zip` model that was uploaded to the blob store.
The (`_q_`) (question) model is slightly more efficient for short natural-language questions.
5. Save the query pipeline.
## Pipeline Setup Examples
### Example 1: Index and retrieve question and answer separately
Based on your search Web page design, you can put best-matched questions and answers in separate sections, or if you only want to retrieve answers and serve to chatbot app, please index them separately in different documents.
For example, in the picture below, we construct the input file for the index pipeline such that the text part of the question/answer is stored in `text_t`, and we add an additional field `type_s` whose value is "question" or "answer" to separate the two types.
In the TensorFlow Deep Encoding stage, we specify **Document Feature Field** as `text_t` so that `compressed_document_vector_s` is generated based on this field.
At search time, we can apply a filter query on the `type_s` field to return either a question or an answer.
You can achieve a similar result by using the default `question-answering` index and query pipelines.
### Example 2: Index and retrieve question and answer together.
If you prefer to show question and answer together in one document (that is, treat the question as the title and the answer as the description), you can index them together in the same document. It’s similar to the `question-answering-dual-fields` index and query pipelines default setup.
For example, in the picture below, we added two TensorFlow Deep Encoding stages and named them Answers Encoding and Questions Encoding respectively. In the Questions Encoding stage, we specify **Document Feature Field** to be question\_t, and changed the default values for **Vector Field**, **Clusters Field** and **Distances Field** to question\_vector\_ds, question\_clusters\_ss and question\_distances\_ds respectively. In the Answers Encoding stage, we specify **Document Feature Field** to be answer\_t, and changed the default values for **Vector Field**, **Clusters Field** and **Distances Field** to answer\_vector\_ds, answer\_clusters\_ss and answer\_distances\_ds respectively. (Detailed information of the above field setup please refer to the “Appendix C: Detailed Pipeline Setup” section.)
Since we have two dense vectors generated in the index (compressed\_question\_vector\_s and compressed\_answer\_vector\_s), at query time, we need to compute query to question distance and query to answer distance. This can be setup as the picture shown below. We added two **Vectors distance per Query/Document** stages and named them QQ Distance and QA Distance respectively. In the QQ Distance stage, we changed the default values for **Document Vector Field** and **Document Vectors** **Distance Field** to compressed\_question\_vector\_s and qq\_distance respectively. In the QA Distance stage, we changed the default values for **Document Vector Field** and **Document Vectors** **Distance Field** to compressed\_answer\_vector\_s and qa\_distance respectively. (Detailed information of the above field setup please refer to the “Appendix C: Detailed Pipeline Setup” section.)
Now we have two distances (query to question distance and query to answer distance), we can ensemble them together with Solr score to get a final ranking score. This is recommended especially when you have limited FAQ dataset and want to utilize both question and answer information. This ensemble can be done in the **Compute mathematical expression** stage as shown below.
## Query pipeline evaluation
Stages and configurations of the query pipeline will impact ranking results. For example, we may need to make decisions about whether to use clustering option in the [TensorFlow Deep Encoding stage](/docs/4/fusion-ai/reference/query-pipeline-stages/tensorflow-deep-encoding-query-stage), what should be the weights of each ranking score in the **Compute mathematical expression** stage, whether adding other Fusion stages (such as text tagger, ML stage) would help. Comparing two different query pipelines with different models and setups may be needed as well.
The **Query Pipeline evaluation** job in the training docker image can help evaluate the rankings of Fusion returned results from different pipeline setups, additionally help search for the best set of weights in the ensemble score.
In order to evaluate the rankings, we need to know the ground truth answers for some testing questions. For example, user can provide around 200 testing questions, and for each question, we need to know which indexed answers are the correct answers in Fusion, so that we can compute positions of correct answers in the current ranking. User needs to provide a file in CSV format which contains the testing questions (**Testing query field** parameter in the job) and correct answer text or id (**Ground truth field** parameter in the job), put this file in the mapped input folder where we put other training data files, then specify the file name in the **Evaluation file name** parameter. NOTE: if there are multiple matching answers for a question, please put question and answer pairs in different rows. In Fusion, there should be a returned field which contains values that match the answer text or id, please specify this field in the **Answer or id field in Fusion** parameter. NOTE: if use answer text, please make sure the formatting of answer text in the evaluation file is the same as the answer text in Fusion so that we can find matches. Several Fusion access parameters are also needed in order to grab results from Fusion in batch, such as login username, password, host ip, app name, collection and pipeline name.
