> ## Documentation Index
> Fetch the complete documentation index at: https://doc.lucidworks.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Default Signals Index Pipeline
export const LwTemplate = ({title = "Key questions to get you started", icon = "sparkles", cta = "Powered by Agent Studio", linkHref = "https://lucidworks.com/demo/?utm_source=docs&utm_medium=referral&utm_campaign=docs_cta_ai"}) => {
const [isLoaded, setIsLoaded] = useState(false);
useEffect(() => {
const timer = setTimeout(() => {
setIsLoaded(true);
}, 500);
return () => clearTimeout(timer);
}, []);
return
{isLoaded && `
}} />}
Powered by Lucidworks Agent Studio
;
};
[localhost link]: http://localhost:3000/docs/4/fusion-ai/concepts/signals-and-aggregations/signals/default-index-pipeline
[mintlify link]: https://doc.lucidworks.com/docs/4/fusion-ai/concepts/signals-and-aggregations/signals/default-index-pipeline
[old doc.lw link]: https://doc.lucidworks.com/fusion-ai/4.2/470
When indexing signals, Fusion uses a default index pipeline named `_signals_ingest` unless you specify a different index pipeline.
The `_signals_ingest` index pipeline has five stages:
1. [Format Signals stage](/docs/4/fusion-ai/reference/index-pipeline-stages/signal-formatter-index-stage)
2. [Field Mapping stage](/docs/4/fusion-server/reference/pipeline-stages/indexing/field-mapper-index-stage)
3. [GeoIP Lookup stage](/docs/4/fusion-server/reference/pipeline-stages/indexing/geoip-lookup-index-stage)
4. [Solr Indexer stage](/docs/4/fusion-server/reference/pipeline-stages/indexing/solr-indexer-stage)
5. Update `has_clicks` flag stage\
The Update `has_clicks` flag stage is an instance of the [Update Related Document stage](/docs/4/fusion-server/reference/pipeline-stages/indexing/update-related-document-index-stage) that updates the `has_clicks` flag to "true" on an existing request signal after the first click signal is processed for the request.
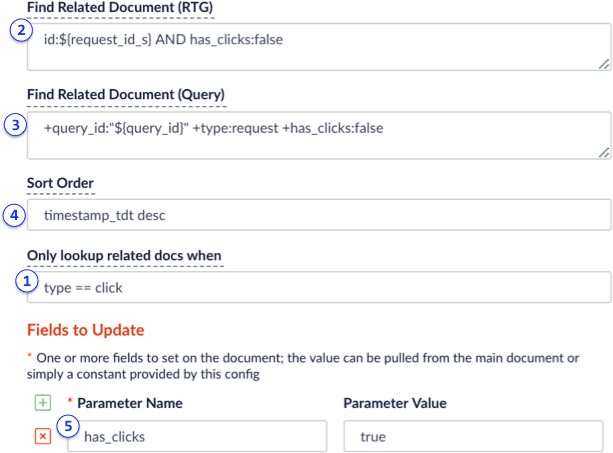
The update stage works as follows:
1. When a click signal is encountered (type == click)
2. Look at the incoming click signal for a field named `request_id_s`, which gets set by the Format Signals stage using a distributed cache of recently processed request signals.\
If the `request_id_s` field is set, then send a real-time `GET` query to Solr to find a request signal with ID equal to the value of the `request_id_s` field on the click signal. To avoid re-updating request signals, the RTG query also filters on `has_clicks==false`, which avoids duplicate atomic updates on the same document in Solr. Real-time `GET` is used to avoid timing issues between a request signal being sent to Solr and when it gets committed. This prevents missing updates when clicks occur soon after the initial request signal is sent by the search app.
3. If the click signal does not have the `request_id_s` field set, then do a normal Solr lookup for the request signal using: `+query_id:"${query_id}" +type:request +has_clicks:false`. A click signal may not have a `request_id_s` if there is a cache miss in the distributed cache used by the Format Signals stage.
4. If the stage performs a normal query, there may be multiple request signals that have the same `query_id`. This is because the `query_id` is based on `session` + `query` + `filter`, so if a user sends the same `query` + `filter` during the same session, there will be multiple request signals with the same `query_id` value. Thus, the stage sorts to get the latest request signal to update.
5. If a related document is found (in this case a request signal), then the stage updates the `has_clicks` field to true and performs an atomic update in Solr.
This stage performs its work in a background thread, so it does not impact the indexing performance of the click signal.
 The update stage works as follows:
1. When a click signal is encountered (type == click)
2. Look at the incoming click signal for a field named `request_id_s`, which gets set by the Format Signals stage using a distributed cache of recently processed request signals.\
If the `request_id_s` field is set, then send a real-time `GET` query to Solr to find a request signal with ID equal to the value of the `request_id_s` field on the click signal. To avoid re-updating request signals, the RTG query also filters on `has_clicks==false`, which avoids duplicate atomic updates on the same document in Solr. Real-time `GET` is used to avoid timing issues between a request signal being sent to Solr and when it gets committed. This prevents missing updates when clicks occur soon after the initial request signal is sent by the search app.
3. If the click signal does not have the `request_id_s` field set, then do a normal Solr lookup for the request signal using: `+query_id:"${query_id}" +type:request +has_clicks:false`. A click signal may not have a `request_id_s` if there is a cache miss in the distributed cache used by the Format Signals stage.
4. If the stage performs a normal query, there may be multiple request signals that have the same `query_id`. This is because the `query_id` is based on `session` + `query` + `filter`, so if a user sends the same `query` + `filter` during the same session, there will be multiple request signals with the same `query_id` value. Thus, the stage sorts to get the latest request signal to update.
5. If a related document is found (in this case a request signal), then the stage updates the `has_clicks` field to true and performs an atomic update in Solr.
This stage performs its work in a background thread, so it does not impact the indexing performance of the click signal.
The update stage works as follows:
1. When a click signal is encountered (type == click)
2. Look at the incoming click signal for a field named `request_id_s`, which gets set by the Format Signals stage using a distributed cache of recently processed request signals.\
If the `request_id_s` field is set, then send a real-time `GET` query to Solr to find a request signal with ID equal to the value of the `request_id_s` field on the click signal. To avoid re-updating request signals, the RTG query also filters on `has_clicks==false`, which avoids duplicate atomic updates on the same document in Solr. Real-time `GET` is used to avoid timing issues between a request signal being sent to Solr and when it gets committed. This prevents missing updates when clicks occur soon after the initial request signal is sent by the search app.
3. If the click signal does not have the `request_id_s` field set, then do a normal Solr lookup for the request signal using: `+query_id:"${query_id}" +type:request +has_clicks:false`. A click signal may not have a `request_id_s` if there is a cache miss in the distributed cache used by the Format Signals stage.
4. If the stage performs a normal query, there may be multiple request signals that have the same `query_id`. This is because the `query_id` is based on `session` + `query` + `filter`, so if a user sends the same `query` + `filter` during the same session, there will be multiple request signals with the same `query_id` value. Thus, the stage sorts to get the latest request signal to update.
5. If a related document is found (in this case a request signal), then the stage updates the `has_clicks` field to true and performs an atomic update in Solr.
This stage performs its work in a background thread, so it does not impact the indexing performance of the click signal.