The job will provide a variety of metrics (controlled by \*\*Metrics list *parameter) at different positions (controlled by *Metrics\@k list** parameter) in the logs for the chosen final ranking score (specified in **Ranking score** parameter). For example, if choose **Ranking score** as “ensemble\_score”, the program will rank results by the ensemble score returned in **Compute mathematical expression** stage. If choose **Ranking score** as “score” (default field name for Solr score in Fusion), then the ranking evaluation will be based only on Solr score. In addition to the metrics in logs, a CSV results evaluation file will be generated. It will provide correct answer positions for each testing question as well as top returned results for each field specified in **Return fields** parameter. User can specify the file name for this results file in the **Ranking results file name** parameter, then download the file from `http://:5550/evaluation`.
Another function of this job is to help choose weights for different ranking scores such as Solr score, query to question distance, query to answer distance in **Compute mathematical expression** stage. If interested in performing this weights selection, please choose \*\*Whether perform weights selection *parameter to true, list the set of score names in *List of ranking scores for ensemble** parameter. Since we can use different scaling methods for Solr score in the stage, please choose which Solr scale function you used in the stage in **Solr scale function** parameter. **Target metric to use for weight selection** parameter allows to specify metric that should be optimized during weights selection, for example `recall@3`. Metric values at different positions for different weights combinations will be shown in the log, sorted descendingly based on metric specified above. NOTE: Weights selection can take a while to run for big evaluation datasets, thus if only interested in comparing pipelines, please turn this function off by specifying **Whether perform weights selection** parameter to false.
There are a few additional advanced parameters that might be useful but not required to provide. **Additional query parameters** allows to provide extra query parameters like `rowsFromSolrToRerank` in a dictionary format. **Sampling proportion** and **Sampling seed** provides a possibility to run evaluation job only on a sample of data.
Please make sure the Ranking score, answer text or id, and list of ranking scores for ensemble (if perform weights selection) are returned by Fusion by checking the fields returned in the Query Workbench. User can setup the returned fields in Return Fields section of Query Fields stage.
| Pipeline | Diagram | Stages |
| ------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| **"-question-answering" and "-question-answering-dual-fields" index pipelines** | | • [Field Mapping](/docs/4/fusion-server/reference/pipeline-stages/indexing/field-mapper-index-stage) • [Solr Dynamic Field Name Mapping](/docs/4/fusion-server/reference/pipeline-stages/indexing/solr-dynamic-field-name-mapping-index-stage) • [TensorFlow Deep Encoding](/docs/4/fusion-ai/reference/index-pipeline-stages/tensorflow-deep-encoding-index-stage) • [Solr Indexer](/docs/4/fusion-server/reference/pipeline-stages/indexing/solr-indexer-stage) |
| **"-question-answering" and "-question-answering-dual-fields" query pipelines** | | • [Query Fields](/docs/4/fusion-ai/reference/pipeline-setup#the-query-fields-stage) • [Rewrite Pagination Parameters for Reranking](/docs/4/fusion-ai/reference/pipeline-setup#the-rewrite-pagination-parameters-for-reranking-stage) • [TensorFlow Deep Encoding](/docs/4/fusion-ai/reference/pipeline-setup#the-tensorflow-deep-encoding-stage) ("Query Encoding") • [Filter Stop Words](/docs/4/fusion-ai/reference/pipeline-setup#the-filter-stop-words-stage) • [Escape Query](/docs/4/fusion-ai/reference/pipeline-setup#the-escape-query-stage) • [Query-Document Vectors Distance](/docs/4/fusion-ai/reference/pipeline-setup#the-query-document-vectors-distance-stage) • [Compute Mathematical Expression](/docs/4/fusion-ai/reference/pipeline-setup#the-compute-mathematical-expression-stage) • [Result Document Field Sorting](/docs/4/fusion-ai/reference/pipeline-setup#the-result-document-field-sorting-stage) |
## Learn more
## Set up a CPU AWS/Azure instance:
1. SSH into the instance.
2. [Install Docker](https://docs.docker.com/install/linux/docker-ce/ubuntu/).
3. Start the Docker service:
```bash theme={"dark"}
$ sudo service docker start
```
4. Add the current user to the “docker” group so you can execute Docker commands without using `sudo`:
```bash theme={"dark"}
$ sudo usermod -aG docker ${USER}
```
5. Log out and log back in again to pick up the new Docker group permissions.\
You can do this by closing your current SSH terminal window and reconnecting to your instance in a new one. Your new SSH session will have the appropriate Docker group permissions.
## Set up a GPU AWS instance:
1. SSH into the instance.
2. Install the official NVIDIA driver package:
```bash theme={"dark"}
$ sudo apt-key adv --fetch-keys http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/7fa2af80.pub
$ sudo sh -c 'echo "deb http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64 /" > /etc/apt/sources.list.d/cuda.list'
$ sudo apt-get update *&&* sudo apt-get install -y --no-install-recommends cuda-drivers
```
## Set up a GPU Azure VM:
1. Download and install the CUDA drivers from the NVIDIA website. For example, for Ubuntu 16.04 LTS:
```bash theme={"dark"}
$ CUDA_REPO_PKG=cuda-repo-ubuntu1604_10.0.130-1_amd64.deb
$ wget -O /tmp/${CUDA_REPO_PKG} http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/${CUDA_REPO_PKG}
$ sudo dpkg -i /tmp/${CUDA_REPO_PKG}
$ sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/7fa2af80.pub
$ rm -f /tmp/${CUDA_REPO_PKG}
$ sudo apt-get update
$ sudo apt-get install cuda-drivers
```
1. Download and install Docker:
```bash theme={"dark"}
sudo apt install docker.io
```
 See also [Best Practices](/docs/4/fusion-ai/concepts/smart-answers/best-practices).
## How to upload the models to the blob store
Two model files are generated by the model training Docker job:
* `x_a_fusion_model_bundle.zip` - The answer model.
* `x_q_fusion_model_bundle.zip` - The question model.
Both files must be deployed to the Fusion [blob store](/docs/4/fusion-server/concepts/indexing/blob-storage).
**How to upload the deep-learning models to the blob store**
1. In the Fusion UI, navigate to **System** > **Blobs**.
2. Click **Add** > **ML Model**.
3. Click **Choose File** and select one of the model files.
4. Make sure the **Is Mleap?** checkbox is selected.
See also [Best Practices](/docs/4/fusion-ai/concepts/smart-answers/best-practices).
## How to upload the models to the blob store
Two model files are generated by the model training Docker job:
* `x_a_fusion_model_bundle.zip` - The answer model.
* `x_q_fusion_model_bundle.zip` - The question model.
Both files must be deployed to the Fusion [blob store](/docs/4/fusion-server/concepts/indexing/blob-storage).
**How to upload the deep-learning models to the blob store**
1. In the Fusion UI, navigate to **System** > **Blobs**.
2. Click **Add** > **ML Model**.
3. Click **Choose File** and select one of the model files.
4. Make sure the **Is Mleap?** checkbox is selected.
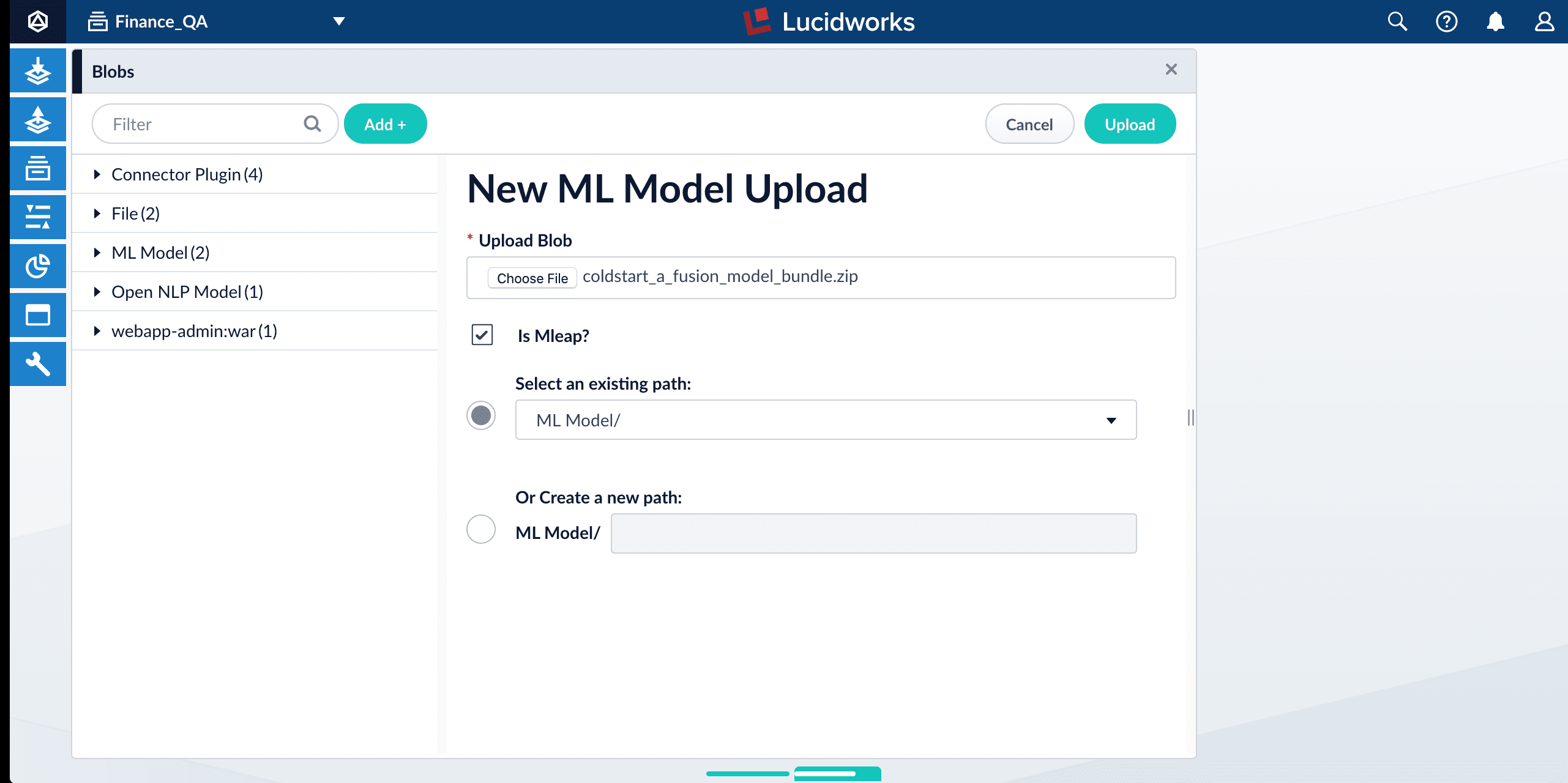 5. Click **Upload**.
5. Click **Upload**.
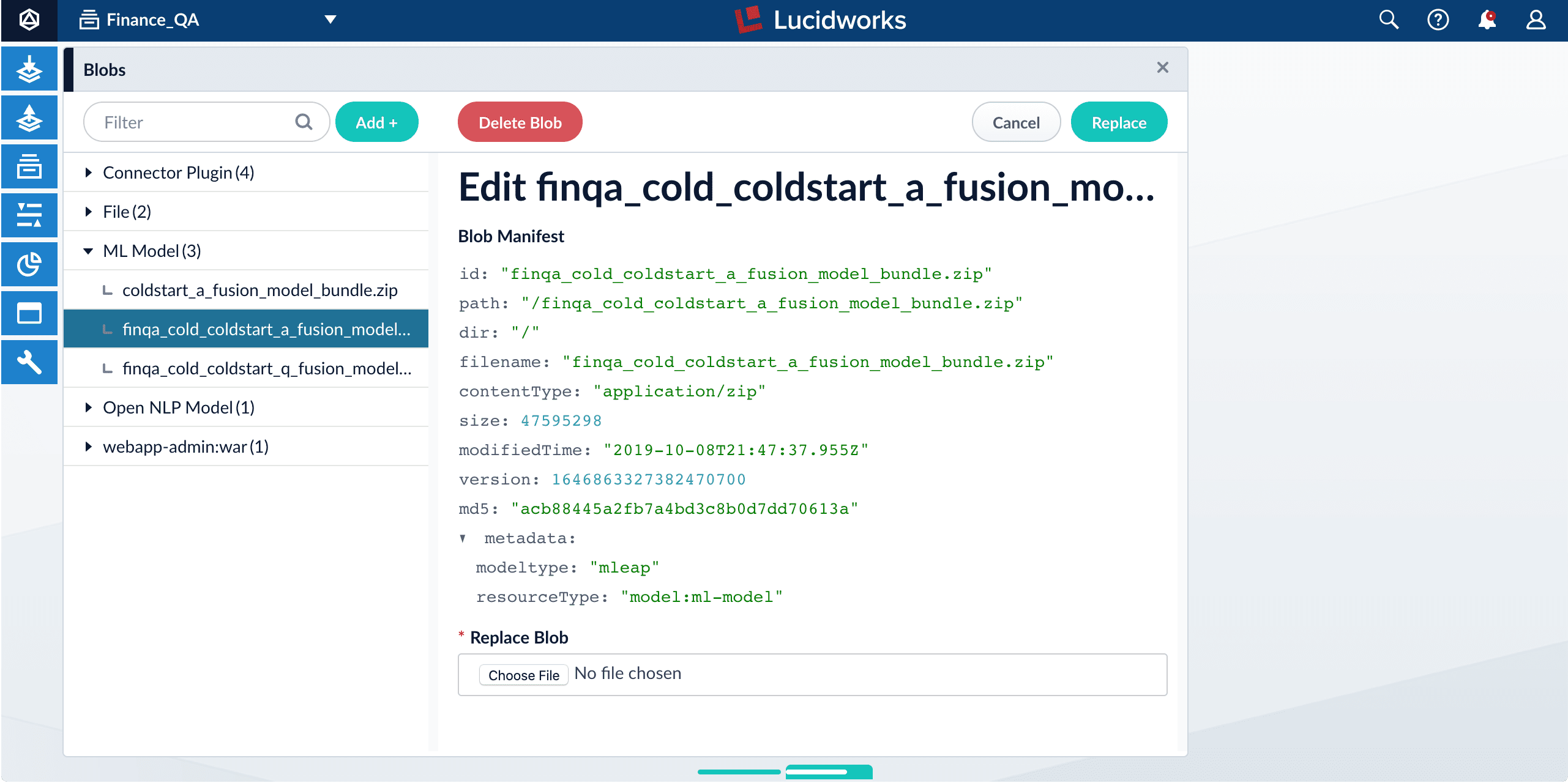 6. Repeat steps 2-5 for the other model file.
## Fusion configuration overview
* Fusion index pipeline
The index pipeline uses the trained model in `x_a_fusion_model_bundle.zip` to generate dense vectors for the documents to be indexed.
* Fusion query pipeline
The query pipeline uses the trained model in `x_q_fusion_model_bundle.zip` to generate dense vectors for incoming questions on the fly, then compare those with the indexed dense vectors for answers to find answers, or with the indexed dense vectors for historical questions to find similar questions.
Another option is to have two separate index stages, one for questions and another for answers. Then, at query time, two query stages compute query-to-question distance and query-to-answer distance. Both scores are ensembled into a final similarity score. The two options are illustrated in [Pipeline setup examples](#pipeline-setup-examples).
## How to configure the default pipelines
If you have an AI license, then the following default index and query pipelines are included in any newly-created Fusion app:
| Default index pipelines | Default query pipelines |
| ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `question-answering`: For encoding one field. | `question-answering`: Calculates vectors distances between an encoded query and one document vector field. Should be used together with `question-answering` index pipeline. |
| `question-answering-dual-fields`: For encoding two fields (question and answer pairs, for example). See [Configure the index pipeline](#configure-the-index-pipeline) below. | `question-answering-dual-fields`: Calculates vectors distances between an encoded query and two document vector fields. After that, scores are ensembled. Should be used together with the `question-answering-dual-fields` index pipeline. See [Configure the query pipeline](#configure-the-query-pipeline) below. |
### Configure the index pipeline
6. Repeat steps 2-5 for the other model file.
## Fusion configuration overview
* Fusion index pipeline
The index pipeline uses the trained model in `x_a_fusion_model_bundle.zip` to generate dense vectors for the documents to be indexed.
* Fusion query pipeline
The query pipeline uses the trained model in `x_q_fusion_model_bundle.zip` to generate dense vectors for incoming questions on the fly, then compare those with the indexed dense vectors for answers to find answers, or with the indexed dense vectors for historical questions to find similar questions.
Another option is to have two separate index stages, one for questions and another for answers. Then, at query time, two query stages compute query-to-question distance and query-to-answer distance. Both scores are ensembled into a final similarity score. The two options are illustrated in [Pipeline setup examples](#pipeline-setup-examples).
## How to configure the default pipelines
If you have an AI license, then the following default index and query pipelines are included in any newly-created Fusion app:
| Default index pipelines | Default query pipelines |
| ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `question-answering`: For encoding one field. | `question-answering`: Calculates vectors distances between an encoded query and one document vector field. Should be used together with `question-answering` index pipeline. |
| `question-answering-dual-fields`: For encoding two fields (question and answer pairs, for example). See [Configure the index pipeline](#configure-the-index-pipeline) below. | `question-answering-dual-fields`: Calculates vectors distances between an encoded query and two document vector fields. After that, scores are ensembled. Should be used together with the `question-answering-dual-fields` index pipeline. See [Configure the query pipeline](#configure-the-query-pipeline) below. |
### Configure the index pipeline
 1. Open the Index Workbench.
2. Load or create your datasource using the default question-answering index pipeline.
3. In the [TensorFlow Deep Encoding stage](/docs/4/fusion-ai/reference/index-pipeline-stages/tensorflow-deep-encoding-index-stage), change the value of **TensorFlow Deep Learning Encoder Model ID** to the model ID of the `x_a_fusion_model_bundle.zip` model that was uploaded to the blob store.
1. Open the Index Workbench.
2. Load or create your datasource using the default question-answering index pipeline.
3. In the [TensorFlow Deep Encoding stage](/docs/4/fusion-ai/reference/index-pipeline-stages/tensorflow-deep-encoding-index-stage), change the value of **TensorFlow Deep Learning Encoder Model ID** to the model ID of the `x_a_fusion_model_bundle.zip` model that was uploaded to the blob store.
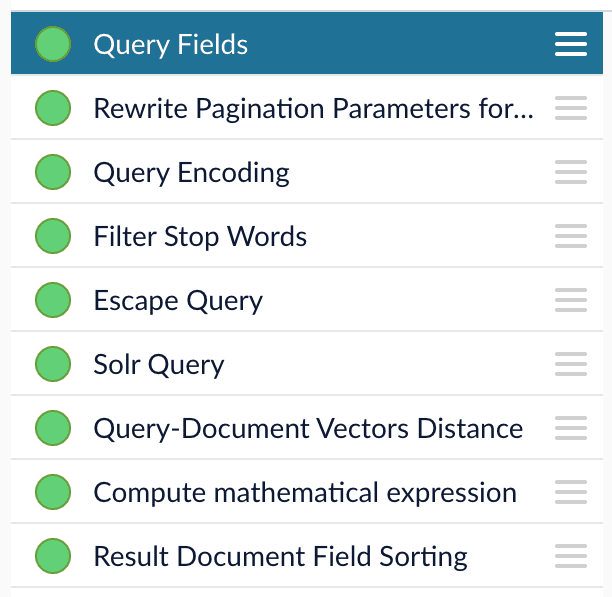 1. Open the Query Workbench.
2. Load or create your datasource using one of the default question-answering query pipelines.
3. In the [Query Fields stage](/docs/4/fusion-server/reference/pipeline-stages/query/search-fields-query-stage), update **Return Fields** to return additional fields that should be displayed with each answer, such as fields corresponding to title, text, or ID.\
It is recommended that you remove the asterisk (`*`) field and specify each individual field you want to return, as returning too many fields will affect runtime performance.\
Do not remove `compressed_document_vector_s`, `document_clusters_ss`, and `score` as these fields are necessary for later stages
4. In the [TensorFlow Deep Encoding stage](/docs/4/fusion-ai/reference/query-pipeline-stages/tensorflow-deep-encoding-query-stage), change **TensorFlow Deep Learning Encoder Model ID** value to the model ID of the `x_q_fusion_model_bundle.zip` model that was uploaded to the blob store.
1. Open the Query Workbench.
2. Load or create your datasource using one of the default question-answering query pipelines.
3. In the [Query Fields stage](/docs/4/fusion-server/reference/pipeline-stages/query/search-fields-query-stage), update **Return Fields** to return additional fields that should be displayed with each answer, such as fields corresponding to title, text, or ID.\
It is recommended that you remove the asterisk (`*`) field and specify each individual field you want to return, as returning too many fields will affect runtime performance.\
Do not remove `compressed_document_vector_s`, `document_clusters_ss`, and `score` as these fields are necessary for later stages
4. In the [TensorFlow Deep Encoding stage](/docs/4/fusion-ai/reference/query-pipeline-stages/tensorflow-deep-encoding-query-stage), change **TensorFlow Deep Learning Encoder Model ID** value to the model ID of the `x_q_fusion_model_bundle.zip` model that was uploaded to the blob store.